MySQL自增主键用完了会怎么样?怎么解决
自增主键分为两种,一种是显性的,一种是隐性的(row_id)。如果是显性的,那么就会报主键冲突错误,
如果是隐性的,下次申请ID的时候,得到的值会从0开始,然后继续开始自增,但这个时候会覆盖原有相同
row_id的数据
显性的一般是bigint,unsign
这样的话,肯定是自己显性指定主键ID,毕竟这样的话异常我们才能感知到的
真用完了怎么办?
1.脚本扫描没用到的主键,然后插入,但不推荐,会破坏其原有数据的连续性
2.将表里的久远数据归档(推荐)
3.使用UUID,UUID是128位,几乎不可能用完的,但不推荐,UUID作为主键ID容易造成页分裂,页合并
count
count(1) count() count(列名) 哪个性能高?
count(1)和count() 表示直接查询符合where条件的行数,而count(列名)表示查询的列名不为
空且符合where条件的行数。count(*)是要比count(1)性能高,因为它是标准语法,MySQL对它进行了
很多优化
count(*)的优化?
首先声明一点,优化的前提是使用count(*)时不带where和group by
- 对于myisam而言,因为它锁的粒度最小只有表锁,所以它不会有并发的行数据修改,故MySQL采用了一个字段进行存储它的行数
