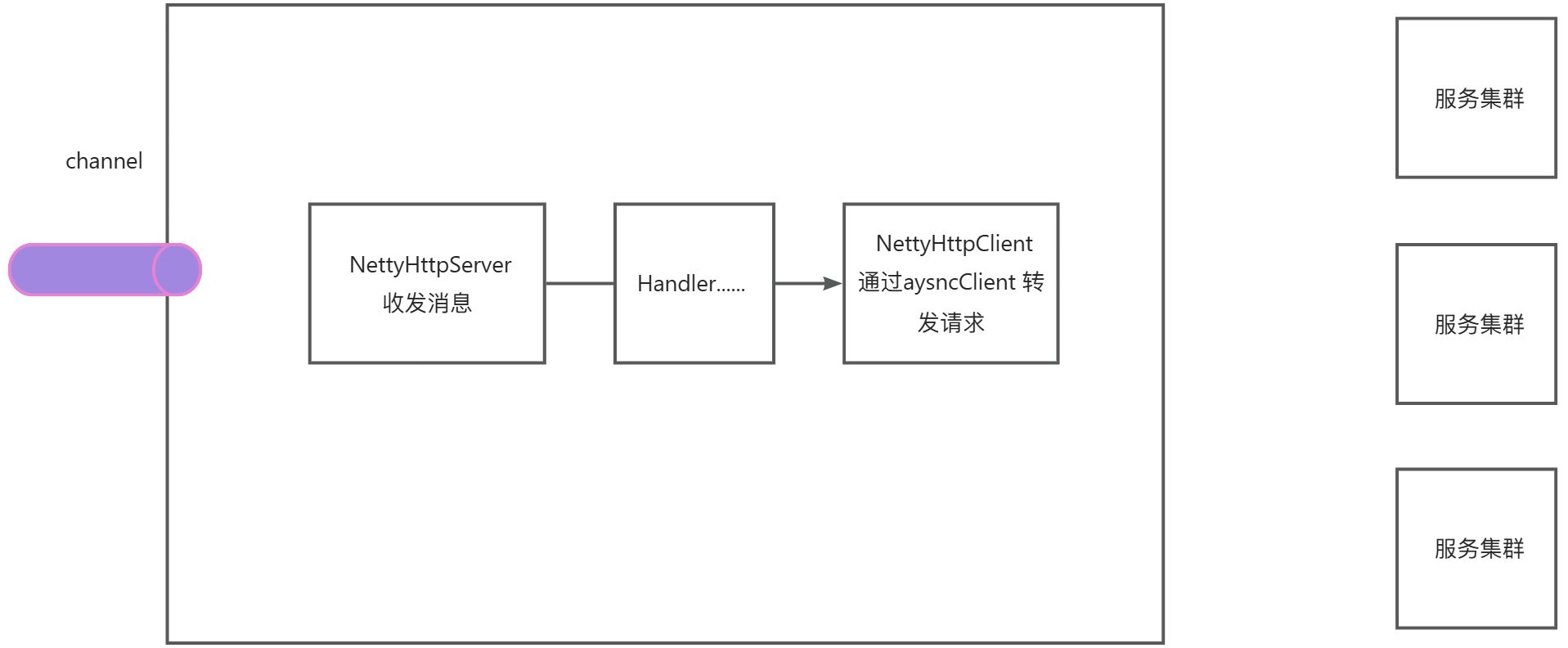
如何保证消息不丢
其实就只有一种,重试。我们不能保证100%不丢,还有不可能完全依靠中间件的可靠性。
kafka有哪些丢消息的场景?分别怎么处理
1.发消息可能会丢,失败重试
2.broker落盘可能丢,落盘默认是靠系统机制落盘,消息一开始是写入page cache。想要不丢那就配置
为立马刷盘,但性能就比较差
3.消费丢失,手动ack,一条条确认,但手动ack其实会有死循环,依靠人的功底
其实就只有一种,重试。我们不能保证100%不丢,还有不可能完全依靠中间件的可靠性。
kafka有哪些丢消息的场景?分别怎么处理
1.发消息可能会丢,失败重试
2.broker落盘可能丢,落盘默认是靠系统机制落盘,消息一开始是写入page cache。想要不丢那就配置
为立马刷盘,但性能就比较差
3.消费丢失,手动ack,一条条确认,但手动ack其实会有死循环,依靠人的功底
结合cc router 配置免费api,启动 ccr code
命令行
/init
caffeine ===》 Redis ==》 mysql
如何提高缓存命中率?
