时间轮算法

Netty时间轮
构造方法
1 | HashedWheelTimer timer = new HashedWheelTimer( |
负责执行定时任务的work线程~~~~默认~~~~是一个jvm的守护线程(是不是守护线程,取决你传入的ThreadFactory)
~~ 这意味着当 JVM 中只剩下这个线程时,进程会自动退出,不会阻止 JVM 停止。 ~~
1 | HashedWheelTimer timer = new HashedWheelTimer(); // 默认使用守护线程 |
1 | private static class DefaultThreadFactory implements ThreadFactory { |
市面已有的定时任务框架
java timer
querz
xxljob
powerjob
后两种算是比较大的了,
线程池参数设置
我自己电脑是 24核

如果设置的核心线程数>24 处理耗时都是差不多的
tomcat线程池默认核心线程数配置也是直接干到200的,tomcat线程池可以设置,那普通
线程池也是可以这么设置的,毕竟两者都是差不多的,只不过执行流程不太一样,普通线程池核心线程数满了,它是先入队列,队列满了再做一个非核心线程的扩充,知道达到最大线程数再触发拒绝策略。像tomcat的核心线程池,它最小是10,最大是200,它是当线程数超过10就会直接创建新的线程,达到最大线程数再入队,最后再触发拒绝策略。这两者的差别只有创建新线程树的差别。所以普通线程池和tomcat线程池就可以设置一个200的核心线程数了。
