吃透netty
大纲
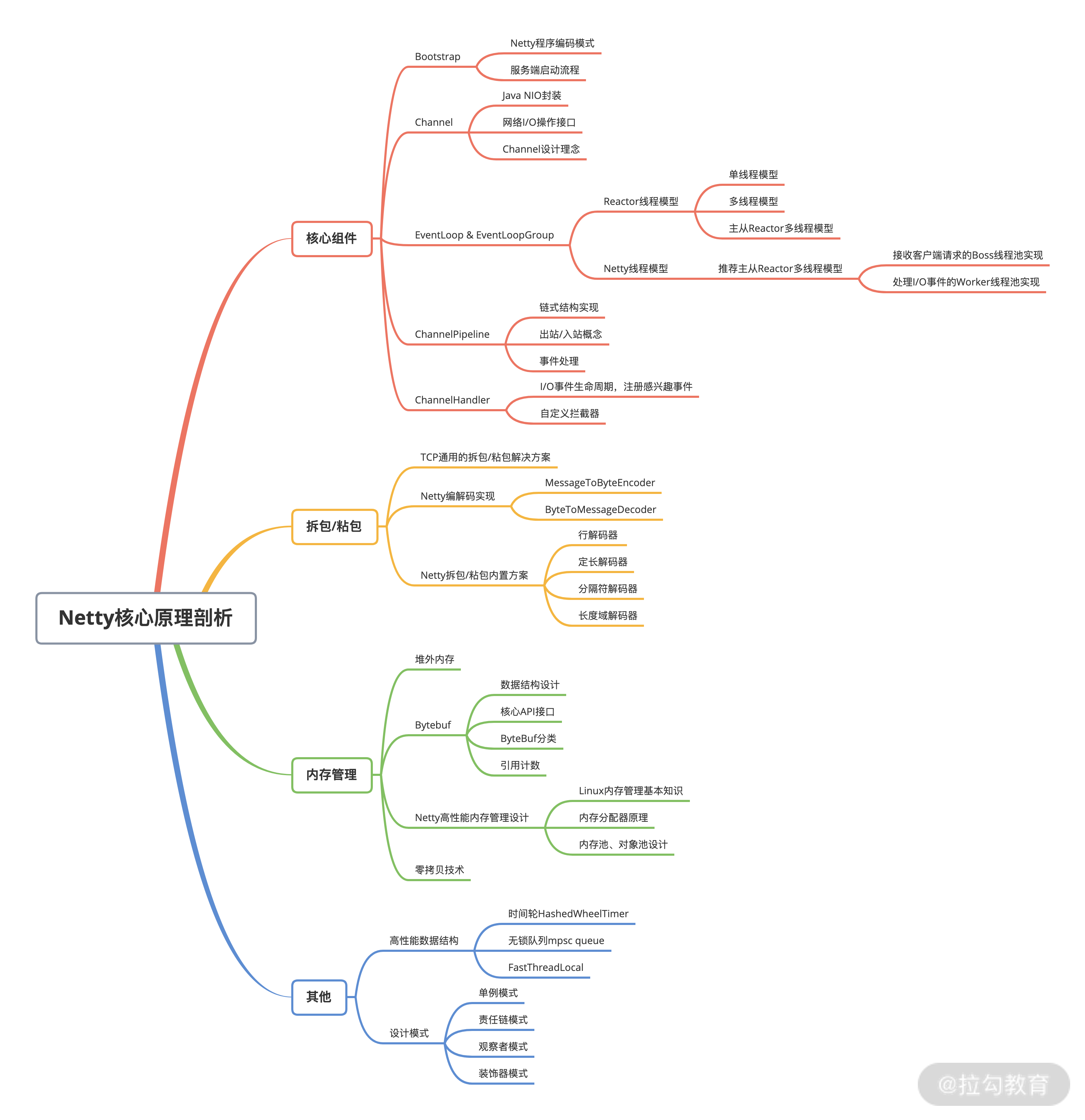
整体架构
模块
三个模块
core
protosupport
transport
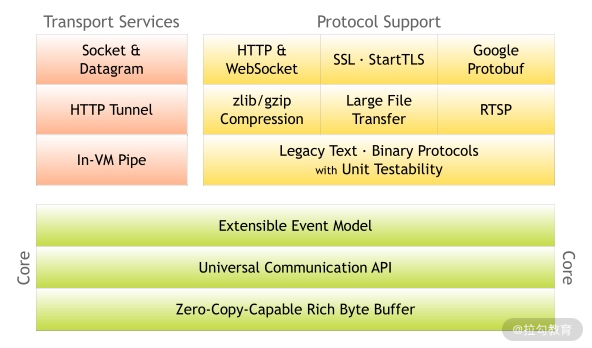
1. Core 核心层
Core 核心层是 Netty 最精华的内容,它提供了底层网络通信的通用抽象和实现,包括可扩展的事件模型、通用的通信 API、支持零拷贝的 ByteBuf 等。
2. Protocol Support 协议支持层
协议支持层基本上覆盖了主流协议的编解码实现,如 HTTP、SSL、Protobuf、压缩、大文件传输、WebSocket、文本、二进制等主流协议,此外 Netty 还支持自定义应用层协议。Netty 丰富的协议支持降低了用户的开发成本,基于 Netty 我们可以快速开发 HTTP、WebSocket 等服务。
3. Transport Service 传输服务层
传输服务层提供了网络传输能力的定义和实现方法。它支持 Socket、HTTP 隧道、虚拟机管道等传输方式。Netty 对 TCP、UDP 等数据传输做了抽象和封装,用户可以更聚焦在业务逻辑实现上,而不必关系底层数据传输的细节。
逻辑结构
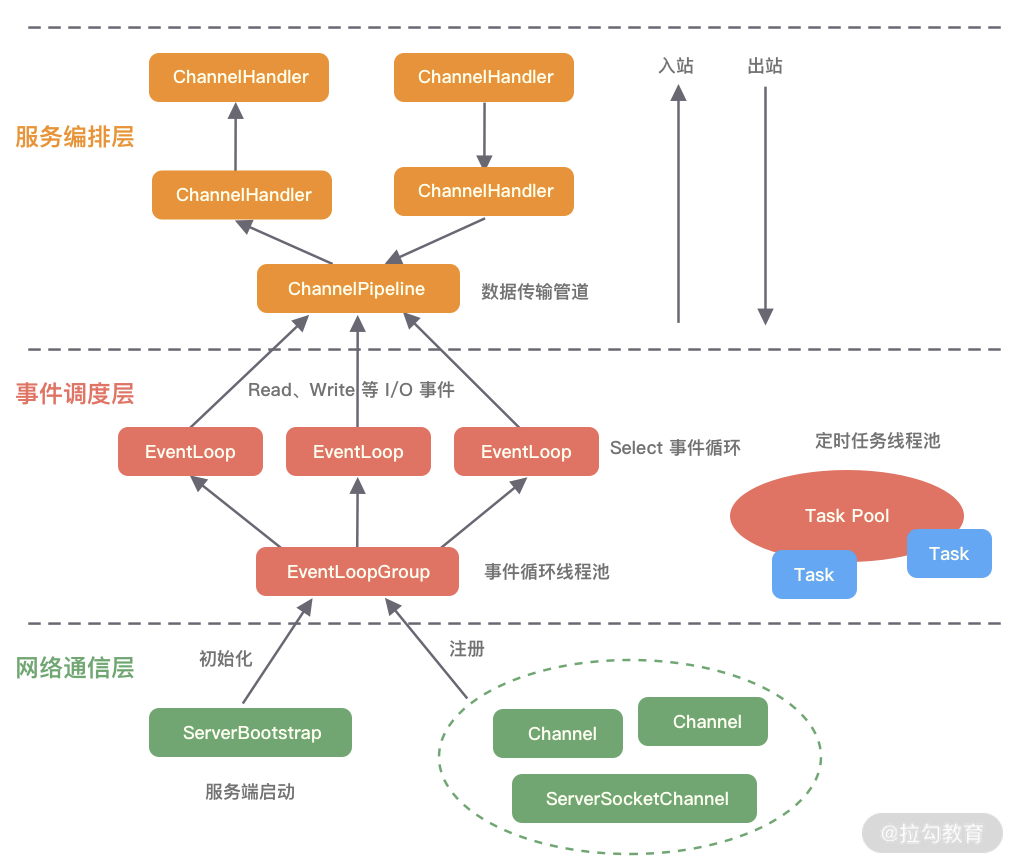
网络通信层
主要负责网络事件的监听,当网络数据读取到内核缓冲区后,会触发各种网络事件,会被注册到事件调度层进
行处理
网络通信层的核心组件包含BootStrap、ServerBootStrap、Channel三个组件。
- **<font style="color:rgb(59, 67, 81);">BootStrap &ServerBootStrap 引导
如下图所示,Netty 中的引导器共分为两种类型:一个为用于客户端引导的 Bootstrap,另一个为用于服务端引导的 ServerBootStrap**,它们都继承自抽象类 AbstractBootstrap。
ServerBootStrap用于服务器启动时绑定本地端口,会绑定两个eventloopgroup,一个boss,一个worker。而BootStrap主要是用与服务器进行通信,只有一个eventloopgroup
- channel
Channel 的字面意思是“通道”,它是网络通信的载体,说白了就是操作内核缓冲区或者说我们