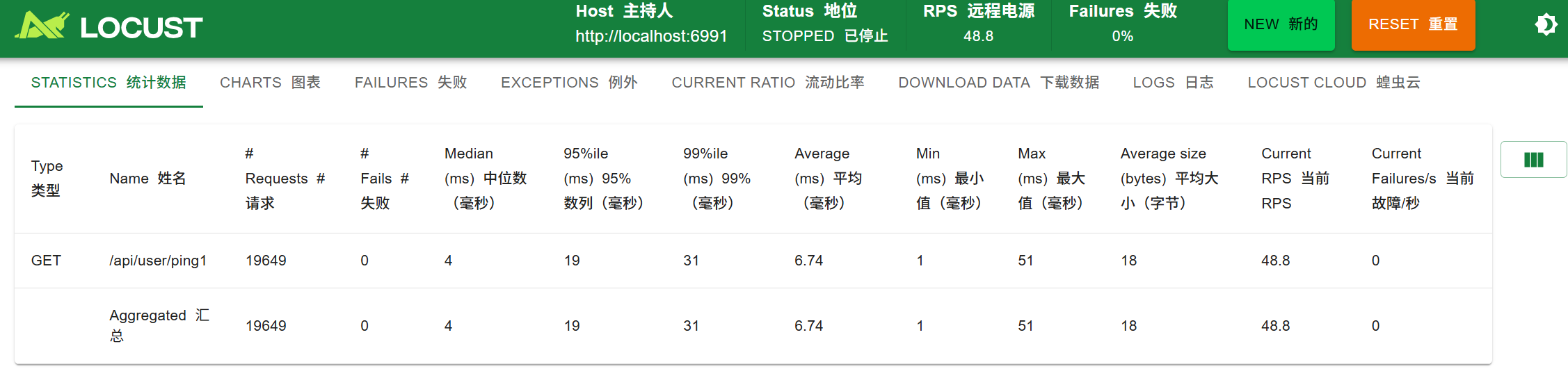
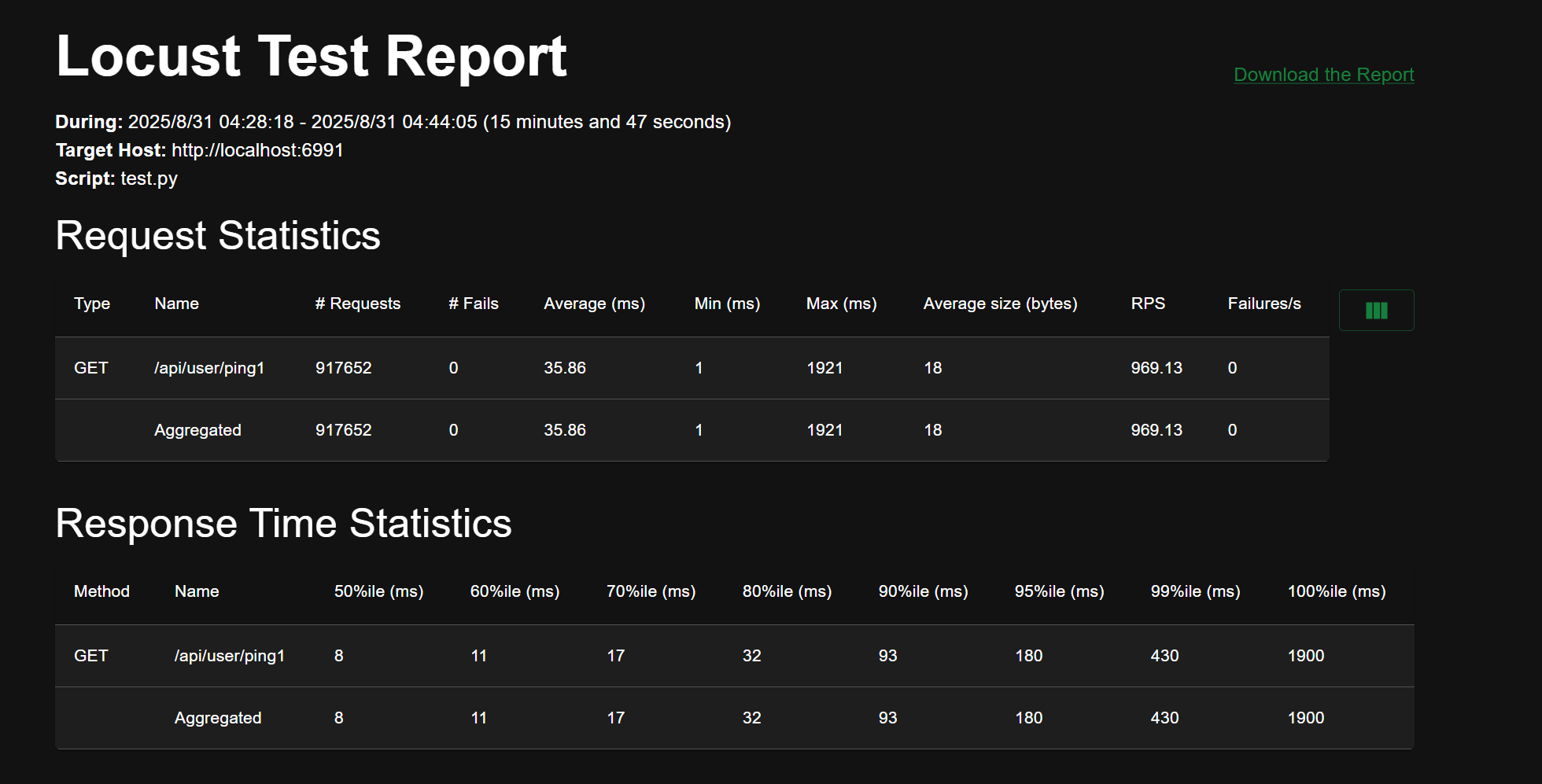
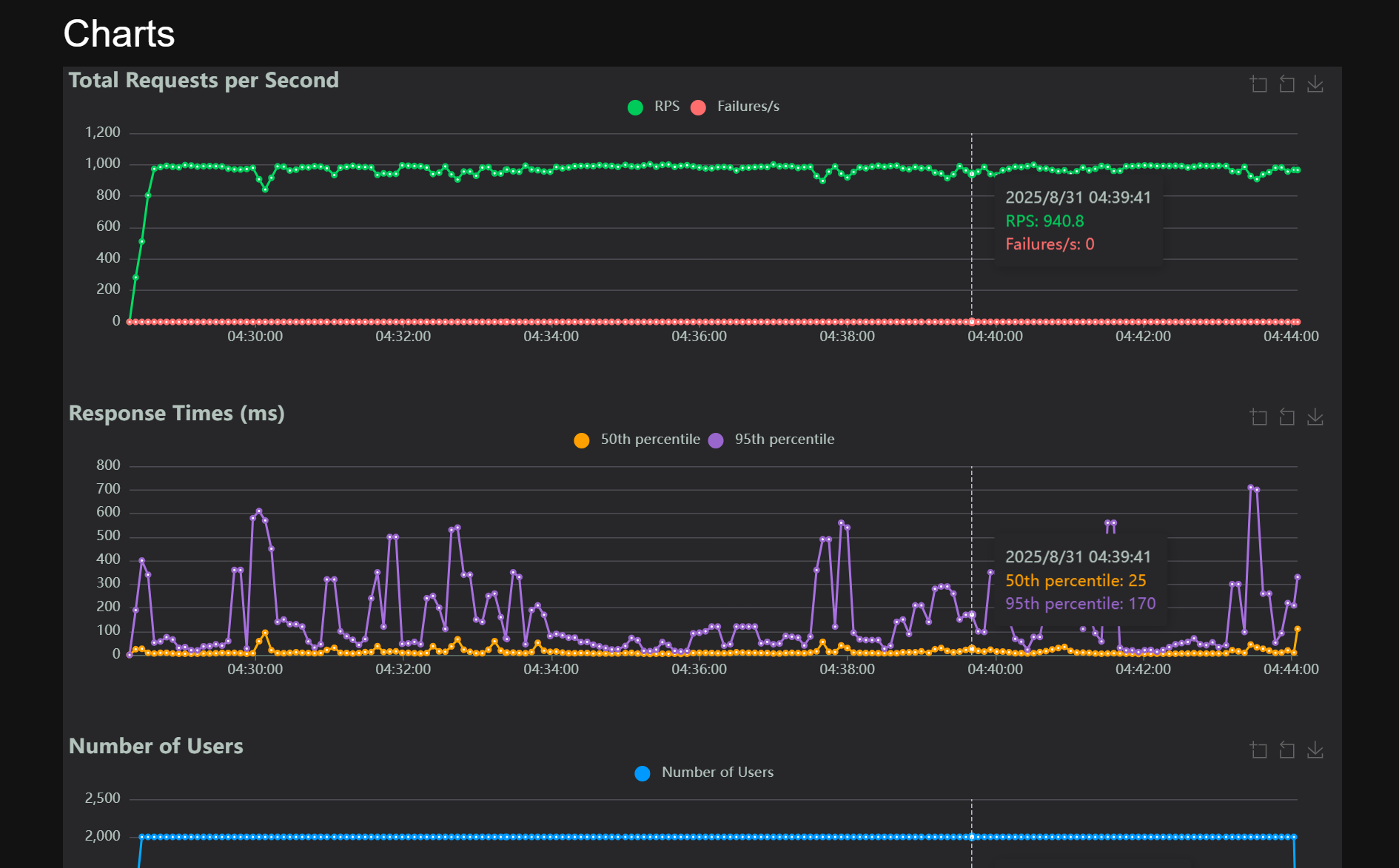
locust
https://blog.csdn.net/liuyunshengsir/article/details/145907880
压测记录
100 - 10
1 | 2025-08-31 03:55:00.474 WARN io.netty.channel.DefaultChannelPipeline :1152 default-netty-worker-nio-3-57 An exceptionCaught() event was fired, and it reached at the tail of the pipeline. It usually means the last handler in the pipeline did not handle the exception. |
2000 - 200
1.介绍一个项目?(网关)
a.有没有做竞品调研?
b.异步为什么要比同步好?
c.返回的请求和你发出的请求如何对应起来的?
d.如果又来新的请求,会怎样?
流量控制如何实现的?
f.对比三种限流适用场景?
g.对请求的时延要求高,用什么限流?
h。网关如果是集群,如果在A网关上被限流,B网关上没被限流,怎么办?
:::color4
分布式限流
:::
i.每次请求都往Redis写一次?有没有优化的点?