- 对于InnoDB而言,MySQL进行count(*) 时会选择一个最小非聚簇索引,因为count时他是不会关心你具体数据的,而非聚簇索引的叶子结点装的是主键ID,比聚簇索引小。所以建索引时,再建一个非聚簇索引也是必要的
count(列名)?
count(1)和count(*)只是扫描索引树,而count(列名)则需要进行全表扫描,如果列名不加索引
大数据量统计下,可以怎么优化count(*)
1.如果对count的精准要求不高,可以通过explain里的row代替
2.用一张表维护count,insert就+1,或者delete就 -1
3.用列式存储数据库,如click house
索引合并机制
数据库查询优化的一种手段,它就是说多个索引同时检索来提高查询效率,类似于我们开多线程
通过explain,我们可以清晰地看到用到了索引合并的标识 index_merge
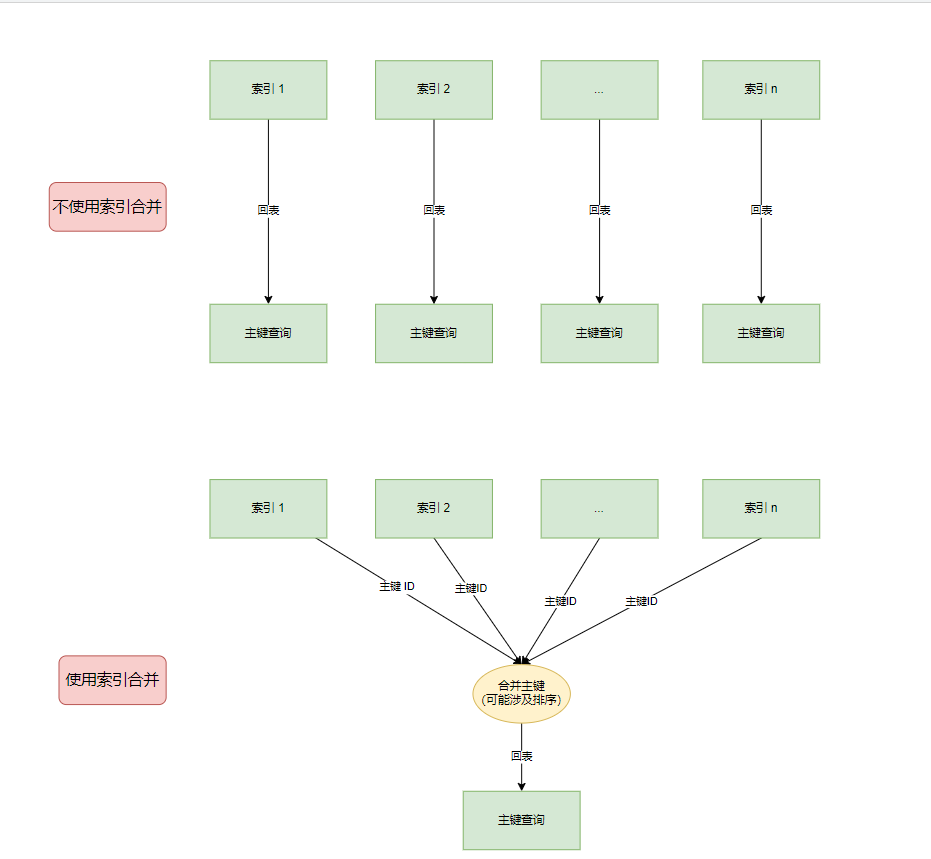
并且可以在extra 看到使用了哪种策略
using interset:
using union:
using sort_union:
索引覆盖
查询的字段被包含在了索引里,不需要回表了,这就是索引覆盖
为什么mysql索引结构要采用b+树
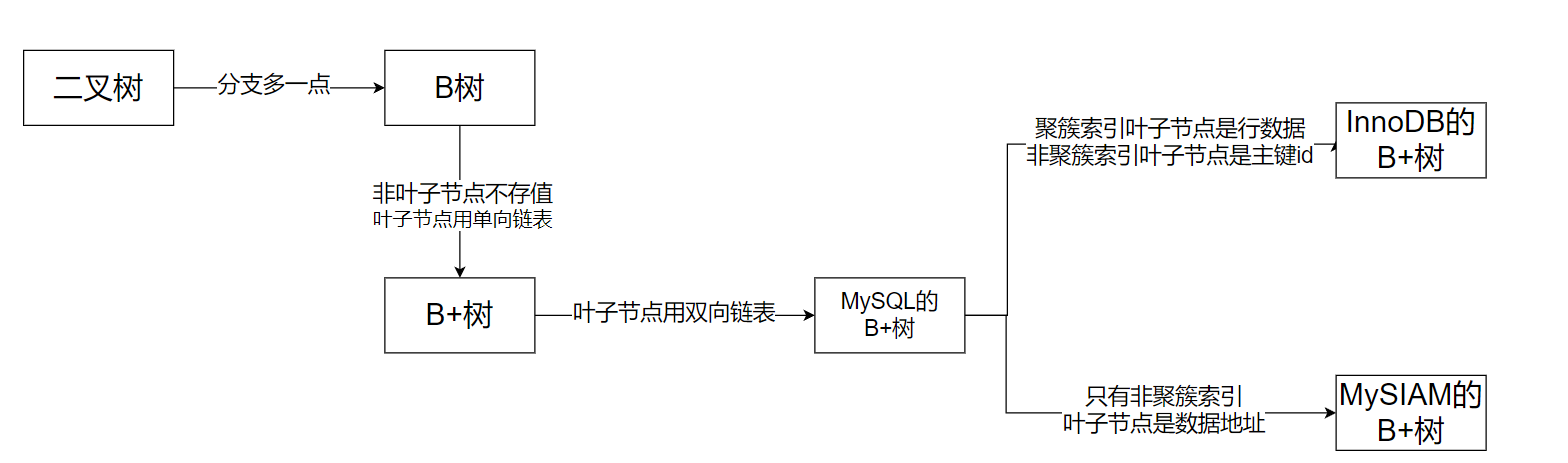