而我之前看八股的时候也是有了解到网上说核心线程数的设置要n+1 或者2n嘛,但当时我结合tomcat线程池的参数设置,就感觉怪怪的。然后有去疯狂谷歌搜索,像知道n+1和2n的说法来自于哪里,它其实是源于2006出版的java并发编程这本书,它里面就明确地提供了这个公式,就是线程池的线程树==cpu的核心数*cpu的利用率 *(1+cpu等待时间/cpu的计算时间)。然后我们假设CPU的利用率是100%,那么在CPU密集型场景下,,那么等待时间几乎为0,所以线程池的线程数为n,然后+1的话就是为了 说防止某线程假死了or暂停,增加一个冗余线程可以处理任务。如果是IO密集型的话,那他们就假设cpu等待时间/cpu的计算=1的。那么括弧里就等于2,那么结果自然就是2n。
然后一个就是为什么可以设置这么高
了解到因为长久以来一个一贯的说法就是
上下文切换回带来cpu的控制损耗。但其实这个说法是源自于1961年,有时代的局限性
2000左右的cpu上下文切换大概是5-10微妙,而当代cpu的上下文切换就只有1-3微妙。并且随着cpu超线程的发展,cpu核心数动不动就是64c 128c,除非是极端情况,比如高并发情况下,有几十万个线程正在切换,否则按照我们tomcat一般都是200个线程,甚至1000,2000的配置。这个损耗几乎是不计的。
像IO密集型的话,受限的其实是外部环境,比如数据库连接池的问题
所以如果是
还有就是个人感觉如果是这样的话,之前看过的一篇美团的关于动态线程池的技术博客,其实意义也不算大了,毕竟队列长和核心线程数并无直接关系,IO密集型的往大了调是没关事的,cpu密集型也是,毕竟怎么调大都没用,上下文损耗几乎忽略不计。
如果是生产环境的话,多个接口的话,可能会有线上其他任务抢占cpu调度的场景。那估计可能就会影响了。不过对于高并发服务器来说,其实在上面部署线程池其实是不合适的,IO密集型瓶计不在你,cpu密集型又影响其他。我个人感觉这种场景下MQ和调度任务是替代线程池的最好方案。
目前是根据一个经验值,核心线程数100,队列大小不限制