:::color4
本地缓存限流(Guava RateLimiter / TokenBucket):先在网关节点做一层粗限流,绝大多数请求直接被挡掉,不打到 Redis。
全局限流(Redis/集群协调):只对热点请求或临界流量再走 Redis 做精确限流。
👉 好处:减少 Redis 压力,避免所有请求都打到 Redis。
不是每次请求都 Redis INCR,而是 按时间片/批量更新:
节点本地计数(比如 100 次请求)先累计。
达到阈值后再批量写 Redis(或者定时刷新)。
👉 这样 Redis 访问量从 QPS 级别 降到 QPS/100 级别。
Redis 维护一个全局桶(比如 10w 个 token/min)。
每个网关节点定时从 Redis 拉取一部分 token(比如 A 拉 3w,B 拉 2w)。
请求来了就只消耗本地 token,没 token 才拒绝。
👉 好处:请求不需要实时访问 Redis,性能最好。
👉 缺点:会有一定“不均衡”,但整体不会超全局限流。
总结:
1.对于令牌桶就是一次拿一批,然后缓存到本机,减少网络传输
2.只对热点请求or 临界流量 做Redis限流
:::
j.怎么能让一个请求永远都访问一个节点?
做这个之前有没有做竞品调研?
Netty在哪个阶段?什么作用?
为什么用Netty?
只用Netty的HTTP协议,为什么不用Tomcat这些?
Netty如何保持长链接?
哪个框架有用到Netty?
链接如何保活的?
你的网关和大厂可用网关对比缺少什么?
用你的网关有多少性能损耗?