可以使用channel的API来操作底层Socket
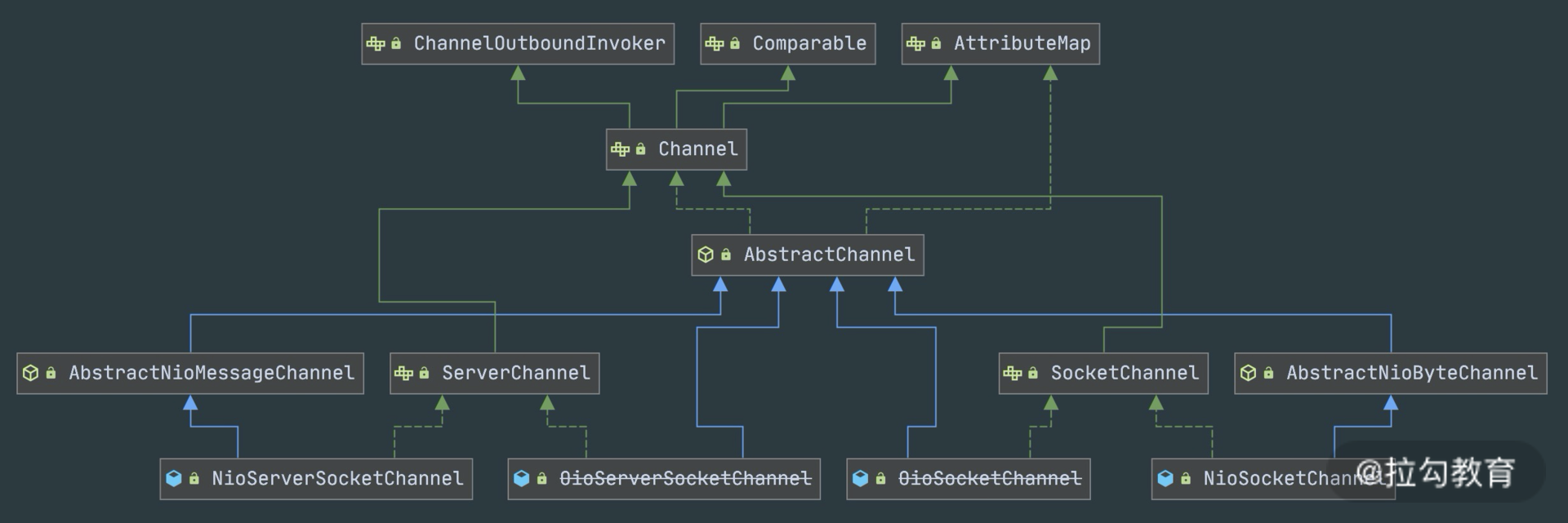
channel还有不同的状态,这些不同的状态就对应的不同的回调事件
事件调度层
事件调度层的职责是通过 Reactor 线程模型对各类事件进行聚合处理,通过 Selector 主循环线程集成多种事件( I/O 事件、信号事件、定时事件等),实际的业务处理逻辑是交由服务编排层中相关的 Handler 完成。
事件调度层的核心组件包括 EventLoopGroup、EventLoop。
这group其实就是线程池来着,eventloop就是线程
- eventloopgroup和eventloop和channel的关系
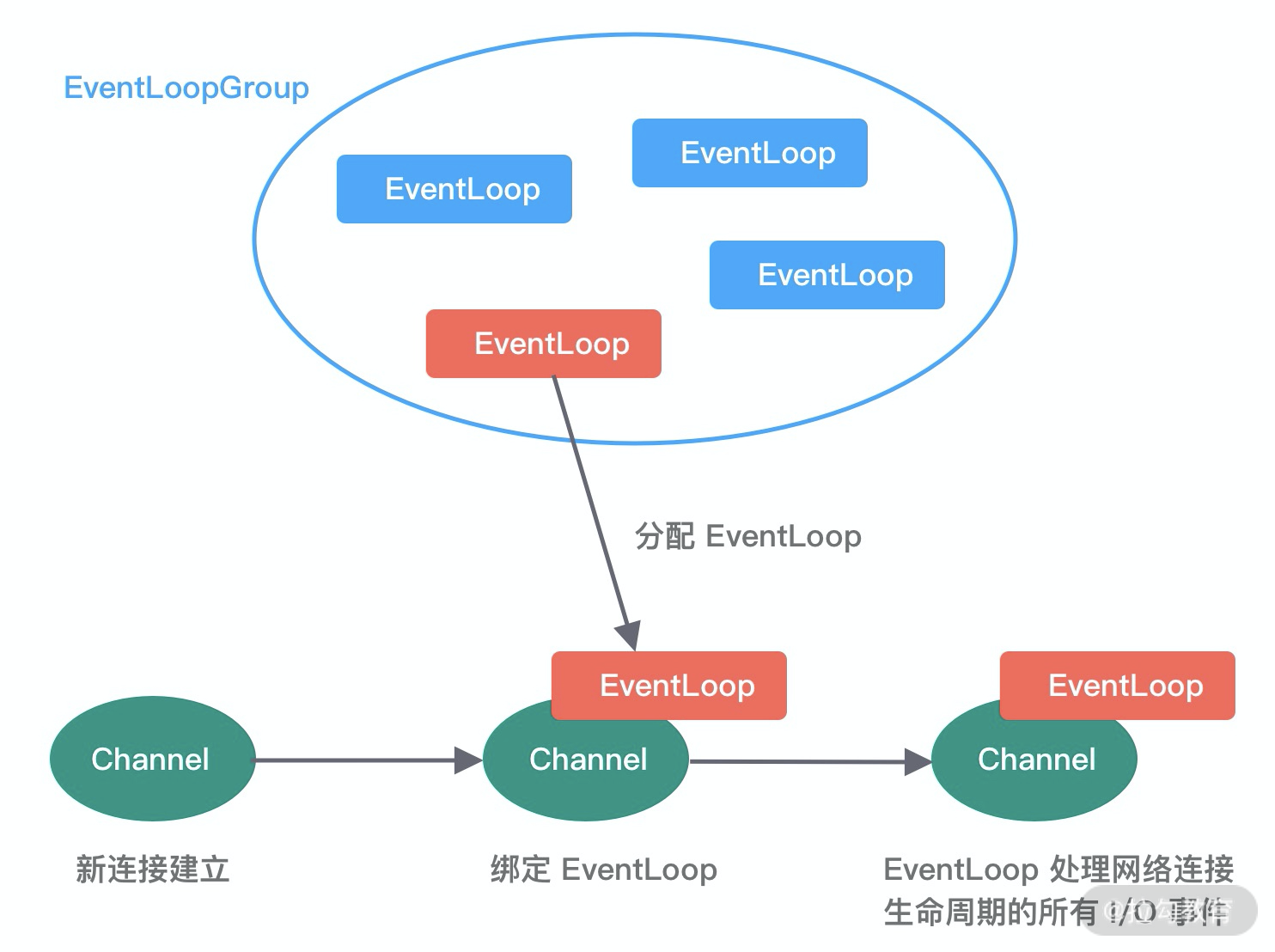
特别地说一下,channel被建立后,就会分配一个eventloop与其绑定,且可不是绑死的,可多次松绑or绑定
一个 Channel 在它的生命周期里,只能绑定到一个 EventLoop。
一个 EventLoop 可以同时绑定多个 Channel,并处理它们的 I/O 事件
然后eventloop通过操作系统的epoll监听多个channel的事件,事件复杂度接近 O (1)
·类关系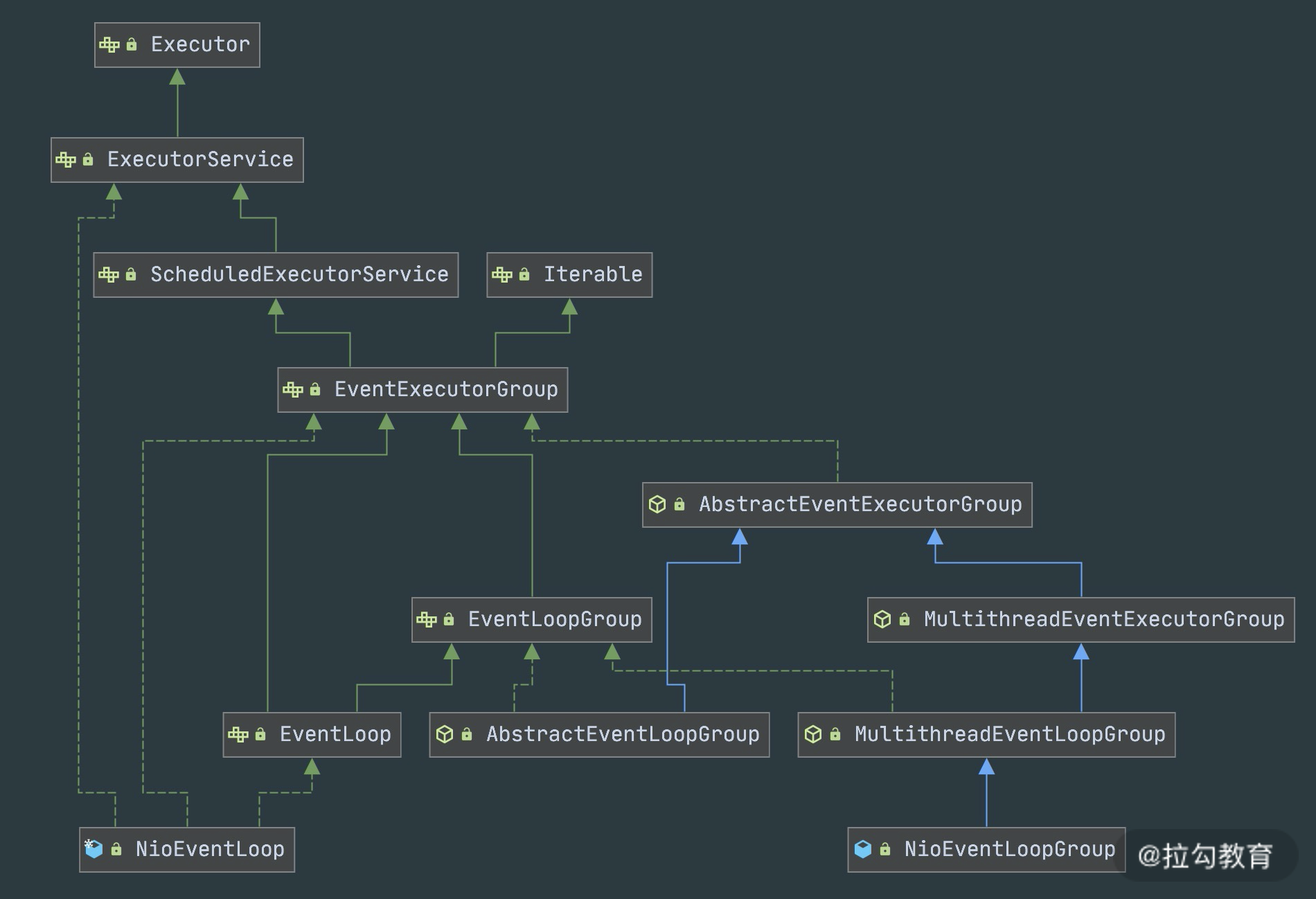
EventLoopGroup 是 Netty 的核心处理引擎,那么 EventLoopGroup 和之前课程所提到的 Reactor 线程模型到底是什么关系呢?其实 EventLoopGroup 是 Netty Reactor 线程模型的具体实现方式,Netty 通过创建不同的 EventLoopGroup 参数配置,就可以支持 Reactor 的三种线程模型:
1. **<font style="color:rgb(59, 67, 81);">单线程模型</font>**<font style="color:rgb(59, 67, 81);">:EventLoopGroup 只包含一个 EventLoop,Boss 和 Worker 使用同一个EventLoopGroup;</font>