大概分析了每个线程要完成的工作,都会存在一些IO操作
根据机器2核4G的配置,所以给出一个经验值100
线程监控
beforeExecute()
重试纪元
afterExecute() 做重试逻辑,重试一定次数就报警
项目难点/亮点
整体流程
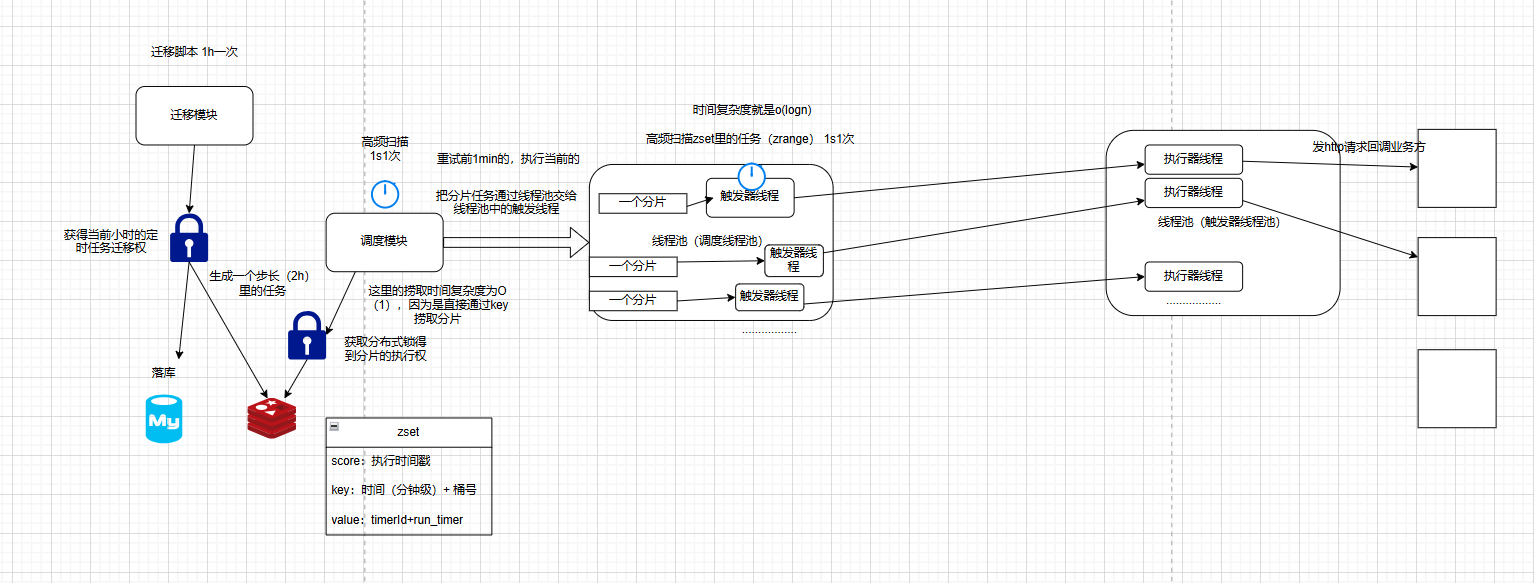
项目难点我觉得是如何实现一个高精准和高负载,就是说在大任务量的情况如何做到秒级触发。基于这点出发,我当时就在整体的架构设计和存储设计 这两方面下了比较大的功夫。
对于存储设计来说,一开始其实是单单采用MySQL来存储,定时器开启后生成任务就直接放到mysql里。但这样的话
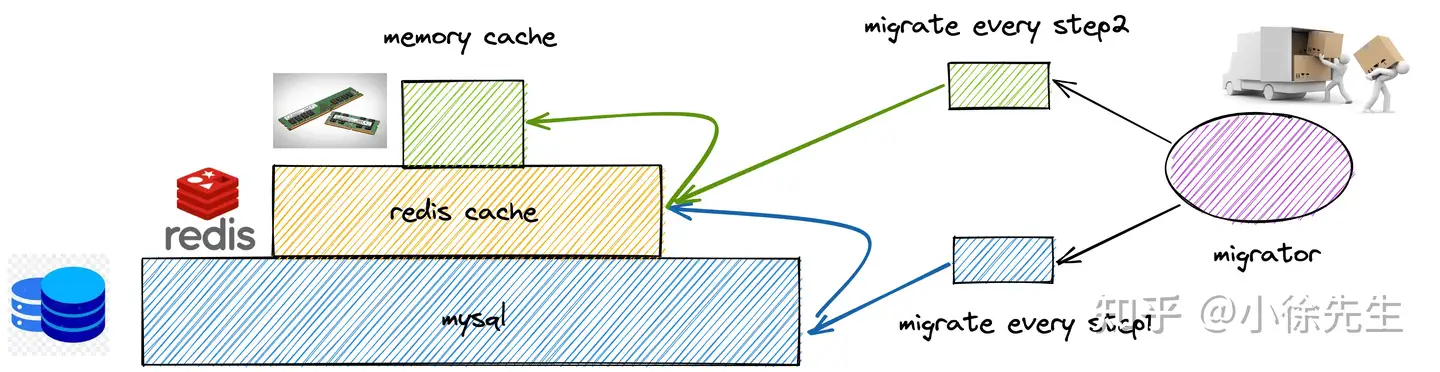
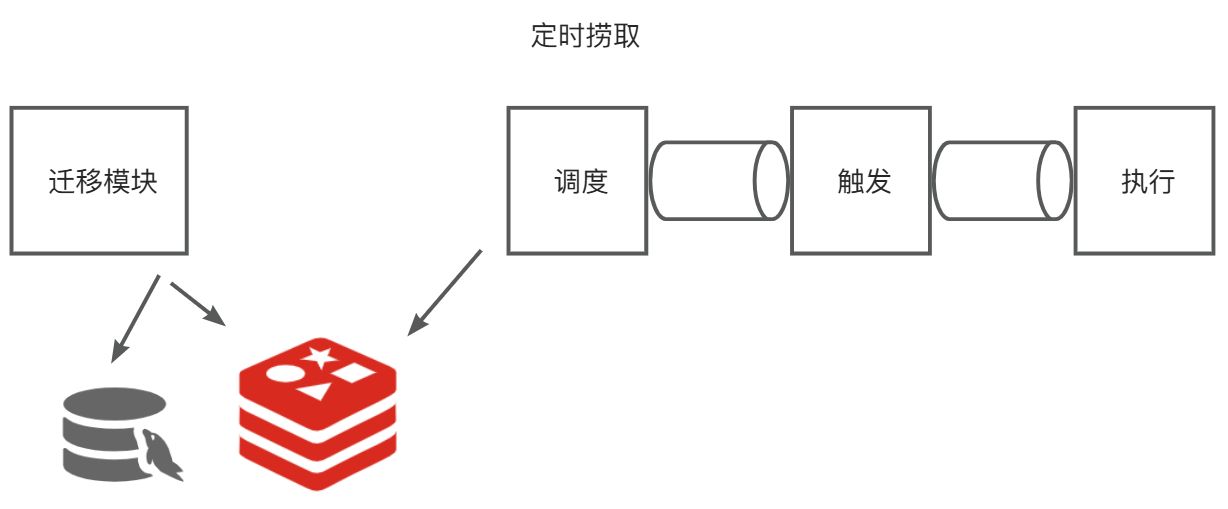
还有这个架构设计。项目之初,我为了解耦各个步骤,就把整个定时任务执行流程给解耦,就把它按照功能拆分成了迁移模块,调度模块,触发模块,执行模块。迁移模块就是在用户开启定时器后根据定时器的配置将任务生成后持久化到任务表中,还有redis。调度模块就是轮询从redis里捞任务片zset,然后交给触发模块去监控这个任务啥时候执行,到点执行了就调用执行模块去回调业务方提供的回调接口,这个回调接口就是具体执行任务的。一开始各个模块之间通信是通过线程池来进行的。但线程池无法实现核心流程的真正解耦以及纵向架构扩展,虽然线程池时进程内的通信,相对于消息队列而言少了一些网络IO,在执行耗时上会有更佳的表现,但这样服务的可用性和整体性能就没那么高了。所以后面架构就打算用消息队列,但我一开始的目标是尽可能的减少外部依赖,那像Rabbitmq,rocketmq对于本项目来说就比较重了。所以就采用了redis的消息队列,本身我们项目就需要redis
分布式定时器性能?