一般网关是什么结构?
a.rpc如何做泛化调用?
b.设计5qps-500wqps的限流器,如何做?
c.令牌桶怎么设置?分布式场景下怎么填充令牌?
挑一个熟悉的项目介绍?(网关)
:::info
:::
里面的限流、均衡、重试熔断是你自己做的吗?
:::info
都是有自己的实现
:::
滑动窗口怎么实现的
:::info
双端队列,存时间戳。
来的时候先剔除当前时间点之前的请求时间戳
存队列,先判断是否满了上限,满了就返回一个429的HTTP状态码
:::
i.颗粒度多大?
:::info
可配的。
配置是三级,nacos动态,文本静态,代码写死
:::
ii.窗口存在哪里?
:::info
jvm堆内存
:::
1.存在内存里,那么如果有多台机器的话,怎么做?
:::info
如果网关集群,如何对下游,单体架构的网关,无状态的集群,发ping。网关搭建集群
网关的理念是不与第三方产生依赖
:::
不依赖其它外部依赖是为了解决什么问题?为什么这么想?
:::info
为了更为纯粹,带来繁重的一个复杂度
:::
令牌桶如何做的?
:::info
:::
e.一致性哈希算法?解决了什么问题?
:::info
hash环
数据结构TreeMap,大于等于它的下一个节点。
我们动态增删实例,它影响的范围是可控的。
如果比较好的话,分布比较均衡,加虚拟节点
:::
f.随机、轮询、一致性哈希,哪个更好些?
:::info
得看具体的需求
但我们比较少或者实际用得比较多,就是像基于最小连接数,或者说基于cpu,这些下游服务的指标么
:::
某些请求响应时间长,有些短,混着来的,用哪种负载均衡策略更合适?
:::info
盲目的,不是提前告知的。
那我觉得就我那三种估计是无法满足了吧,就之前我在dubbo官网看到它们有个最短响应优先 + 加权随机,我觉得那个算法应该比较适合这种场景
:::
h.熔断的流程?
:::info
其实整个包括像是重试,熔断,降级这一块的功能,其实我就是刚刚说的,我其实是用了reforjava这个框架么。然后我选的是 forjava这个框架,它核心在于这个框架的理念,其实是基于一种修饰者模式的一种包装思想,比如说他可以把一串lambda表达式,然后这个lambda表达式其实就是我们调用后端请求,然后后端请求回来,然后回到我们这个网关之后再进行一些回应的处理,这一块其实是一块代码么。然后其实就是可以把这一代码封装程一个lambda表达式。我们的那个框架就是可以对这个lambda表达式进行封装,最底层包装一层重试,如果里面失败的话就会重试。然后再包装一层我们的一个熔断,如果我们重试多少次之后,我们就等于对后端这个请求进行熔断,然后下一次再进行同一次请求会有一个标识的东西,然后同一次再发起请求的时候,他等于说就不允许你再执行这个lambda表达式了。
然后我引入这个框架的原因,主要是因为它并没有像Redis那种需要我去连,它本质其实是对我们代码的一种封装么,它其实是框架而不是中间层,所以说我引入这个来简化我们的一个开发流程
:::
i.知道Netty的内存池算法吗?
:::info
做通信,应该怎么去做快速分配,这对性能其实有挺大影响的,因为你高并发请求,来的时候得分配内存么
:::
j.解释下NIO?
:::info
两种含义,一种是Java,一种是操作系统的,它们可能是两个不一样的概念。然后像Java的NIO这种,它其实指的就是操作系统的IO多路复用这种东西
这个东西其实是依赖于操作系统的底层实现的,它就是说可以实现一个线程监听多个请求,然后它的具体落地也是有多种,像Linux这边就有select,poll,epoll这些。
Redis同样也是应用了
:::
k.读写线程怎么和监听线程分开的?
:::info
boss线程,worker线程。
:::
1.介绍下网关?
:::info
这个项目就是我简历上的一个网关项目么,然后这个项目的话,其实就是我自己从0到1搭建的一个底层的一个所谓的轮子项目,然后这个项目其实就是我做多了,可能做多了,市面上那些教学项目,或者说那些业务项目,然后我就想着自己去搭建这个项目,
然后在做这个网关项目之前,我就做过一些市面上的网关的调查或者说我给自己网关下一个定义以及理念,为什么我要自己实现一个网关而不是说去学习市面上已有的网关,
然后包括我调查了市面上已有的一些网关然后做了对比之后给我自己的网关下的一个理念,
就是一个轻量级,高吞吐的网关,
还有就是不跟外部服务不产生过多依赖的就是或除了服务发现外,
不跟其他中间件以及其他的一些框架比如spring产生依赖,
还有就是对上游的请求是没有要求,就是说你不需要在HTTP请求头里添加特殊字段,你只要正常的HTTP请求就行了,以及我希望我的网关下游的服务对我的网关是没有感知的,
就是说你下游的服务只要把你这个服务注册到你的注册中心或者说我们的一个服务发现平台上也不需要感知到我的网关,我就可以直接调用到你。这几个就是我在做网关之前给我的网关下的几个定义么。
:::
a.和别人一起做的吗?

b.只和服务发现产生依赖?如何做到这点的?
:::info
如何做到这点
首先就是一个服务发现平台的选择么,就是现在市面上开源的服务发现组件很多,像etcd,zookeeper,nacos这些。然后我之所以选择nacos主要是因为nacos既是注册中心也是配置中心,还有就是社区活跃度也是很高的,后续开发中如果遇到一些bug能得到一些反馈之类的。nacos它的动态配置更新功能也是满足我们下游服务配置信息发生变更,网关就能感知到这么个功能的。然后这个就是我们的服务发现平台的选项
然后像是使用的话,网关这一块因为我们没有依赖spring那一套,所以得去引入nacos客户端原始的jar包。然后当时也是参考了官网文档的实例来进行代码编写。下游后端服务那一块,其实就是只需要把自己注册到nacos上面就好了
:::
c.请求如何发送的?