2. **<font style="color:rgb(59, 67, 81);">多线程模型</font>**<font style="color:rgb(59, 67, 81);">:EventLoopGroup 包含多个 EventLoop,Boss 和 Worker 使用同一个EventLoopGroup;</font>
3. **<font style="color:rgb(59, 67, 81);">主从多线程模型</font>**<font style="color:rgb(59, 67, 81);">:EventLoopGroup 包含多个 EventLoop,Boss 是主 Reactor,Worker 是从 Reactor,它们分别使用不同的 EventLoopGroup,主 Reactor 负责新的网络连接 Channel 创建,然后把 Channel 注册到从 Reactor。</font>
服务编排层
服务编排层的职责是负责组装各类服务,它是 Netty 的核心处理链,用以实现网络事件的动态编排和有序传播。
服务编排层的核心组件包括 ChannelPipeline、ChannelHandler、ChannelHandlerContext。
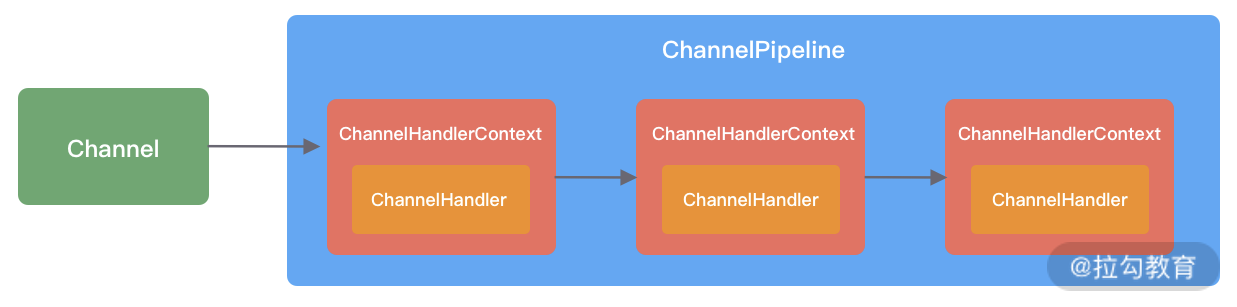
- **ChannelPipeline**
ChannelPipeline 是 Netty 的核心编排组件,**负责组装各种 ChannelHandler。**其实就是把channelHandler给串联起来,本质是一个双向链表。当网络事件来的时候,就会依次调用channelPipeline里的Handler对其进行拦截
ChannelPipeline 是线程安全的,因为每一个新的 Channel 都会对应绑定一个新的 ChannelPipeline。一个 ChannelPipeline 关联一个 EventLoop,一个 EventLoop 仅会绑定一个线程。
ChannelPipeline 中包含入站 ChannelInboundHandler 和出站 ChannelOutboundHandler 两种处
理器,我们结合客户端和服务端的数据收发流程来理解 Netty 的这两个概念
- **<font style="color:rgb(59, 67, 81);">ChannelHandler & ChannelHandlerContext</font>**