首先我们要明白采用它的目的,一定就是要时间复杂度尽可能地小,支持范围查询。前者无非就是树,跳表,Hash表。而hash索引不支持范围查询
为什么不用Hash?
不支持范围查询
为什么不用跳表?
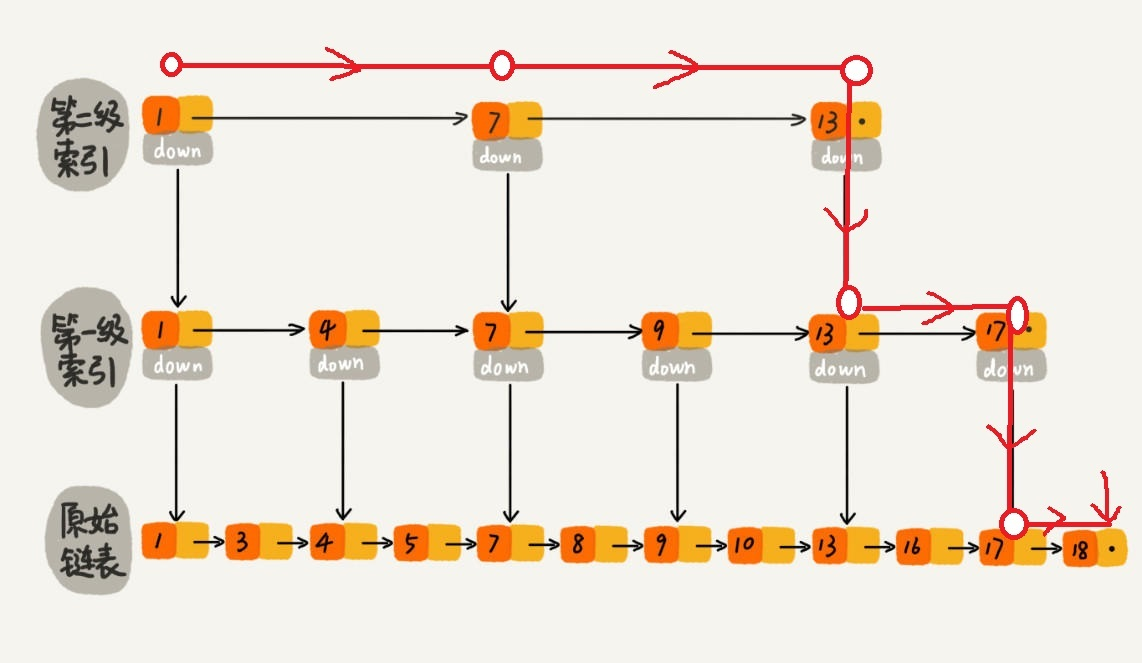
跳表是内存友好型,而b+树是磁盘友好型。b+树一般在磁盘里寻址三次足以,每次都会读取一个数据页,然
后在数据页进行二分查找
而跳表每次读取一个数据页节点都需要跳跃,而链表又是几万个节点,虽然是logn,但寻址次数明显是要比
b+树多,因为b+树的二分查找主要是在数据页中(已经读到内存中了,InnoDB是读到bufferpool,myisam
是读到 page cache),而跳表的二分查找就是在链表中,即磁盘中,而且索引之间的物理距离可能比较长
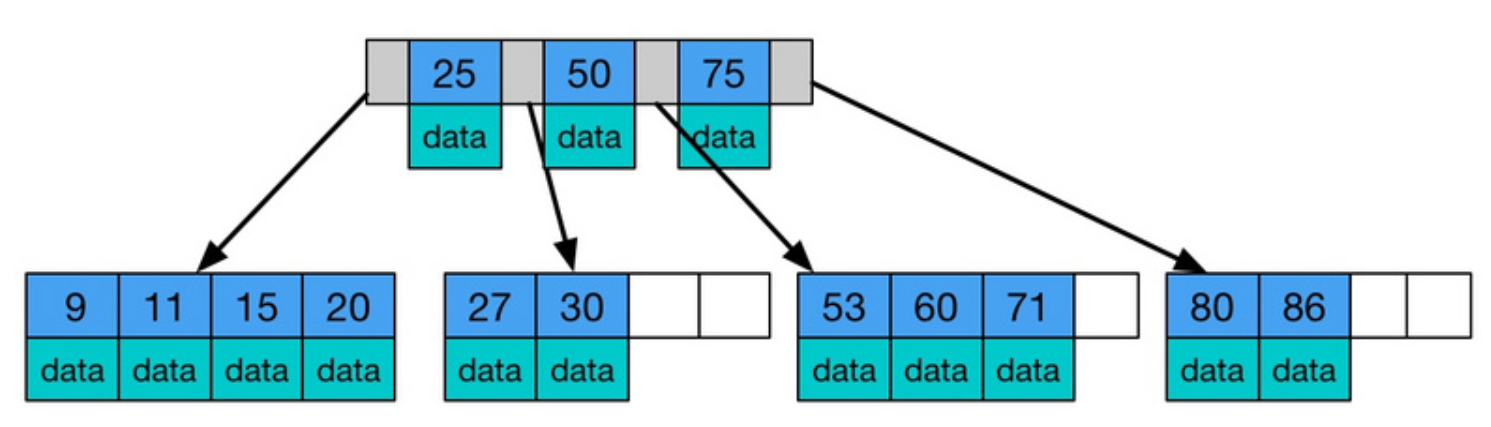
为什么不用b树?
b树的非叶子节点的v也会存数据,这导致一个页中存储的kv值会减少(因为一个页的大小是固定的),指针
就会表少,要同样保存大量数据,就得去增加树高,导致其性能降低。然后就是叶子节点之间是没有指针相连
的,对范围查询不是很友好,且叶子节点之间是无指针相连的,对范围查询不是很友好
为什么不用二叉树/红黑树?
