classSolution { publicinttrap(int[] height) { int leftMax=0; int rightMax=0; int r=height.length-1; int l=0; int res=0; while(l<r){ leftMax=Math.max(leftMax,height[l]); rightMax=Math.max(rightMax,height[r]); //哪边小先计算哪边,因为木桶效应,装水取决于短的那边 int water= leftMax<rightMax? leftMax-height[l++]:rightMax-height[r--]; res+=water; } return res; } }
classSolution { intres= Integer.MAX_VALUE; intsum=0; int n, m; int[][] dir = {{0,1},{1,0}}; // 只需要右和下
publicintminPathSum(int[][] grid) { n = grid.length; m = grid[0].length; dfs(grid, 0, 0, 0); return res; }
publicvoiddfs(int[][] grid, int x, int y, int currentSum) { if(x >= n || y >= m) return; // 越界 currentSum += grid[x][y]; if(x == n-1 && y == m-1) { res = Math.min(res, currentSum); return; } dfs(grid, x+1, y, currentSum); // 下 dfs(grid, x, y+1, currentSum); // 右 } }
publicintmaxAreaOfIsland(int[][] grid) { //bfs or dfs
//dfs for (inti=0; i < grid.length; i++) { for (intj=0; j < grid[0].length; j++) { area = 0; dfs(grid, i, j); res = Math.max(res, area); } } return res; }
publicvoiddfs(int[][] grid, int x, int y) { if (x < 0 || y < 0 || x >= grid.length || y >= grid[0].length) { return; } if (grid[x][y] != 1) { return; } if (grid[x][y] == 1) area++; grid[x][y] = -1;
dfs(grid, x + 1, y); dfs(grid, x, y + 1); dfs(grid, x, y - 1); dfs(grid, x - 1, y); } }
publicbooleanexist(char[][] board, String word) { visited = newboolean[board.length][board[0].length]; for (inti=0; i < board.length; i++) { for (intj=0; j < board[0].length; j++) { if (dfs(board, i, j, word, 0)) { returntrue; } } } returnfalse; }
publicbooleandfs(char[][] board, int x, int y, String word, int offset) { if (x < 0 || y < 0 || x >= board.length || y >= board[0].length) { returnfalse; } if (visited[x][y]) returnfalse; if (board[x][y] != word.charAt(offset)) { returnfalse; } if (offset == word.length() - 1) returntrue;
visited[x][y] = true;
booleanfound= dfs(board, x, y + 1, word, offset + 1) || dfs(board, x + 1, y, word, offset + 1) || dfs(board, x, y - 1, word, offset + 1) || dfs(board, x - 1, y, word, offset + 1); //回溯 visited[x][y] = false; return found; } }
classSolution { public int maxArea(int[] height) { //双指针 int l = 0; int r = height.length - 1; int res = Integer.MIN_VALUE; while(l <= r){ int h = Math.min(height[l], height[r]); res = Math.max(res, h * (r - l)); //把矮的给淘汰掉,因为要装,那么短的那表一定得尽可能长 if(height[l] > height[r]){ r--; } else l++; } return res; } }
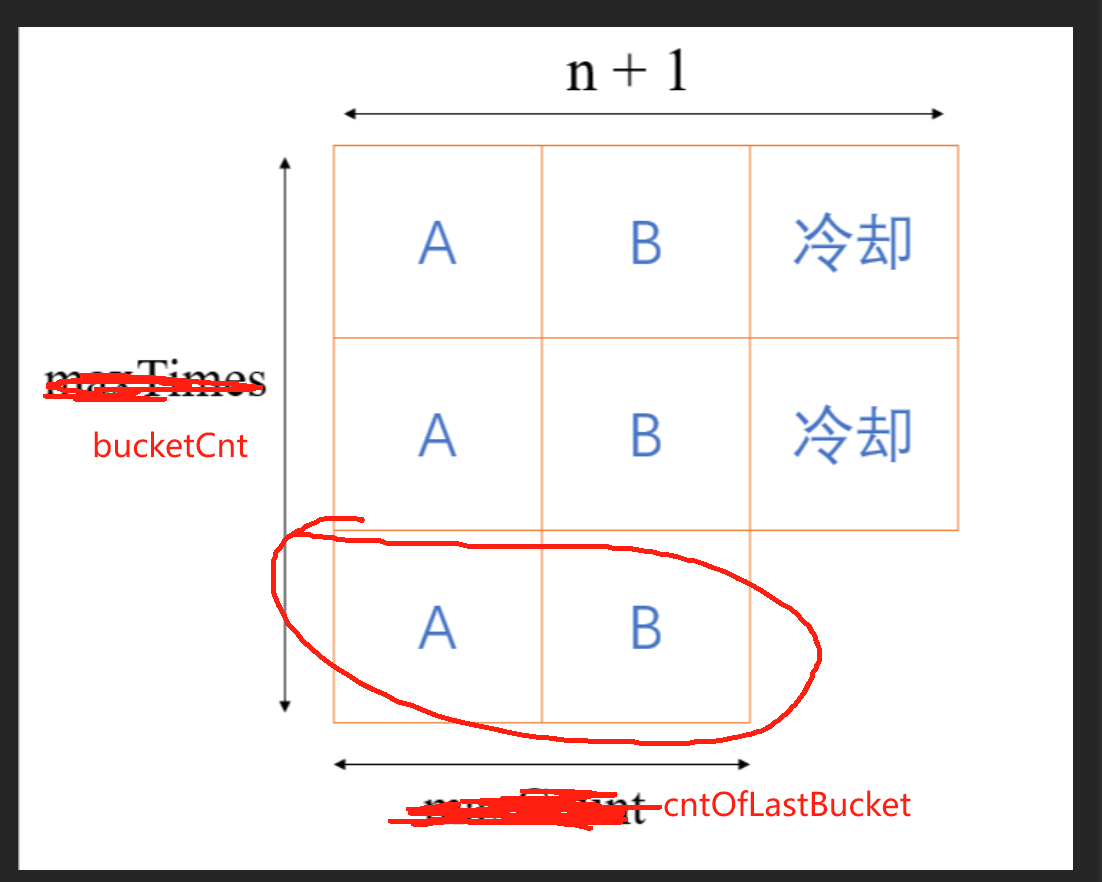
classSolution { publicintleastInterval(char[] tasks, int n) { //贪心:很容易想到就是 先安排出现次数最多的任务,然后让这个任务之间的间隔刚好为N Map<Character,Integer> counter = newHashMap(); for(char c: tasks){ counter.put(c, counter.getOrDefault(c, 0) + 1); } intmax=0; charcMax='*'; for(char c: counter.keySet()){ if(counter.get(c) > max) { cMax = c; max = counter.get(c); } } intbucketCnt= max; intcntOflastBucket=0; for(char