为啥每个channelHandler都要绑定一个**ChannelHandlerContext?**
有点类似于工人和工具工位的关系
ChannelHandlerContext 用于保存 ChannelHandler 上下文,通过 ChannelHandlerContext 我们可以知道 ChannelPipeline 和 ChannelHandler 的关联关系。ChannelHandlerContext 可以实现 ChannelHandler 之间的交互,ChannelHandlerContext 包含了 ChannelHandler 生命周期的所有事件,如 connect、bind、read、flush、write、close 等。此外,你可以试想这样一个场景,如果每个 ChannelHandler 都有一些通用的逻辑需要实现,没有 ChannelHandlerContext 这层模型抽象,你是不是需要写很多相同的代码呢?
1 | public class MyHandler extends ChannelInboundHandlerAdapter { |
整体流程
服务端启动要干什么
配置线程池
Channel 初始化
端口绑定
1 | // 检测是否使用Epoll优化性能 |
eventloop精髓
网络框架的设计离不开 I/O 线程模型,线程模型的优劣直接决定了系统的吞吐量、可扩展性、安全性等
三种 Reactor 线程模型
单
多
主从
前两种就是建立和业务处理没分开,无法轻松建立大量连接,建立连接会被耗时的业务请求影响到
Netty EventLoop 实现原理
在 Netty 中 EventLoop 可以理解为 Reactor 线程模型的事件处理引擎,每个 EventLoop 线程都维护一个 Selector 选择器和任务队列 taskQueue。它主要负责处理 I/O 事件、普通任务和定时任务。
1 | /** |
- select(…) 👉 负责 I/O 事件的监听(类似
Selector.select())。 - processSelectedKeys() 👉 处理就绪的 I/O 事件(读/写/连接)。
- runAllTasks() 👉 处理任务队列里的任务(用户提交的 Runnable、定时任务等)。
- ioRatio 👉 控制 I/O 与任务的时间分配。