:::info
这个的话就是需要暴露出我们的网关的一个IP地址,就是以我目前的一个架构来说,就是肯定是直接访问我们的网关因为我网关启动,其实它是以netty的形式启动的么,然后启动之后,它进程就是会被分配一个IP Port。然后这时候我们对他这个IP Port发送我们的HTTP请求,然后这里面我会用netty它自带的一个解码器,因为默认的话,其实是指当时只提供了HTTP的一个实现。
因为目前我们这个网关是一个单体的架构,然后如果扩展成集群的话,可能又是不一样的请求方式了
然后整体的话就是这样子
客户端直连,要按后端接口请求方式,请求
:::
d.为了不和其他服务产生依赖,肯定对依赖做了收口吧,做了哪些处理呢?
:::info
:::
e.路由是怎么做到的,谓词匹配?灰度怎么做的?
:::info
这个主要是参考了springcloudgateway它那套的做法,比如配置文件或者说配置中心的一个大json,然后这个这个文件里有一个routes,里面就存着后端服务一个个接口的路由信息。就是请求来的时候我们会把路由配置的URL转成正则表达式进行匹配,如果匹配不到就返回404。如果匹配到多个,我当时是有对这些路由提供一个Order配置,就优先按order最大的返回,如果出现那种比如api/service和api/**这种就优先走url最长的。
灰度的话我当时设计的时候一开始是想着把它和负载均衡放在一起,但后面想了想感觉这样耦合度有点高了,所以就是说把灰度放在了负载均衡前面,那么就是请求过来的时候,根据灰度策略决定是否走,然后根据负载均衡从后面挑一个节点出来。然后灰度的实现的话我自己默认提供了两种,一种是根据客户的IP,以及根据灰度流量,就是实例集合里有10%的灰度实例,那就有10%的概率会走灰度
:::
f.信号量隔离和线程池隔离是什么?两者的顺序?
:::info
信号量隔离就是说我们可以对我们的后端服务进行一个信号的隔离,就是它要请求到我们的后端,就得去拿到我们的信息,拿到了才能往后走,如果拿不到就相当于被限流了,其实是说为了保护后端服务端的一种措施
而线程池隔离其实是说对于我们的后端服务,它其实前面是有一个线程池的,然后请求过来的时候会丢给线程池进行处理,然后这个时候就是能保证每个请求它是分开来的。
顺序的话自己是有默认的,但这是可配置的,就交给用户去配置
:::
g.有限流后为什么还要隔离?
:::info
我觉得隔离的重点在于那个资源的隔离,就是你某一个点执行不会拖垮到整个服务
:::
h.有限流后,什么情况下还需要信号量隔离?
:::info
可能那种那种sass平台
:::
12.网关是你公司实习的项目还是自己做的项目?
:::info
自己做的
:::
13.网关最难的点?
:::info
我觉得是有这个想法吧,就是说,有的人可能只是感觉跟网上的一些学习业务项目可能就满足了。然后可能说我最开始这个东西好像很高端或者说能不能行,其实他,你会发信啊感觉好像也没有那么难的样子,我觉得有这个想法才是最难的 ,然后真正实际开发过程中,它其实是属于另外一种层次的难,那种难度的话,它其实是你可以通过去网络上寻找方案或者求助来解决,但是想法上的改变我觉得是比较难以去改变的
:::
14:网关最需要关注的点?
:::info
它的高可用或者高性能,就架构层面,网关不崩,性能比较好,大概是这样子
:::
15.如何保证网关高可用、高性能?
:::info
在做这个网关之前,我其实就给自己的网关下了几个定义或者说下了几个目标,然后在整个开发过程中,我都遵循了这个目标首先的话,它其实就是说给自己的一个目标就是我要实现高性能的一个网关所以说在技术选择这一块,我使用的是netty和aysnchttpClient的网关,实现了一个全异步链接的请求,这两个框架就在Java网络编程这一块就是属于很出名的,第一梯队的那种,而且开源社区也是比较活跃。
然后测试下来,就我自己在我自己电脑上起了这helloworld的一个springboot服务,然后通过我们的网关去转发请求打到这个服务。测下来吞吐量也是在2w左右,还有就是我还用了springGateway进行一个对比,它的话就是大概才1w出头
对于高可用方面,其实我之前想的就是要不要让我这个网关去支持一个集群,然后导致说提高它的一个高可用指标,后面我想了一次,我就暂时把这个想法搁置了。因为我觉得我们如果网关要搞集群来实现它的高可用的话,它其实是要实现网关之间互相通信,然后我在客户端那边他其实要做一个网关元数据的存储或者负载均衡,它就是说要对客户端做一些改造。然后我之前,给我网关下的要求或者说定义的话,其实是我希望我对上游服务没有要求,对下游服务没有依赖这样子。
然后我也实际的功能实现中也做了其他方面的高可用,当后端出了问题后,我网关会对它进行一些熔断,就是从后端下游这个层次来提高我们这个高可用的架构。
:::
16.后端服务响应时间太长,但没挂,如何处理的?
:::info
这个的话就是我这个项目里用的那个HttpClient里有个参数,可以设置超过多久响应时间就失败了。然后我其实在网关的弹性架构层面用了那个resencefjava这个框架,然后我的重试,熔断,降级这些策略都是基于这个框架去做的,里面也是有些参数可以我们去配置的。然后假设重试了3次还是超时,我们还是会对它进行熔断,过了多少秒之后,会再次尝试是否真挂了,如果成功那就取消熔断,失败了那就继续熔断
:::
17.如果请求在网关挤压,会怎么办?