测试环境:2c2g服务器
因为目前线上就只有这么一台了,所以就只压测了1000笔,2000笔定时器
1000笔
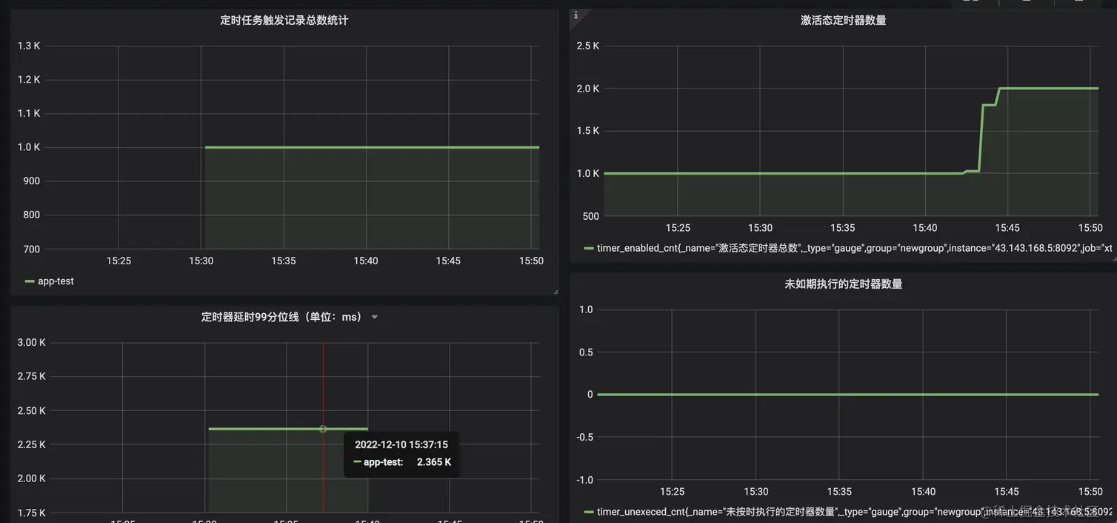
(1)成功率 100% 1000笔定时器(同一时刻有1000笔定时任务触发)全部执行,未发生遗漏; (2)延时指标难看 延时 99 分位线(p99)高达 2.4 s. 即有99%的定时任务延迟低于99s,有1%的定时任务高于99s
根据那个火焰图,可以看出来性能瓶颈主要是因为redis和MySQL性能激增导致的
怎么优化?
引入连接池,避免重复创建销毁连接,Jedis,Druid连接池
怎么查看性能的,使用了aysnc-profile
https://juejin.cn/post/6844904016443342861
2000笔
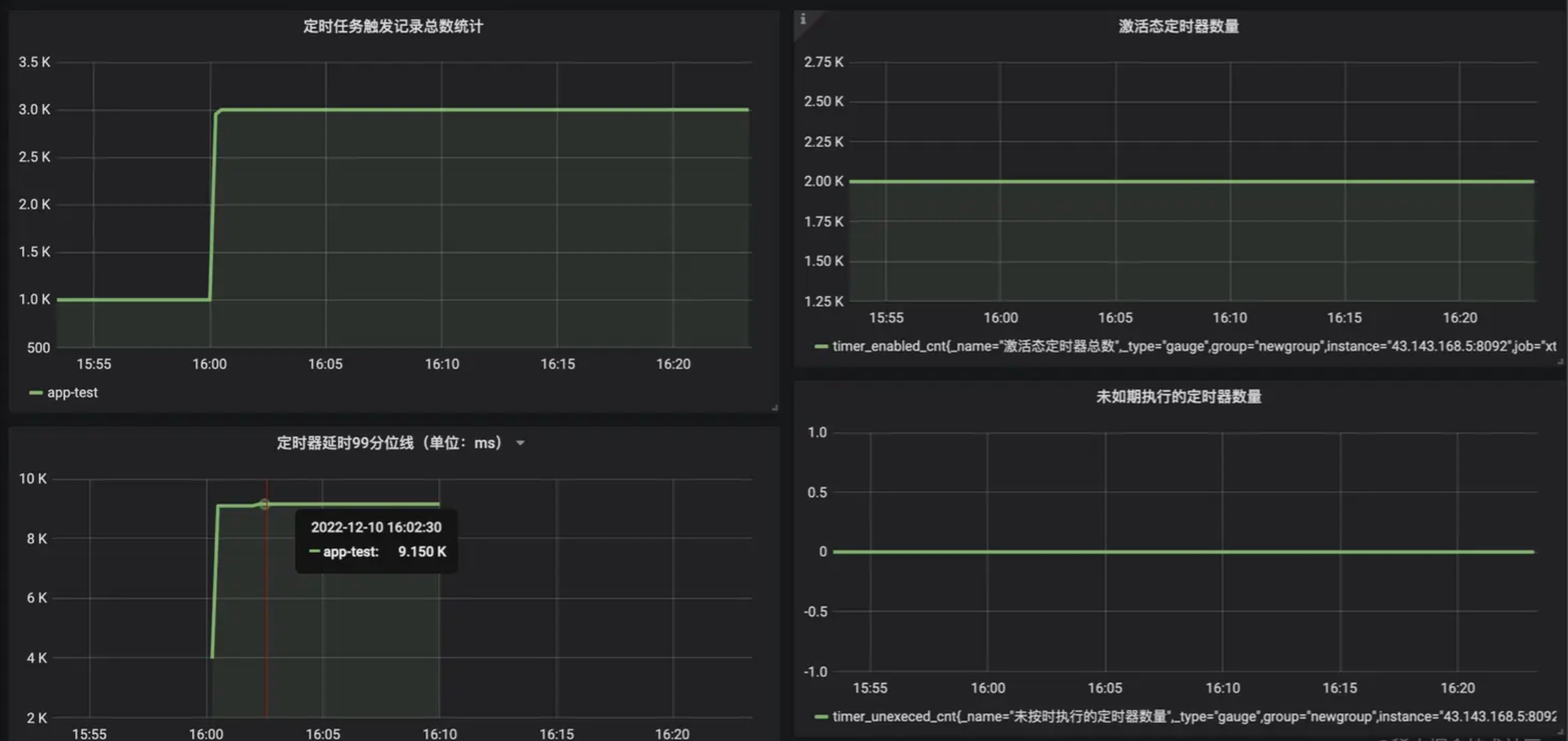
(1)成功率 100% 2000笔定时器全部执行,未发生遗漏; (2)延时指标难看 延时 99 分位线飙升至 9.1 s.
性能瓶颈也主要是redis和MySQL连接数激增导致的,配置不太行
MySQL,redis,服务都塞到一台服务器上
为什么做这个项目
这个主要是跟其他师兄吃饭聊天的时候,听说实验室项目组里搞了个体育馆预约系统,教室预约系统也是,需要预约结束后发送给用通知嘛,有这样的定时任务需求嘛。当时我就就想着能不能做一个通用模块,根据自己的想法去从0到1构想这么一个定时器项目,是一个很好锻炼自己项目设计能力、问题解决能力、编码能力的一个机会 。即使到时候没法上线啥的,也比现在的网上的一些商城,外卖这种项目写到简历上竞争力强。也是当做锻炼自己的项目能力了。
是自己实现的吗?
有去参考相应的技术博客文章,当时帮助最大的应该是
对项目的要求?