- isShuttingDown()/confirmShutdown() 👉 支持优雅关闭。
事件处理机制
 对于eventloop来说就是无锁串行化,不同eventloop之间是不会有交集的
对于eventloop来说就是无锁串行化,不同eventloop之间是不会有交集的
**一个 ****Channel** 在注册到某个 EventLoop 之后,它的整个生命周期都只会由这个 EventLoop 负责
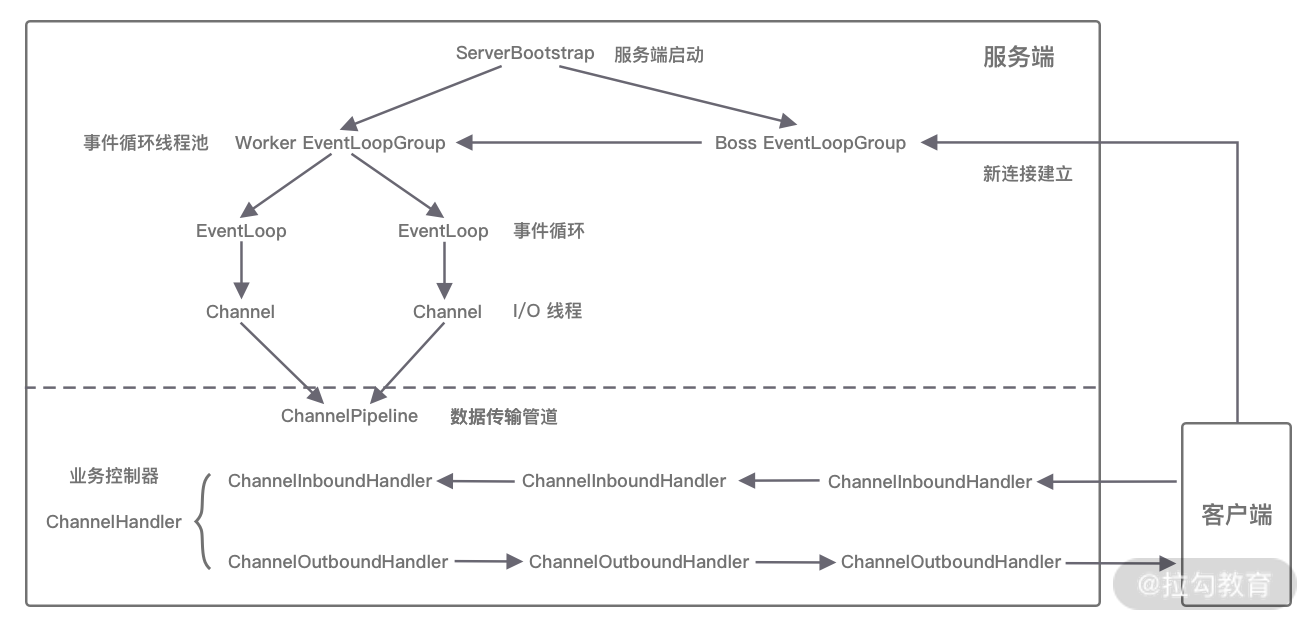
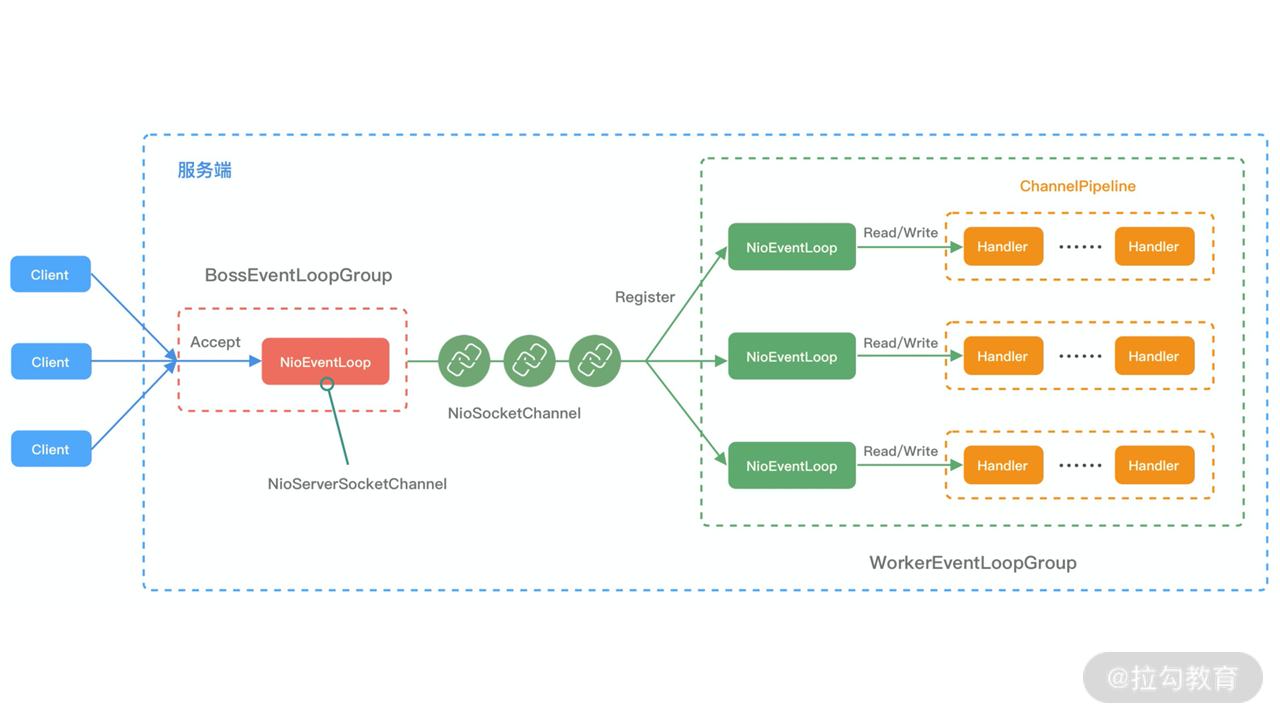
结合 Netty 的整体架构,我们一起看下 EventLoop 的事件流转图,以便更好地理解 Netty EventLoop 的设计原理。NioEventLoop 的事件处理机制采用的是无锁串行化的设计思路。
- BossEventLoopGroup 和 WorkerEventLoopGroup 包含一个或者多个 NioEventLoop。BossEventLoopGroup 负责监听客户端的 Accept 事件,当事件触发时,将事件注册至 WorkerEventLoopGroup 中的一个 NioEventLoop 上。每新建一个 Channel, 只选择一个 NioEventLoop 与其绑定。所以说 Channel 生命周期的所有事件处理都是线程独立的,不同的 NioEventLoop 线程之间不会发生任何交集。
- NioEventLoop 完成数据读取后,会调用绑定的 ChannelPipeline 进行事件传播,ChannelPipeline 也是线程安全的,数据会被传递到 ChannelPipeline 的第一个 ChannelHandler 中。数据处理完成后,将加工完成的数据再传递给下一个 ChannelHandler,整个过程是串行化执行,不会发生线程上下文切换的问题。
NioEventLoop 无锁串行化的设计不仅使系统吞吐量达到最大化,而且降低了用户开发业务逻辑的难度,不需要花太多精力关心线程安全问题。虽然单线程执行避免了线程切换,但是它的缺陷就是不能执行时间过长的 I/O 操作,一旦某个 I/O 事件发生阻塞,那么后续的所有 I/O 事件都无法执行,甚至造成事件积压。在使用 Netty 进行程序开发时,我们一定要对 ChannelHandler 的实现逻辑有充分的风险意识。