二叉树层级过高,搜索效率偏低,百万数据约为20层
索引失效
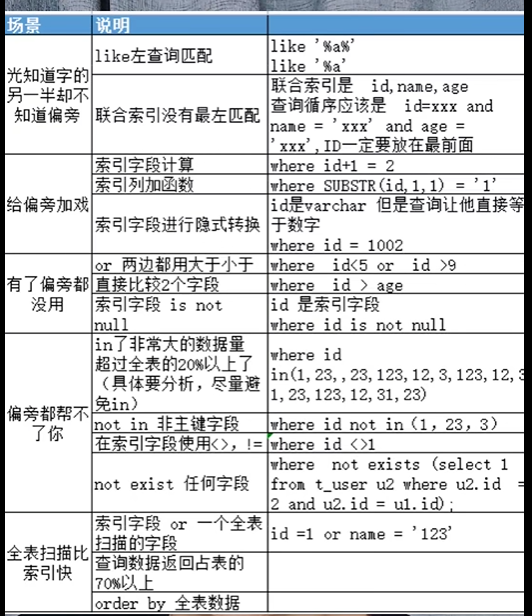
补:
%北%走索引的,但是%北%无法二分查找啊,这下索引就没卵用了,因为只会全扫
– 1.索引也是会全扫描的
– 2.mysql加载16k一页,全扫索引比全扫主键快很多,IO快,列差得很大,快很多,因为你拿数据拿得多啊,二级索引树就拿了ID+列名,你主键拿的是一行,即所有列的数据
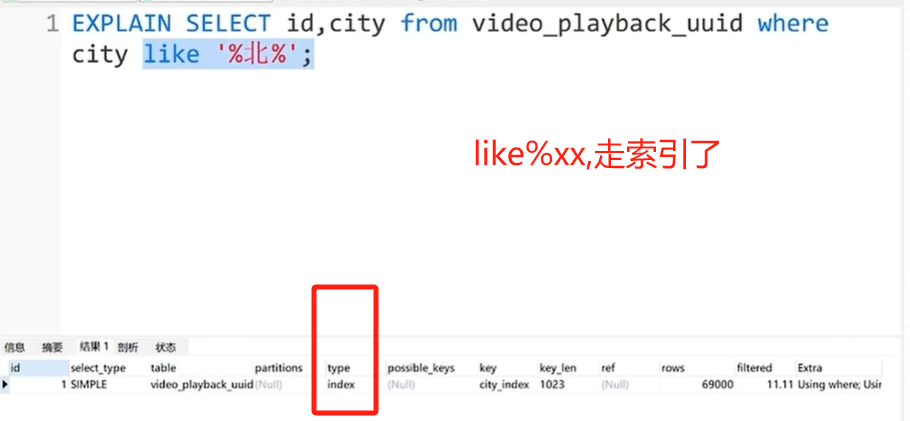
查询优化器

将SQL语句转成物理执行计划,并以最小化查询时间or资源消耗
工作流程
- 将SQL转成抽象语法树
2.重写查询:简化条件,合并子查询、消除冗余操作
3.根据模型评估执行计划,选择最小成本计划(选哪个索引)
4.将最优计划转换为可执行的指令集
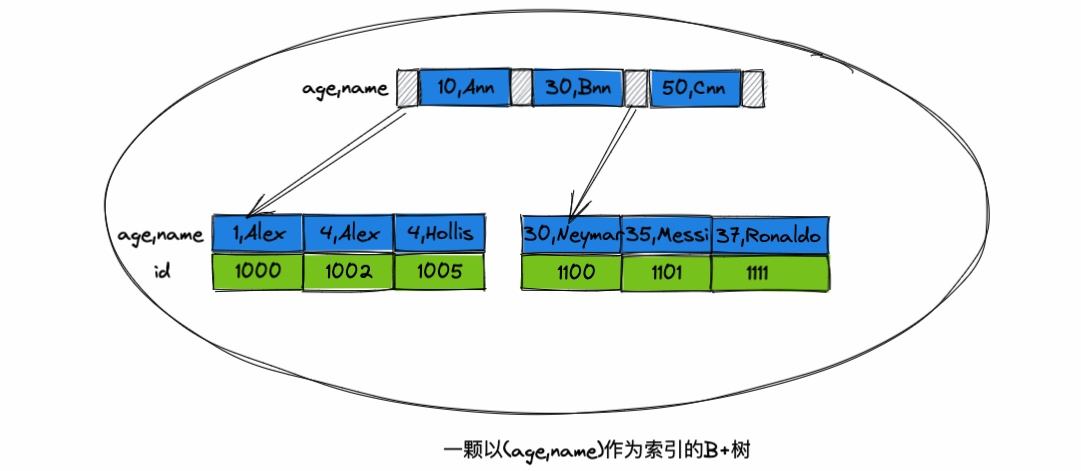
最左前缀原则
加锁算法?