:::info
额我觉得就是另外一个请求,就是如何做限流,进行一些限流的规则,比如用滑动窗口,就让它的请求就是平滑化。
:::
18.网关如果要集群化,如何做?
:::info
我觉得有两个方案吧,一种就是引入一些分布式协议之类的,然后实现各个网关之间的通信,这个可能改造起来就比较复杂,就如果是那种抛离出来,就像是mysql或者Redis那种集群部署方案。
然后就是在客户端层面做负载均衡,类似与那个memcache那种架构,客户端会从注册中心拿到网关的元数据,然后在客户端那一层面做网关的负载均衡,来实现高可用,这个的话我觉得就得给客户端一个SDK,但这种客户端就得感知到网关了
两种方案就各有缺点吧
:::
客户端不做改造,有没有可以实现的方案?
:::info
我觉得得再引入一层来做吧
像是比如说用DNS来做,把我们的网关节点都搬到DNS上面,然后配个域名,然后基于DNS这些来搞,然后可用这方面就转移给第三方了,
:::
:::info
那我还是说先讲我自己做的一个项目,就先不讲实习吧。因为我觉得他是我自己去说,从0到1搭建的一个这么一个网关的项目。也是比较偏底层,就轮子项目,不是外面那种额外卖之类的业务项目。而是我自己去开发打底层的一个项目。然后的话就是我在首先在技术选项上,我是使用了netty。就是作为我们的一个网关的一个主题的一个处理流程,因为其实说白了,还是跟网络打交道比较大,然后在Java领域的话,netty也算是最出名的框架,开源社区活跃也是非常OK的
然后我在这个网关之前,我给自己下的一个理念,就是我的网关尽量要做到轻量级,就是说除了我的服务发现这个应用后,我不应该跟其他的应用产生依赖,但是服务发现他肯定就是一个必须的一个东西么,就是我往往如果发现下游的这些服务,这是一个要求,然后还有一个要求,我希望对上游的请求是没有依赖的,就上游过来的请求是通用的HTTP请求,不会去请求头里面添加一些特殊的字段。然后我也希望我的网关对下游,它下游对我的网关其实是无感知的。
你只需要正常的去说启动你的这个服务。然后把你注册到我们的一个服务发现平台上,那我就可以直接调用我,我们的网关就可以直接调用这个服务。它其实根本不需要知道我们的网关的。所以说,这是我在做网关之前给自己下的一个要求,然后我在之后的开发过程中也是一直希望能够遵循这些要求,然后他的一个整体流程的话。。。。
:::
:::info
…..
:::
:::info
额我想想,我觉得那种跟内容合规有关的点可以在这里做,比如说我们网关后面对接的是AI大模型这一块,然后可能AI大模型它被用户的prompt去诱导生成一些涉黄的东西,我们就可以在这里做些敏感词检测之类的
得用户自定义
我了解你的意思,嗯嗯嗯明白
:::
:::info
这个我有考虑去做他,但最后又没去做他的原因是因为我觉得鉴权比较难统一的了,可能下游我的支付和用户业务是两套不一样的鉴权,如果由网关来做,感觉就把下游限制死了,就可能说你下游给我返回什么字段之类的,比如说拿到一个用户,他是否属于我们的一个黑名单状态,那可能我需要用到下游的一些信息,这时候我的网关就跟下游产生了一个依赖么,我其实是不太想这么干的。
这个就交给用户去扩展
像加一个JWT,技术是比较容易,就是用工具类去生成一个JWT
AES…..
:::
:::info
支持一个集群
:::
:::info
我觉得得后端去处理吧,如果网关要实现的,那么他就得存储一些唯一标识来实现幂等,那我觉得它就变成有状态的了,就违背了我希望它是无状态的理念,扩缩容这方面就没那么灵活了。
关于有状态服务的扩缩容,游族实习那块接触到一点,其实游戏这边其实都是有状态的
:::
:::info
就是那些基于业务的策略,像什么基于内存,基于最小连接数这些,就是基于后端机器load的一些指标做负载均衡么,就像dubbo的五种负载均衡类型有了解过。但是我觉得还是需要后端的一个支持,比如说后端上报我当前机器负载的指数,像cpu,内存使用率之类的,或者说Tomcat的连接数。
然后这些指标就是得有一个动态配置中心存储或者说去通知网关
:::
:::info
主要依赖框架吧,像netty的evenloop group之类的
:::
:::info
它首先就是说我们的IO密集型太高了,然后我这边CPU没吃满么,我们这边load就没上去。然后这种情况的话,我觉得我们最直观的一个方案就是说加大我们的一个线程数量,就是把我们的入口扩大,让更多的请求进来,但当然这得看你机器的内存配置,线程new太多的话OOM了也不好。
还有就是利用compeletableFuture异步,
其实说白就是IO密集的线程占着茅坑(CPU核心)不拉屎,浪费我们的CPU,且因为线程会被阻塞住,新的请求过来就只能等待,吞吐量就下来了,如果扩大线程数又会被硬件条件给限制住,我觉得这种情况下协程或者说虚拟线程就比较适合了,因为它的话就内存占用很小就相比于线程的4mb,而且线程上下文切换成本约等于0,我们几乎可以无限扩大我们的线程数,直接通过升级JDK 升到21
:::
:::info
我 9 月 8开始说,前置,调研一些网关,或者说常见的一些工具什么的,我觉得都是提前规划好的。
个人对我们所谓的一个Java领域或者说编程领域的一种感觉吧,就是我觉得我还是挺适合当程序员
的,挺喜欢coding的感觉的。
:::
a.做这个之前有没有做竞品调研?