NioEventLoop 线程的可靠性至关重要,一旦 NioEventLoop 发生阻塞或者陷入空轮询,就会导致整个系统不可用。在 JDK 中, Epoll 的实现是存在漏洞的,即使 Selector 轮询的事件列表为空,NIO 线程一样可以被唤醒,导致 CPU 100% 占用。这就是臭名昭著的 JDK epoll 空轮询的 Bug。Netty 作为一个高性能、高可靠的网络框架,需要保证 I/O 线程的安全性。那么它是如何解决 JDK epoll 空轮询的 Bug 呢?实际上 Netty 并没有从根源上解决该问题,而是巧妙地规避了这个问题。
netty如何规避的
1 | long time = System.nanoTime(); |
Netty 提供了一种检测机制判断线程是否可能陷入空轮询,具体的实现方式如下:
- 每次执行 Select 操作之前记录当前时间 currentTimeNanos。
- time - TimeUnit.MILLISECONDS.toNanos(timeoutMillis) >= currentTimeNanos,如果事件轮询的持续时间大于等于 timeoutMillis,那么说明是正常的,否则表明阻塞时间并未达到预期,可能触发了空轮询的 Bug。
- Netty 引入了计数变量 selectCnt。在正常情况下,selectCnt 会重置,否则会对 selectCnt 自增计数。当 selectCnt 达到 SELECTOR_AUTO_REBUILD_THRESHOLD(默认512) 阈值时,会触发重建 Selector 对象。
Netty 采用这种方法巧妙地规避了 JDK Bug。异常的 Selector 中所有的 SelectionKey 会重新注册到新建的 Selector 上,重建完成之后异常的 Selector 就可以废弃了。
背景:Selector 的空轮询 bug
- 在 JDK 的部分版本里,
<font style="color:rgb(59, 67, 81);">Selector.select(timeout)</font>存在 bug:
即使没有任何事件,它也可能立即返回,没有正常阻塞到超时时间。 - 结果就是:
EventLoop 线程会疯狂地“空转”,CPU 飙升到 100%,但又没干实事。