c: counter.keySet()){ if(counter.get(c) == max) cntOflastBucket++; } //第一种情况:槽够用 //eg:A:4 B:4 C:1 D: 1 n = 2 //A B C //A B D //A B * //A B //则 完成时间不能等于 长度
//第二种情况:槽不够用 //eg:A:4 B:4 C:4 D: 2 n = 2 //A B C D //A B C D //A B C //A B C //则 完成时间等于 长度 return Math.max((bucketCnt - 1) * (n + 1) + cntOflastBucket, tasks.length); } }
这个案例就是借助滑动窗口算法来统计一段时间内的超时请求比率,如果超过了比率,那么就认为此时超时不是一个偶发性的问题,不应该继续重试。而后,为了支撑高并发的场景,滑动窗口算法可以借助 ring buffer 来实现,用一个比特来表达请求是否超时。同时可以用原子操作来进一步提高性能,因此你在这个案例下能够聊的话题非常多:


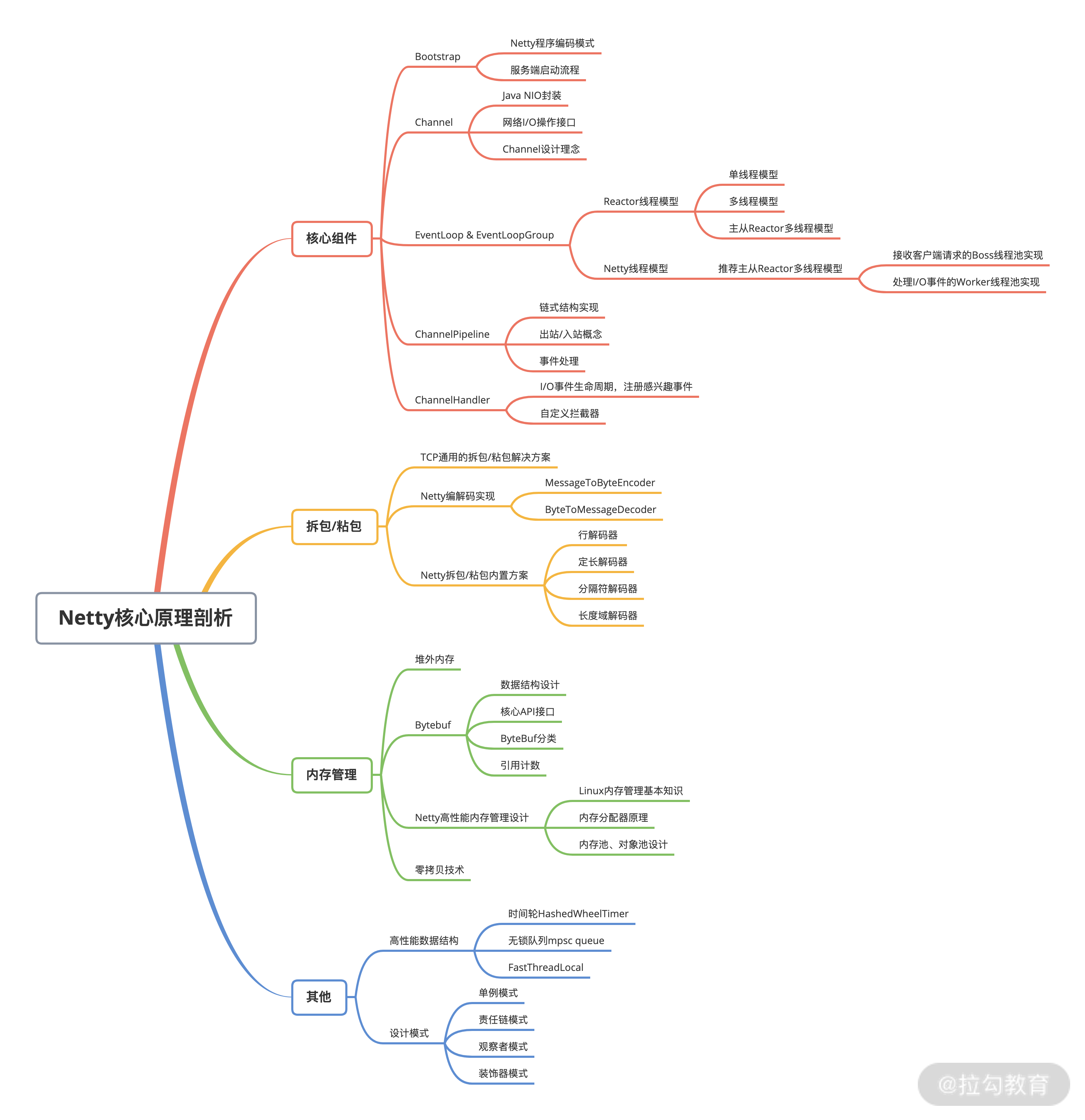
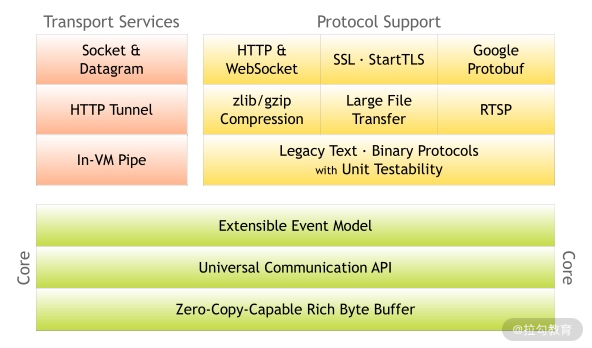
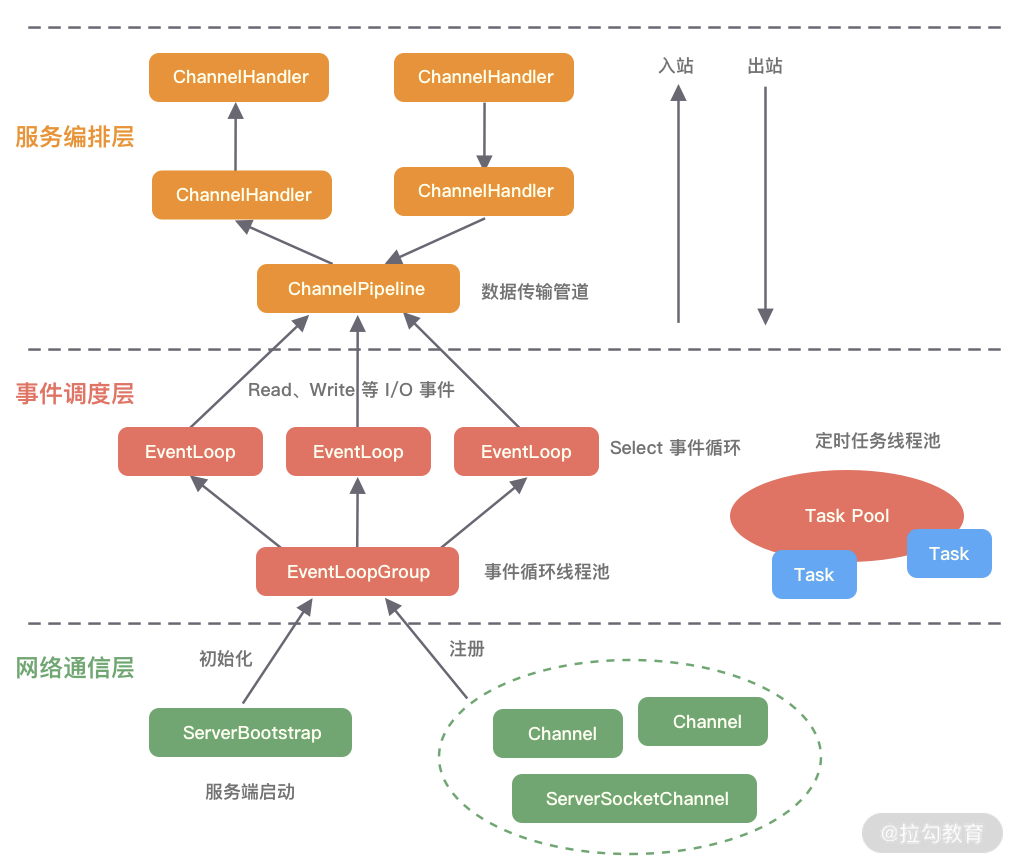
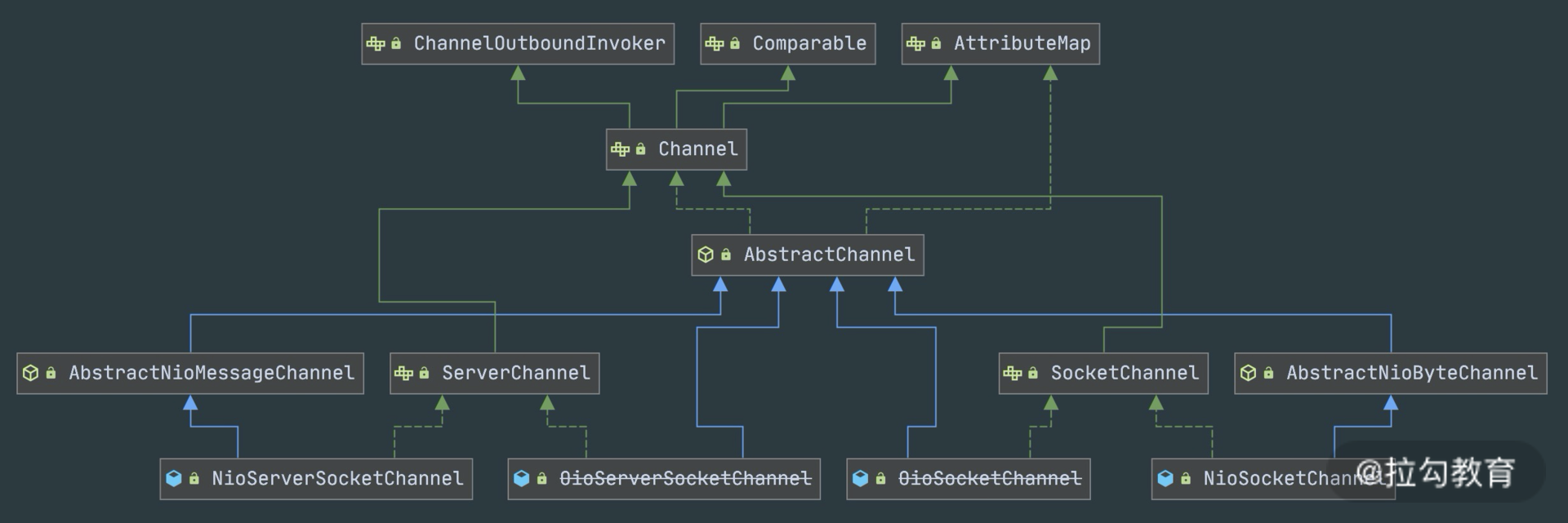
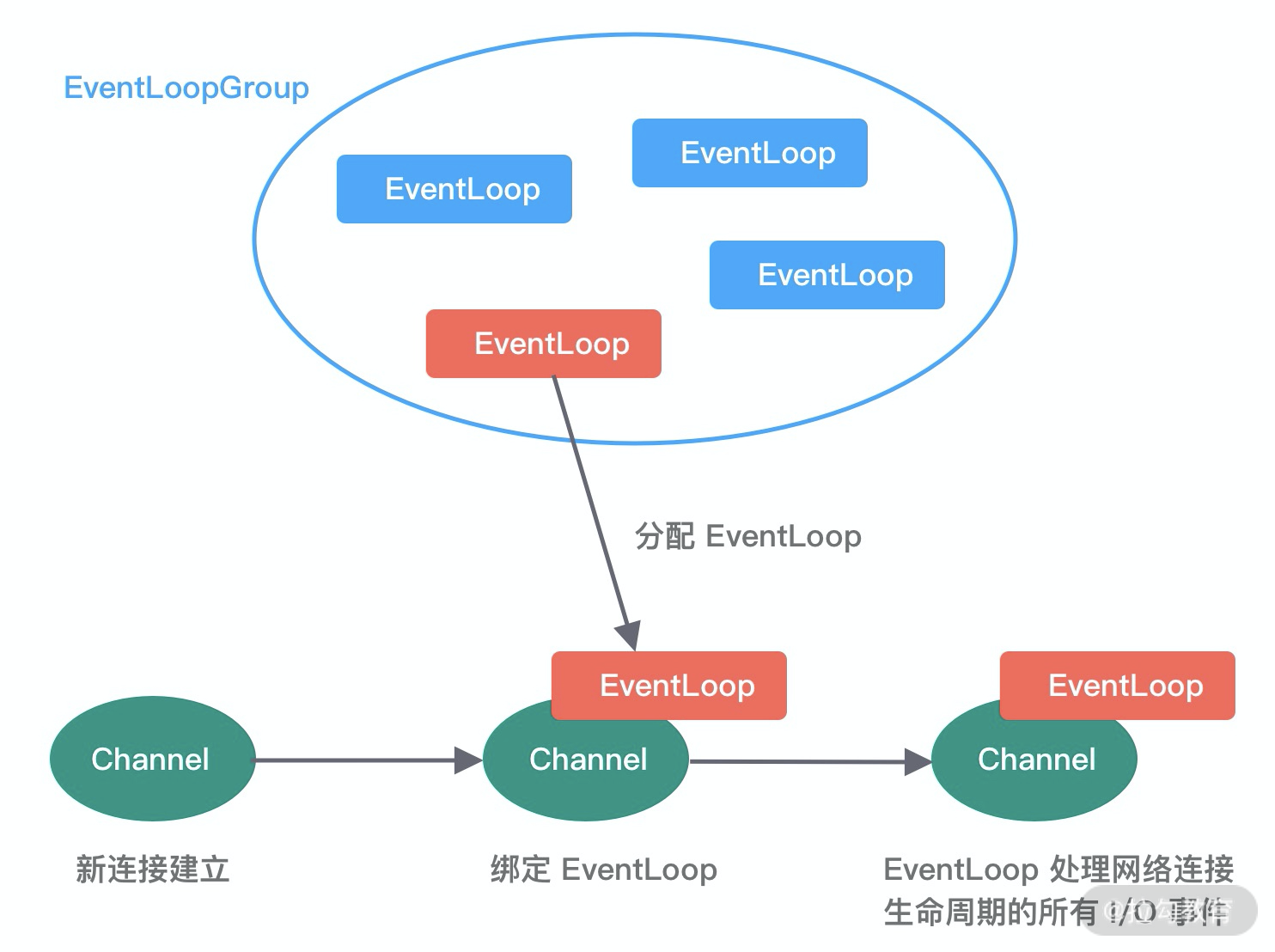
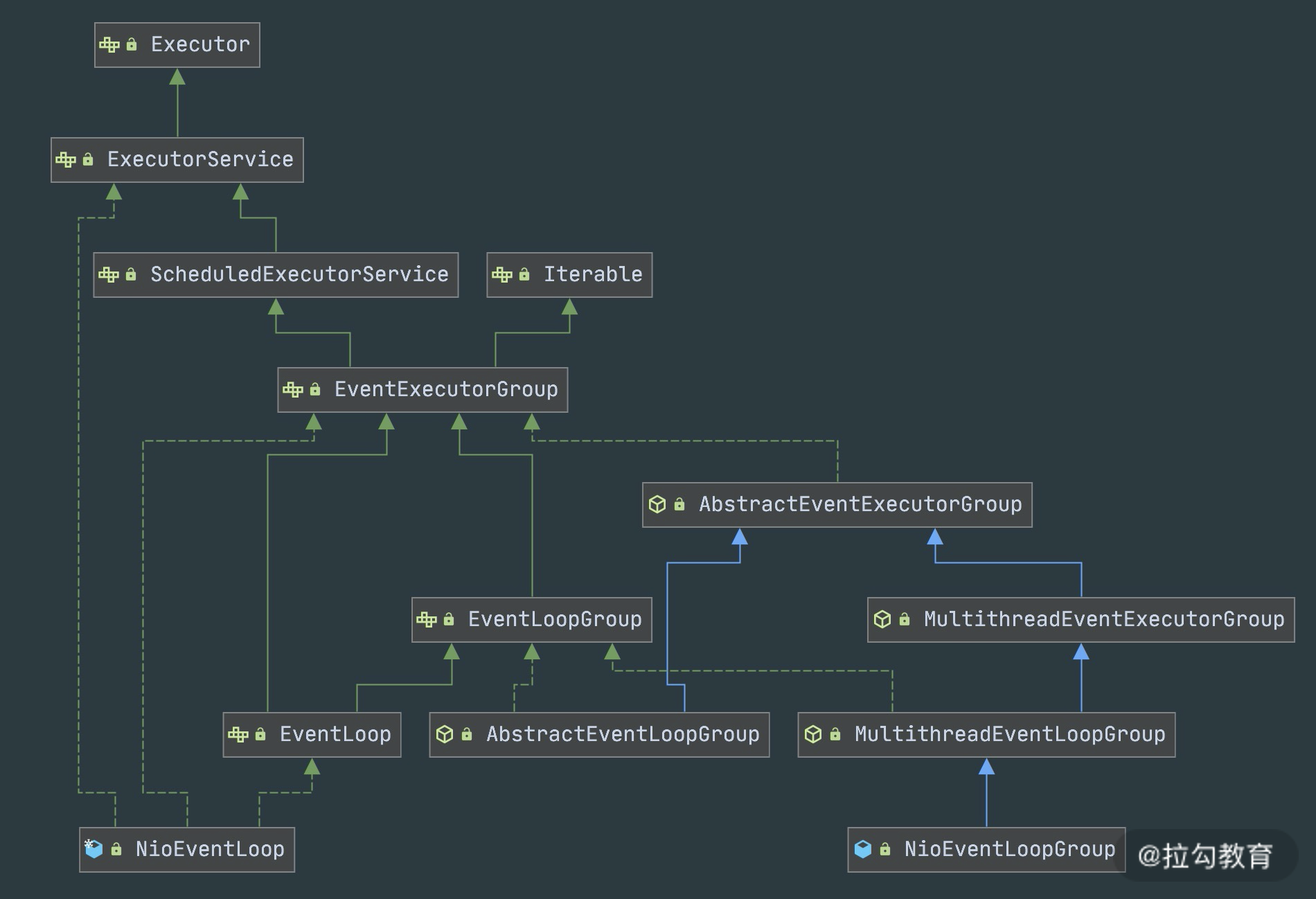
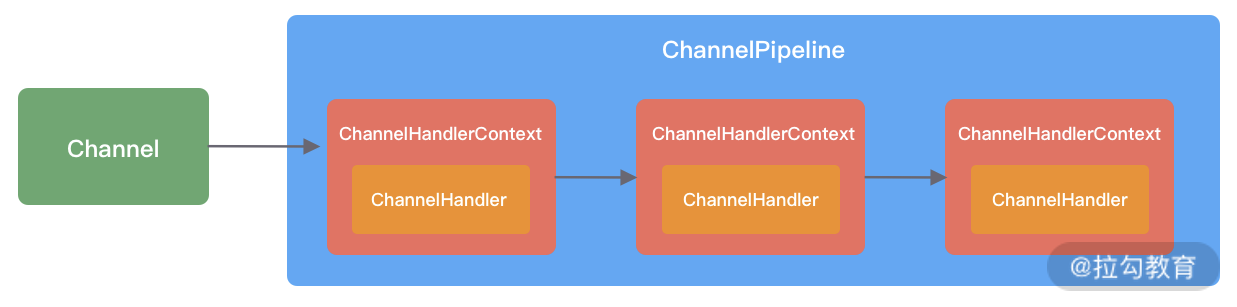
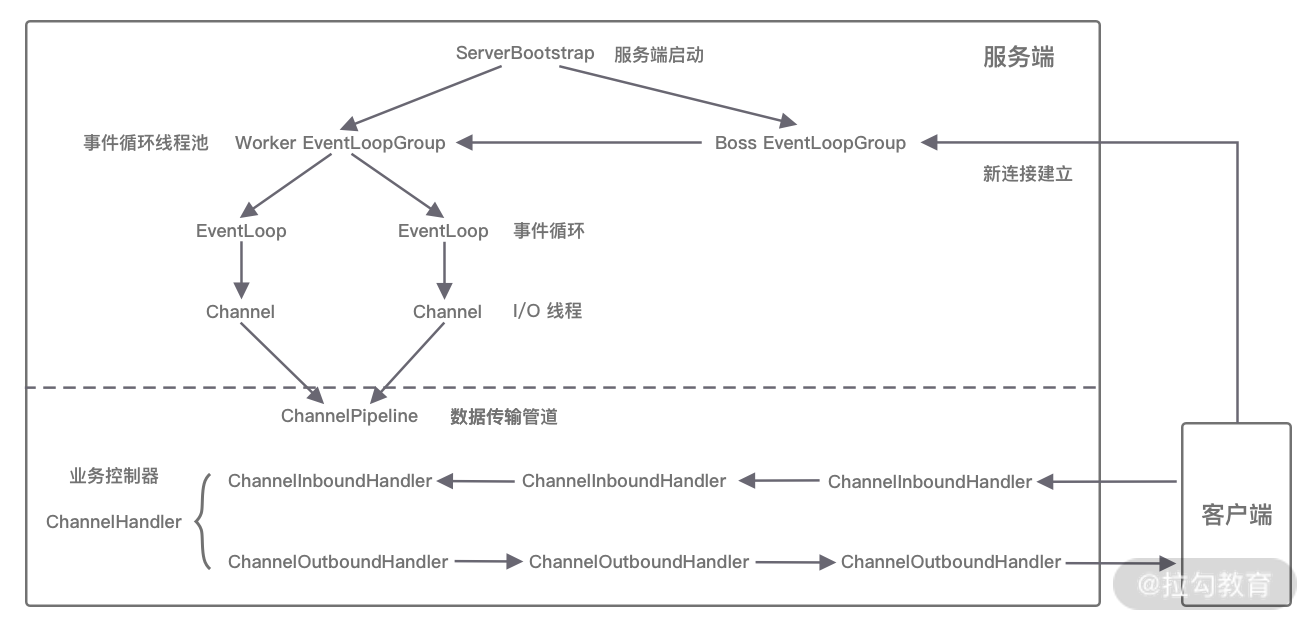
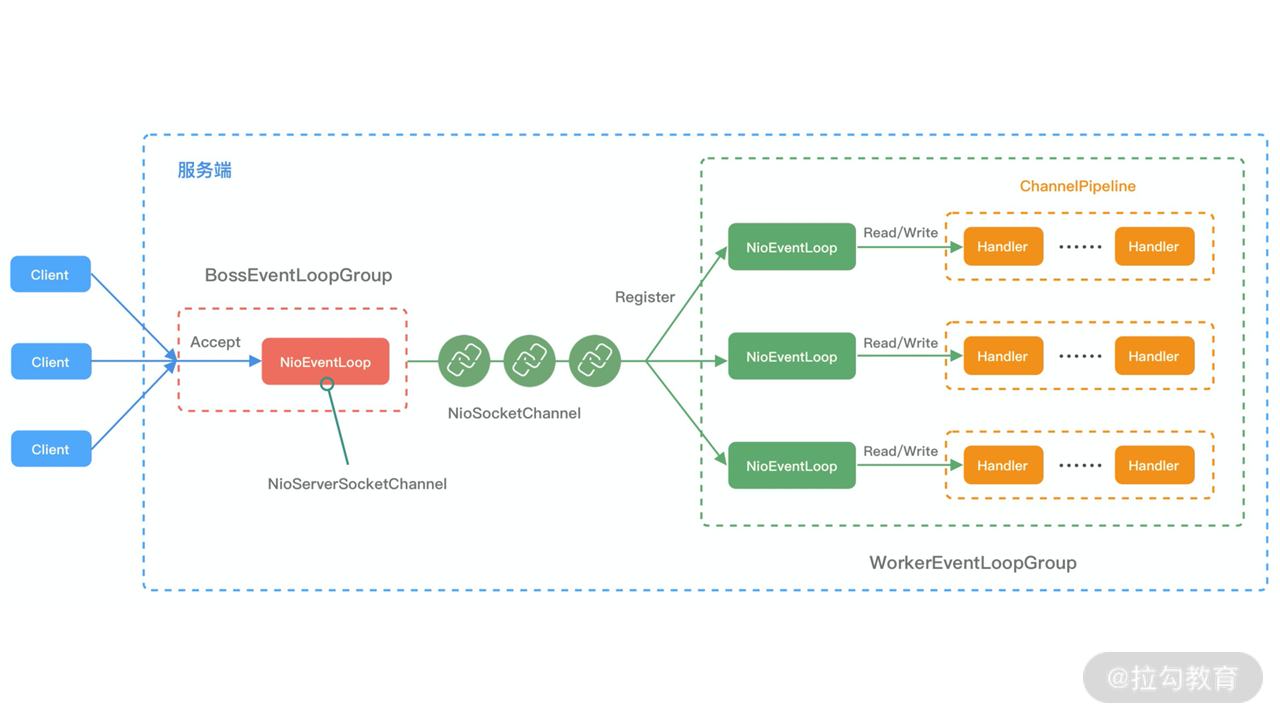 对于eventloop来说就是无锁串行化,不同eventloop之间是不会有交集的
对于eventloop来说就是无锁串行化,不同eventloop之间是不会有交集的