:::info
嗯,比如说,Spring Cloud Gateway、Zuul 这些都是常见的网关,像 Nginx 也很常用。
我想先说 Zuul,它老版本对异步响应支持不是很好,更偏向同步处理。
至于 Spring Cloud Gateway,我一开始以为它是轻量级的,但实际使用下来,感觉还是挺“重”的。
我自己写了一个网关,也在同一个环境下对两个网关做了测试。结果我自己的网关吞吐量差不多 2 万,而 Spring Cloud Gateway 大概只有 1.1 万到 1.2 万左右,具体大概 1.177 万。
所以我觉得,我自己的网关在轻量化和高吞吐上更有优势,而我的目标就是做一个既轻量又高吞吐的网关
:::
b.Netty在哪个阶段?什么作用?
:::info
主要做服务端接受我们外部的一个请求。最基本的就是处理,然后它其实也是提供了很多工具,像协议转换
Netty 在网关中主要充当服务端的角色。它负责接收客户端发过来的请求,然后把这些请求处理成我们应用可以理解的形式。
具体来说,流程大概是这样的:
简单来说,Netty 就是网关和客户端之间的“网络桥梁”和“请求处理引擎”,它帮我们解决了底层网络通信、编解码、异步处理等问题。
:::
c.为什么用Netty?
:::info
这个主要是我当时给我网关下的定义就说尽可能高性能,因为网关作为我们后端服务的门户,网络通信这一块就是非常重要的么。在Java生态这一块,NIO的网络框架属于no1的就是netty,像可能mino那套虽然跟netty很像,但API易用性其实是没netty高的。
还有就是netty也提供了很多工具
:::
d.只用Netty的HTTP协议,为什么不用Tomcat这些?
:::info
我觉得,如果从零去写网络处理代码,其实没必要那么复杂。你用 Netty,主要是用它提供的 HTTP 能力 对吧?其实你也可以直接用 HTTP 协议,然后像用 Servlet 或者 RestTemplate 那样处理请求就行。
但 Netty 的优势在于,它底层帮我们处理了很多高性能细节,比如:
这些东西,如果自己去写,从零实现,不仅繁琐,而且容易出错。但 Netty 已经帮我们封装好了,而且参数都是可以灵活配置的:比如你可以调 worker 线程数、连接超时时间等等,非常方便。
实际上,你在 Netty 中只需要启动一个客户端或者服务端实例,它就能直接处理大部分底层细节。你只需要专注于业务逻辑,而不必去管 TCP 粘包、拆包、事件循环等复杂问题。
所以核心就是:Netty 省去了很多重复造轮子的工作,让我们专注于业务,而不是底层网络实现。
:::
e.Netty如何保持长链接?
:::info
:::
f.哪个框架有用到Netty?
:::info
像rocketmq,zuul2,什么的。很多主流的中间件网络通信这方面都有用到netty的
框架的话,我记得spring webflux也是有用到netty的
:::
g.链接如何保活的?
:::info
:::
1 | public static void writeBackResponse(GatewayContext context) { |
介绍一个项目?(网关)
:::info
:::
a.有没有做竞品调研?
b.异步为什么要比同步好?
:::info
:::
c.返回的请求和你发出的请求如何对应起来的?
:::info
:::
d.如果又来新的请求,会怎样?
流量控制如何实现的?
f.对比三种限流适用场景?
:::info
漏桶算法适合于下游需要平滑流量的场景,就是希望以一种恒定的速率去处理请求
而滑动窗口和令牌桶都适用于应对突发流量,就那种瞬间的流量,突刺流量
滑动窗口,如果是基础的滑动窗口因为是一个比较早的算法,不怎么用了,我觉得它应该适用于那种后端服务在一定时间内只能处理一定的请求
:::
g.对请求的时延要求高,用什么限流?
:::info
滑动窗口吧。我可以判断滑动窗口的大小来判断是否可以放行,如果请求满的话会直接返回,能有失败的反馈。
而漏桶的话,会先进入进入就绪队列里等待
对于令牌桶,嗯我觉得它应该和都一样,都是拿到令牌放行,拿不到就返回了
:::
h.网关如果是集群,如果在A网关上被限流,B网关上没被限流,怎么办?
:::info
Redis
:::
i.每次请求都往Redis写一次?有没有优化的点?
:::info
每次会写,网关会被Redis拖一下,从时间延迟来讲。
可以先把Redis的一批Token 拿到加载到本地
:::
j.怎么能让一个请求永远都访问一个节点?
:::info
就是我们负载均衡那层不能采用随机,轮询,权重这些。

:::
1.挑一个项目介绍(网关)
:::info
项目介绍
这个项目就是我简历上的一个网关项目么,然后这个项目的话,其实就是我自己从0到1搭建的一个底层的一个所谓的轮子项目,然后这个项目其实就是我做多了,可能做多了,市面上那些教学项目,或者说那些业务项目,然后我就想着自己去搭建这个项目,
然后在做这个网关项目之前,我就做过一些市面上的网关的调查或者说我给自己网关下一个定义以及理念,为什么我要自己实现一个网关而不是说去学习市面上已有的网关,
然后包括我调查了市面上已有的一些网关然后做了对比之后给我自己的网关下的一个理念,
就是一个轻量级,高吞吐的网关,
还有就是不跟外部服务不产生过多依赖的就是或除了服务发现外,
不跟其他中间件以及其他的一些框架比如spring产生依赖,
还有就是对上游的请求是没有要求,就是说你不需要在HTTP请求头里添加特殊字段,你只要正常的HTTP请求就行了,以及我希望我的网关下游的服务对我的网关是没有感知的,
就是说你下游的服务只要把你这个服务注册到你的注册中心或者说我们的一个服务发现平台上也不需要感知到我的网关,我就可以直接调用到你。这几个就是我在做网关之前给我的网关下的几个定义么。

看面试官反应。。。。。
面试官想问技术实现?