- 轻量级,成本低(依赖少)
- 与业务方 解耦
- 高负载,高精准(秒级)
- 代码简单
致敬
面试回答
自我介绍
平时你是怎么学习的
首先是通过视频入门,视频讲解一般比较生动,有即时反馈,跟着入门不会溜神
然后就是自己再把东西梳理一遍,看下是否有遗漏或者不清楚的点。
然后是关键的点,就是去各大社区平台看技术文章,例如阿里云、腾讯云、博客园或者是一些我觉得是宝藏博主的私人blog平台,还有像公众号的文章和书籍这些,都有看,我觉得看这些文章都是很有意思,广度和深度都很不错的学习方式
一般到了这里,我基本就是能比较完善的学习了,因为我看的文章确实挺广的,然后对于一些特殊的、有意思的东西,我会自己去做实验,比如MySQL里的锁,我就有专门去手动研究测试过。
因为我看的文章广度比较大嘛,所以可能出现有些地方说法不一致的地方,这时候我就得弄清楚到底哪个是真相,这时候我会再去扩大信息来源的广度和深度,不断发掘知识,这里也会结合gpt来进行问,如果感觉还是两种说法都有,搞不清楚,我就启动我的大招,去翻源码了,我看源码的步骤是这样的,我会去问gpt,我这块内容的源码,具体是在哪,然后才去看,比如我记得用源码解决的部分就有这些情况:
- 一个是RocketMQ的消息重试那块,我们看到的常见的说法是,消息如果消费者那边没响应的话,broker会重复投递消息,会重复投递16次,但是我在一个地方看到的说法又是,如果是在顺序消费的情况下,投递次数超过了,就会丢弃这次的消息到私信队列,然后消费后面的消息,看到这里,我就想,这不就破坏消息顺序消费了吗,比如如果消息顺序是消息1,消息2这样子,消息1重复16次投递不出去,然后就跳过消息1,消费消息2,这就破坏我们说的顺序消息了啊,RocketMQ真的会这么设计吗。然后我就去翻源码进行查看,发现他在源码里面,重复次数其实设置的是-1,并不是16,然后这个字段上面有注释,注释说的是,在并发消费下,-1意味着16,在顺序消费下,-1意味着Integer.MAX_VALUE,然后我去具体的使用上看了,发现确实是会根据不同场景下是不同的重复投递次数的,那么在顺序消费下,其实他就是int的最大值,就是一直投递了,那其实就不会跳过这个消息了,这其实就是通过源码来解决我看过的文章发生冲突的一个例子吧。
- 还有一个就是我看《深入理解Java虚拟机》上面说,HotSpot新生代晋升老年代的年龄是15岁,但是如果Survivor中相同年龄所有对象大小总和大于Survivor一半,年龄大于或等于该年龄的对象就可以直接进入老年代。但是我又是在其它地方看到了另一种说法,另一种说法是说动态年龄的判断是小于或等于某个年龄的所有对象大小大于总和的一半,那么新的阈值就被设置成这个年龄。那这里其实就是两种说法,我把这两种说法都问了gpt,并让他给出源码坐标,也去源码里面看了下,发现其实是后者说法是正确的,也就是《深入理解Java虚拟机》其实在这个问题上有错,这里其实也是比较惊讶的一点,因为这个书我看了两遍,感觉真的是写JVM非常好的一本书,但真的就是突然感觉还是不能尽信书吧。
- 还比如说我在学RocketMQ事务消息的时候,就感觉这样真的能保证数据一致吗,我就去考虑极端情况,例如本地事务提交了,但是commit消息还没发送出去,此时生产者又宕机了,那么MQ也反查不到事务信息,这时候会怎样,但是网上没搜到有文章讲这种极端情况,我就去看源码了解RocketMQ是怎么解决的,通过源码我看见,MQ会起一个线程每隔30s轮询一遍事务消息进行状态回查,如果回查次数大于等于最大次数也就是15次,那就会直接丢弃这个消息到一个topic叫TRANS_CHECK_MAXTIME_TOPIC的队列中。所以其实事务消息也并不一定是安全的,也有可能导致数据不一致,但是我当时又顺便看了下它的源码中回查状态的那部分,发现它其实通过生产者组id获取生产者组实例,然后轮询选择出具体的某个实例,来进行状态回查的,也就是回查的机器和发送事务消息的机器不一定是同一个,所以我们生产者组是可以部署集群来提高可用性进而解决这个事务消息可能产生的数据不一致问题的。