MySQL/mysql-storage-engines/innodb/1.5.5.InnoDB锁——lock之不同SQL加锁分析.md at master · asdbex1078/MySQL
抛开隔离级别谈上锁都是耍流氓!
读未提交
- 增:插入数据后,给新插入的数据上<font style="color:#DF2A3F;">记录锁</font>,防止其它事务更改这条记录
- 删:需要获取到要删除的记录的<font style="color:#DF2A3F;">记录锁</font>,保证删除的时候其它事务没在使用这些数据,并保证删除后其它事务无法对这些数据进行操作
- 改:给需要更改的数据上<font style="color:#DF2A3F;">记录锁 </font>
- 查:任何读都不加锁
读已提交
- 增:插入数据后,给新插入的数据上<font style="color:#DF2A3F;">记录锁</font>,防止其它事务更改这条记录
- 删:需要获取到要删除的记录的<font style="color:#DF2A3F;">记录锁</font>,保证删除的时候其它事务没在使用这些数据,并保证删除后其它事务无法对这些数据进行操作
- 改:给需要更改的数据上<font style="color:#DF2A3F;">记录锁 </font>
- 查:快照读不加锁,当前读只加记录锁
可重复读
- 增:使用<font style="color:#DF2A3F;">插入意向锁</font>,进行插入,插入后给插入的数据上<font style="color:#DF2A3F;">记录锁</font>(隐式锁,其实这个记录锁不是这个时候上的)
- 删:使用<font style="color:#DF2A3F;">临键锁</font>,防止其它事务在删除的区间内插入数据
- 改:给需要更改的数据上<font style="color:#DF2A3F;">临键锁 </font>
- 查:快照读不加锁,当前读:加临键锁和间隙锁,唯一索引则加记录锁
序列化
- 增:使用<font style="color:#DF2A3F;">插入意向锁</font>,进行插入,插入后给插入的数据上<font style="color:#DF2A3F;">记录锁</font>(隐式锁,其实这个记录锁不是这个时候上的)
- 删:使用<font style="color:#DF2A3F;">临键锁</font>,防止其它事务在删除的区间内插入数据
- 改:给需要更改的数据上<font style="color:#DF2A3F;">临键锁</font>
- 查:普通查询自动变为select … lock in share mode,上<font style="color:#DF2A3F;">临键锁,锁间隙</font>! 唯一索引加记录锁
细节
锁的对象是索引,而不是记录
二级索引的记录加了排他锁,聚簇索引也会加对应的锁。
如果没有合适的索引,那么MySQL就会扫表来处理,那么表的每一行都会被锁定,从而阻塞其他用户对 表的所有插入
临键锁只存在于可重复读和串行化事务隔离级别下
MVCC只存在于读已提交和可重复读
next-key lock 是前开后闭((x,y])区间,而间隙锁是前开后开区间((x,y))
临键锁上锁的优化:
临键锁锁的是一个间隙以及一个间隙后面的行记录,锁粒度比较大,在一些情况下会对其进行一定优化
总结起来就是 在加间隙锁or记录锁能避免幻读的情况下,临键锁就会退化成记录or间隙
唯一索引等值查询:
当查询的记录存在时,定位到了在索引树上的位置,那么原先在扫描时加的临键锁就会退化成记录锁
当查询的记录不存在时,在索引树找到比它大的第一条记录时,那么临建锁就会退化成 间隙锁

唯一索引范围查询情况
唯一索引扫描索引树时,会对扫描到的每一个索引加临键锁,如果满足一些条件就有可能发生锁退化
非唯一索引等值查询

非唯一索引范围查询情况
临键锁无法进行退化
非索引扫描情况
每一条记录的索引上都会加 next-key 锁,这样就相当于锁住的全表**:****从负无穷到正无穷(全表记**
录 + 所有间隙)
以上加锁的机制都是围绕着如何避免幻读来展开的
ps:锁全表的数据(临建锁)时,那这时候往表的最后一行后插入数据会被阻塞吗。会的,锁到正无穷,如果插入头部,负无穷也会被锁住
MySQL只操作同一条记录,也会发生死锁吗?
会的。mysql锁的是索引,而不是记录。如果是根据二级索引查询(加锁查询orDML),那么它会
先获取二级索引上的锁,然后再去对主键索引上的锁。如果有两线程同时获取锁的顺序不一样了,
那么就会发生死锁
加锁原则:两个原则两个优化一个bug