技术实现(参考难点那里):
首先是技术选型:netty,AsyncHTTPClient,为什么要选择。nacos,
spi
过滤器,过滤器节点编排
具体过滤器节点实现

:::
a.做了多久?
b.实现用到的框架?有用到spring框架吗?
c.对并发流量如何处理的?
d.有用到线程池吗?
·对线程池的理解?
7.为什么写GraceGateway?
a.有参考别人的代码吗?
:::info
有做些前置准备学下netty之类的,参考还是没有的

:::
b.网关用了哪些设计模式?
:::info
用的还是挺多的。像是工厂,单例。类似责任链


:::
c.有看过Tomcat源码吗?
:::info
:::
d.对比限流算法特点?
:::info


:::
Japan travel target point:1 million ,cur process:4k,i hope me that i can achieve it in college 3
England Travel : 4 million,i hope i can achieve it in college 4
说他快,一般是说能高效地移动大数据,类似于管道,即高高吞吐量
两个点
1.顺序磁盘IO
写的是磁盘,kafka是不会写内存的。
kafka的每个partition其实就是一个文件,而topic其实是一个文件夹的名字,写数据都会写到每个partition的末尾
但这种方式有个缺点,就是没法删数据,kafka的所有数据都会保留下来,每个consumer对于同一个topic都会有一个offset去记录当前consumer读到了哪里
而这个offset是客户端SDK保存的,broker无感知
kafka提供了两种删除策略,一种是根据时间,一种是根据partition文件大小
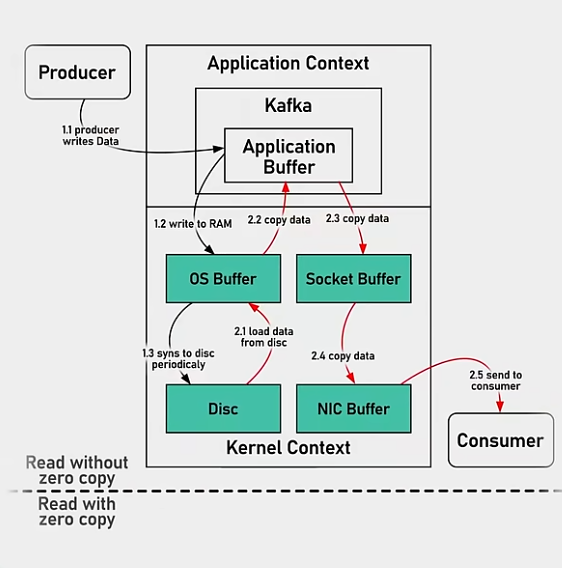
2.零拷贝技术
常规拷贝
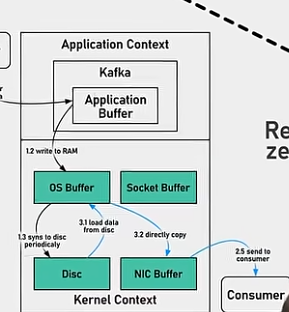
零拷贝,通过send file命令直接告诉cpu直接从os buffer里拷贝数据
3.从消息的角度来说,kafka用的是堆外内存,无GC,消息写入的是page cache 对于Linux来说,然后直接落盘
4.自动预热


怎么预热:从日志回放 用户的请求。
kafka会在预热的时候把队列里的消息加载到page cache里,但也怕启动的时候因为预热而变慢,这都是有参数配置的
5.分布式架构
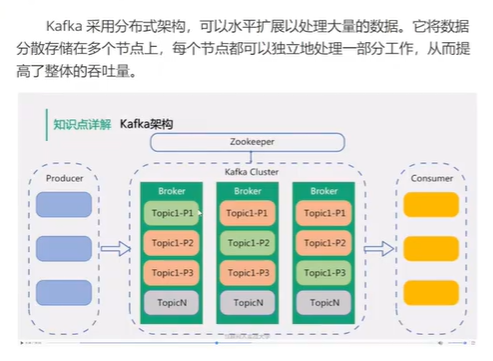
分布式做得好的话,性能不好就加机器呗,无非就是成本问题
6.应用层面的优化
消息压缩,kafka支持gzip 或者 Snappy格式对消息进行压缩,减少网络传输的压力
批次写入,即聚合发送
假设网络带宽为10MB/S,一次性传输10MB的消息比传输1KB的消息10000万次显然要快得多。
为啥要用Java写?
最开始,应该是考虑多平台,内存安全等因素。当然也可能有跟着hadoop随大流走Java的成分。 但是实际上kfk已经有c++版本了。可以获得更好吞吐。那个应该是叫redpanda. 不过,由于go极大刺激了java社区,java社区正在奋力追赶相关特性。分代zgc,虚拟线程,堆外内存API,SIMD等特性基本都追齐了。下一个jdk lts应该就可以全部发布了。 对于目前兴起的用c go等重写中间件的行为,我建议我们可以进入观望期。再看看java的发展与社区的进度。实际上大量的中间件社区已经全面抛弃java8了,升级是大势所趋。