👉 如果发现 <font style="color:rgb(59, 67, 81);">select()</font>连续过早返回 512 次(怀疑 JDK 的 Selector 空轮询 bug),就会 销毁旧 Selector,重建一个新的,从而避免 EventLoop 陷入死循环空转。
正常情况:无事件会在阻塞一段时间,异常情况:立即返回
任务处理机制
- 处理普通任务
Netty 高性能内存管理设计
认识jemalloc
前言
netty的内存管理也是参考jemalloc的设计。
内存分配器:jemalloc,temalloc,ptmalloc
他们都有一个目的即:提高内存分配回收的效率,以及尽可能地减少内存碎片
内存碎片:
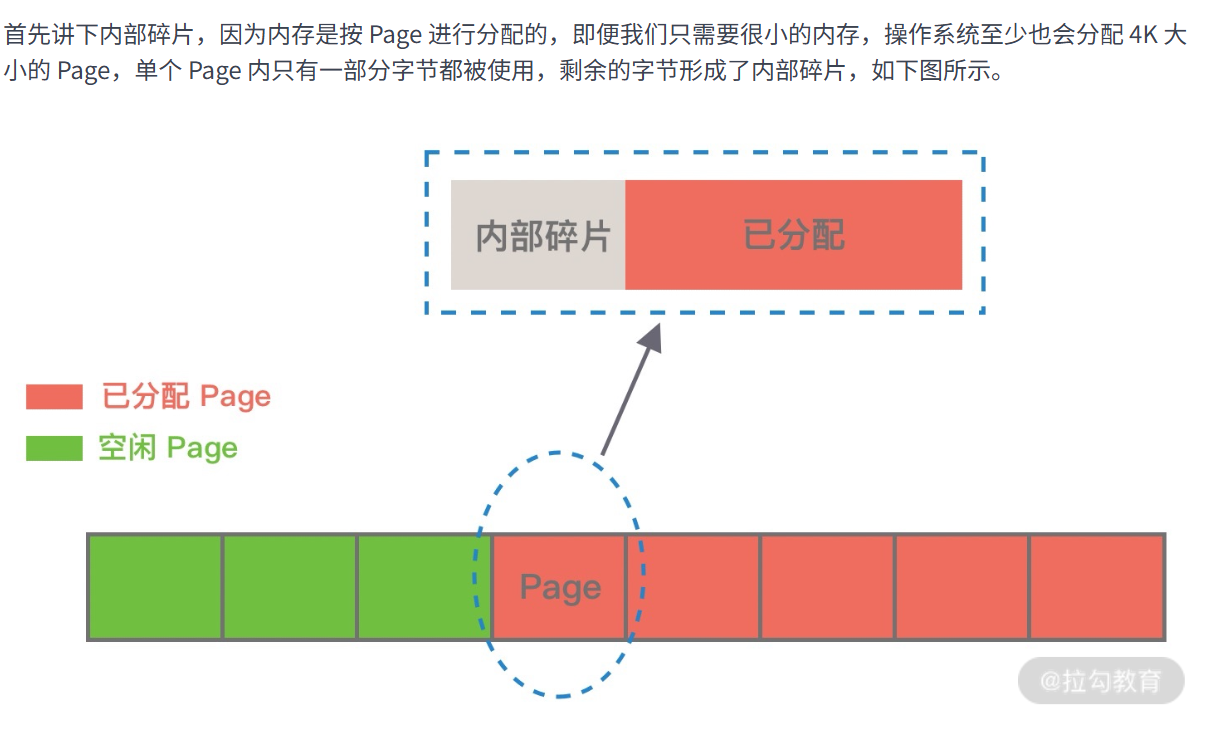
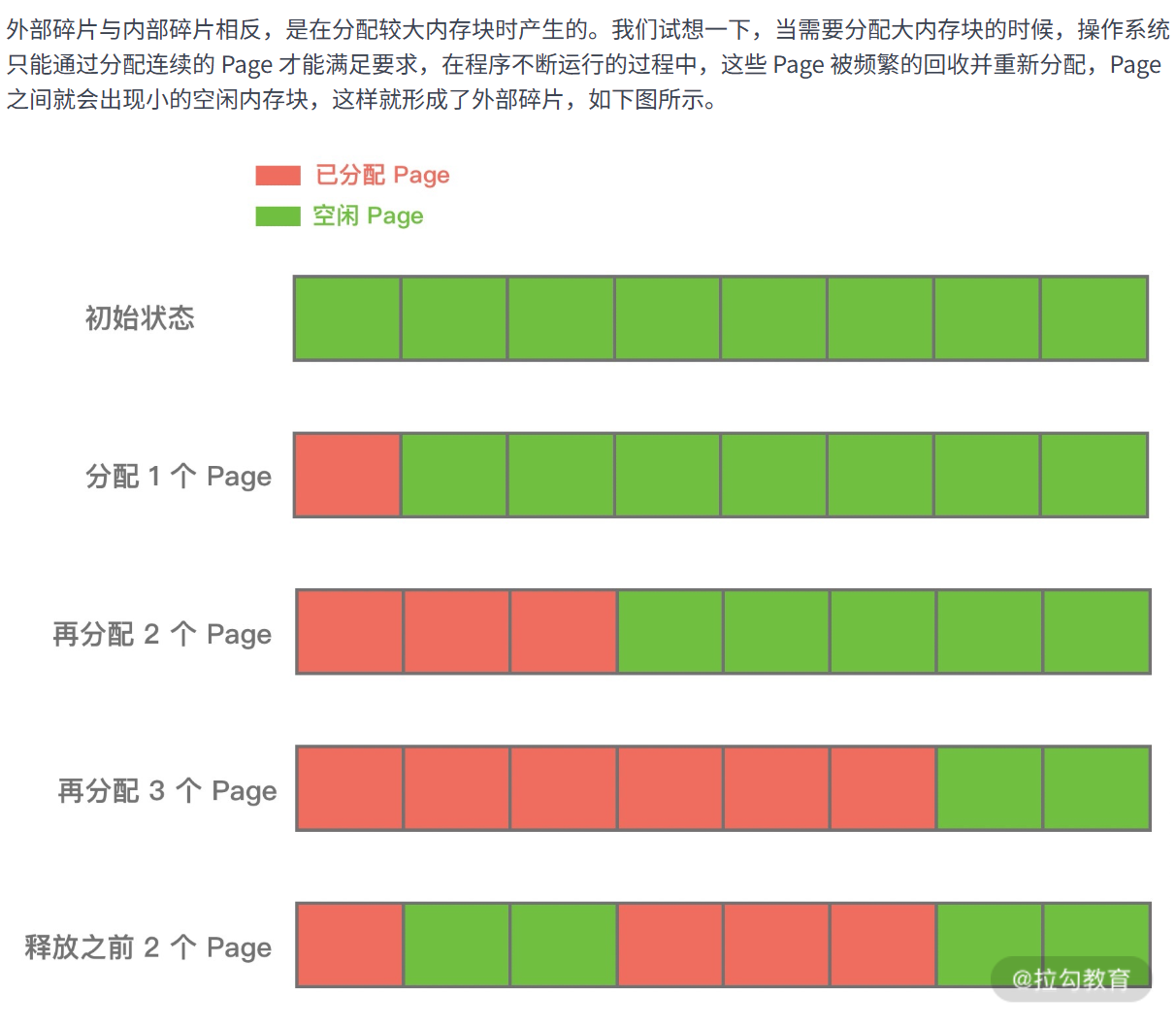
Linux会把物理内存分配为一个个4kb的内存页,
物理内存的分配和回收都是基于 Page 完成的,而页里面产生的碎片成为内部碎片,而页与页之间
叫做外部碎片
内存分配算法
三种。动态分配,伙伴分配,slab
动态分配
动态分配DMA
会用一个链表来维护空闲内存块,程序申请内存时就从这个链表里面挑选
- 内存就像一个大仓库/超市。
- 空闲分区(free block) = 货架上的空篮子(还没被进程用的内存)。
- 进程的请求(malloc 申请内存) = 顾客来装东西(要一块内存)。
- 分配策略(first fit / next fit / best fit) = 超市员工怎么选篮子给你。
三种算法

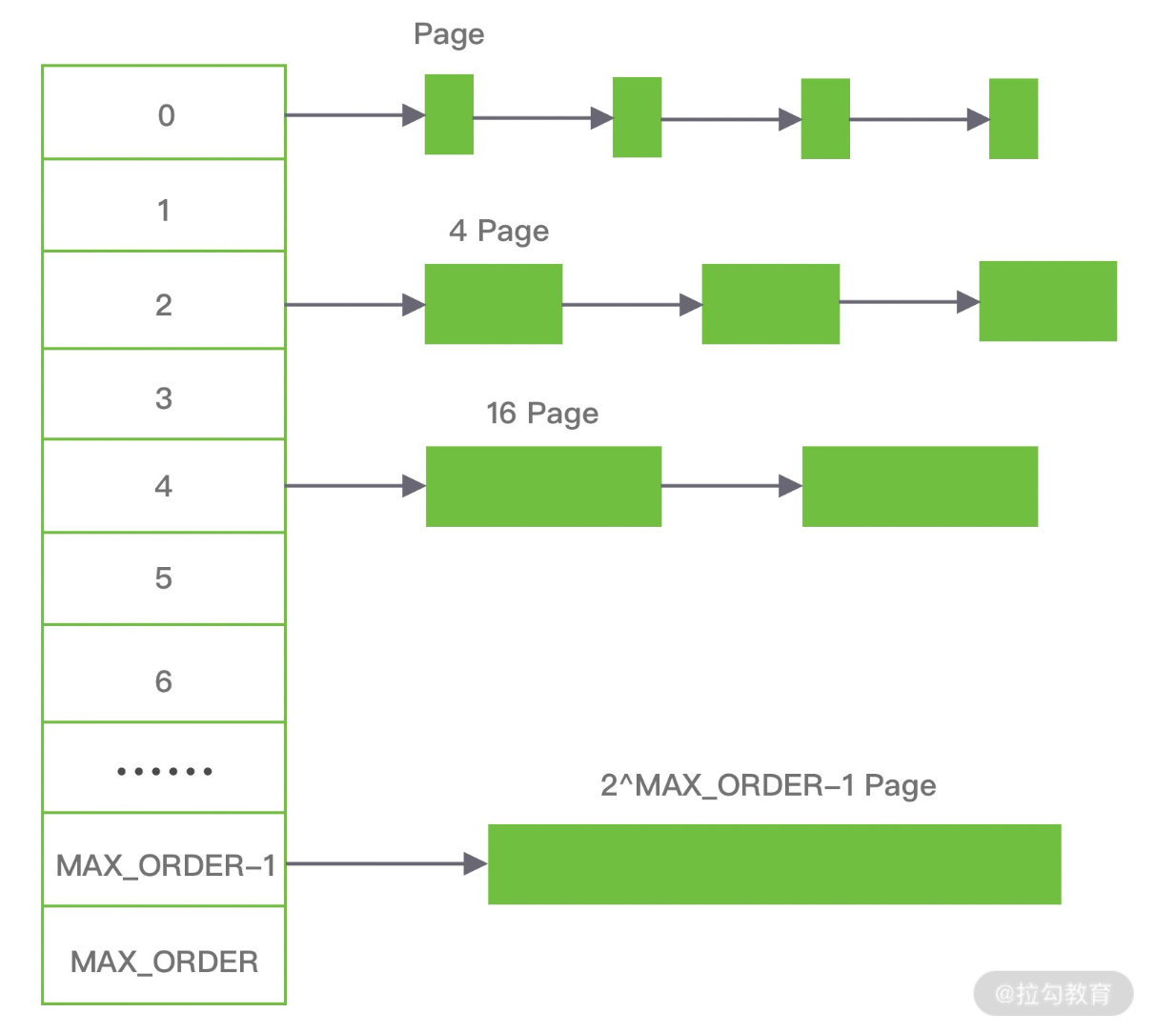
伙伴算法
伙伴算法就是把内存分成 2 的幂次方大小的块,按需拆分、按对合并,分配快、回收快,但会浪费一些空间(内部碎片)。
比如你分配17kb的,就得申请32kb的
slab算法
Linux 内核使用的就是 Slab 算法
jemalloc架构设计
netty的实现
基本使用

设计原则
Netty 高性能的内存管理也是借鉴 jemalloc 实现的

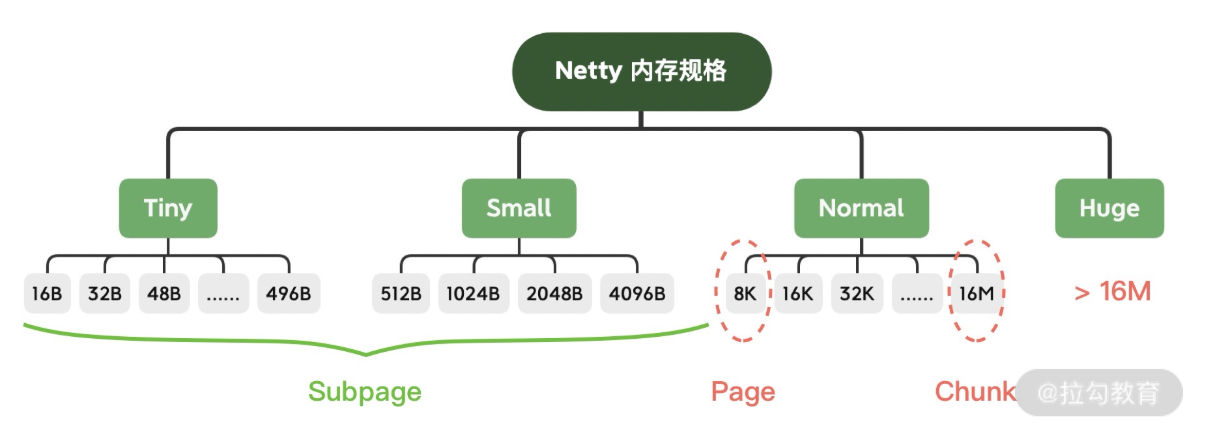
内存分规格
tiny,smaller,normal,huge
当想要申请的内存大小大于huge时,netty是会采用非池化的手段
netty的核心组件
可以看做是jemalloc的Java版实现
PoolArena也就是jemalloc的arena,
1 | Class PoolArena{ |
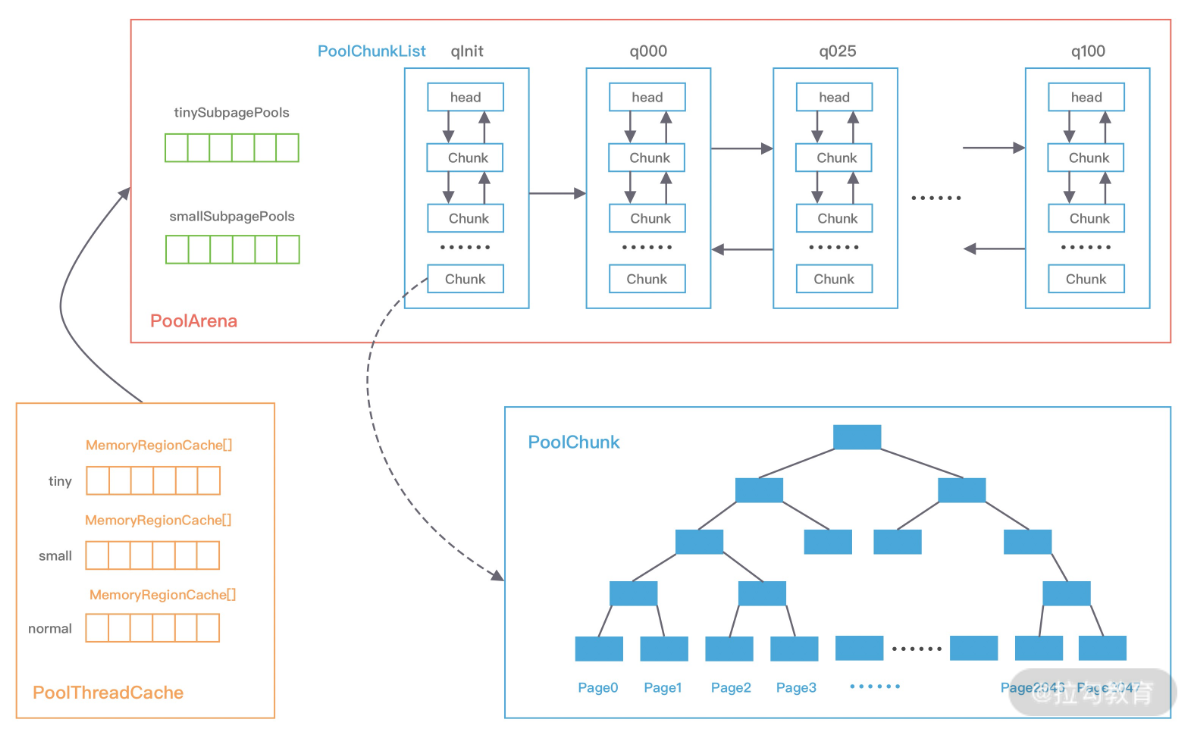
采用固定数量的多个 Arena 进行内存分配,Arena的数量跟CPU核数有关。当线程申请时,就会给它分配一个Arena,且在这个线程声明周期内,线程只会更这个Arena打交道
Netty 借鉴了 jemalloc 中 Arena 的设计思想,采用固定数量的多个 Arena 进行内存分配,Arena 的默认数量与 CPU 核数有关,通过创建多个 Arena 来缓解资源竞争问题,从而提高内存分配效率。线程在首次申请分配内存时,会通过 round-robin 的方式轮询 Arena 数组,选择一个固定的 Arena,在线程的生命周期内只与该 Arena 打交道,所以每个线程都保存了 Arena 信息,从而提高访问效率。
PoolChunk:
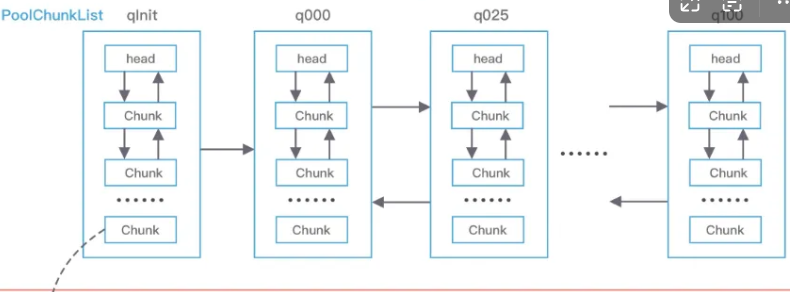
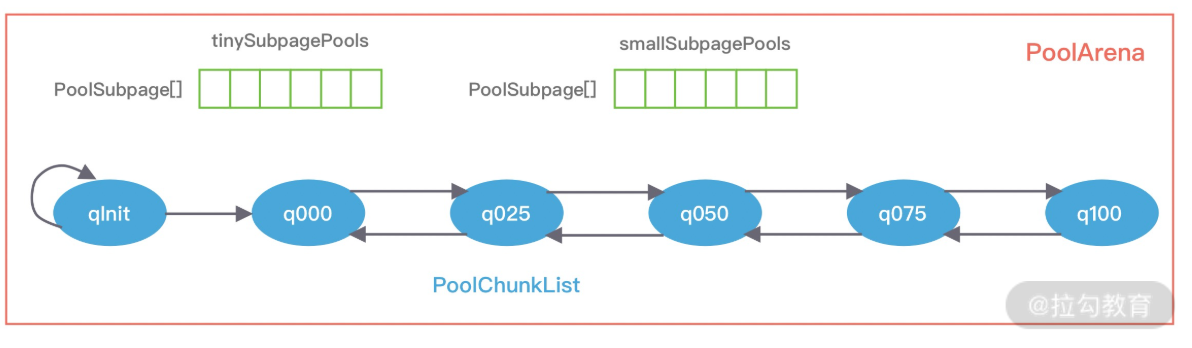
PoolArena 的数据结构包含两个 PoolSubpage 数组和六个 PoolChunkList,两个 PoolSubpage 数组分别存放 Tiny 和 Small 类型的内存块,六个 PoolChunkList 分别存储不同利用率的 Chunk,构成一个双向循环链表。
PoolArena 对应实现了 Subpage 和 Chunk 中的内存分配,其 中 PoolSubpage 用于分配小于 8K 的内存,PoolChunkList 用于分配大于 8K 的内存
随着PoolChunk的使用率变化,PoolChunk会在不同的PoolChunkList之间移动
分配流程

内存回收

面试回答
首先说下它整体是参考jemalloc –> 说说设计原则(分规格,就是有不同规格的内存块,以及实现了每个线程都有自己的内存) —> 列举下组件(poolArean,chunk,subpage,以及基础的分配单位page)–> 分配流程(先检查请求分配的大小是tiny还是smaller,然后检查PoolThreadCache是否够,如果够就使用自己线程私有内存,然后再进行Arena分配,最终返回一个Bytebuffer给 用户)