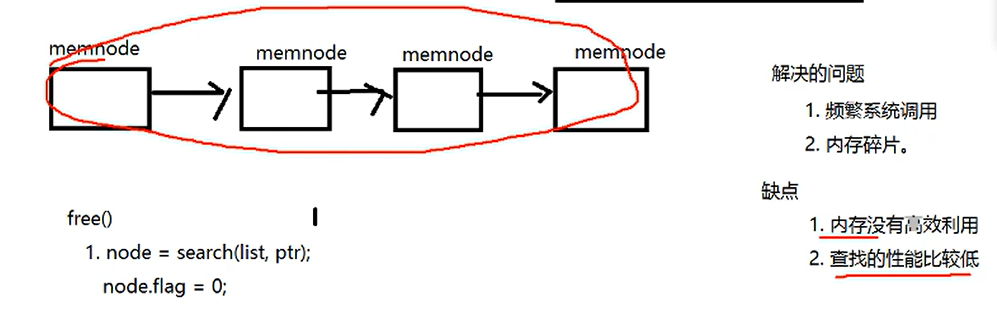
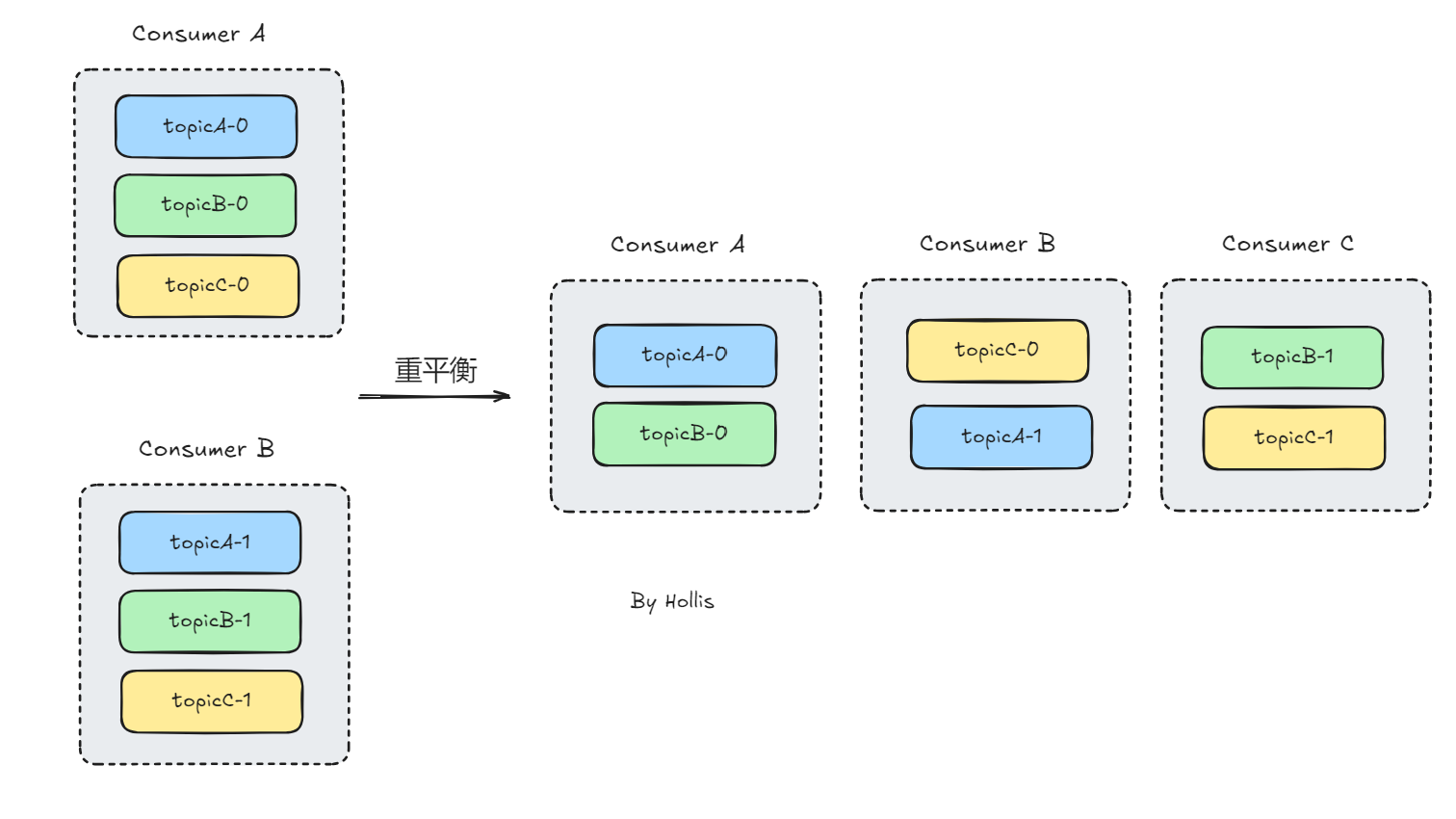
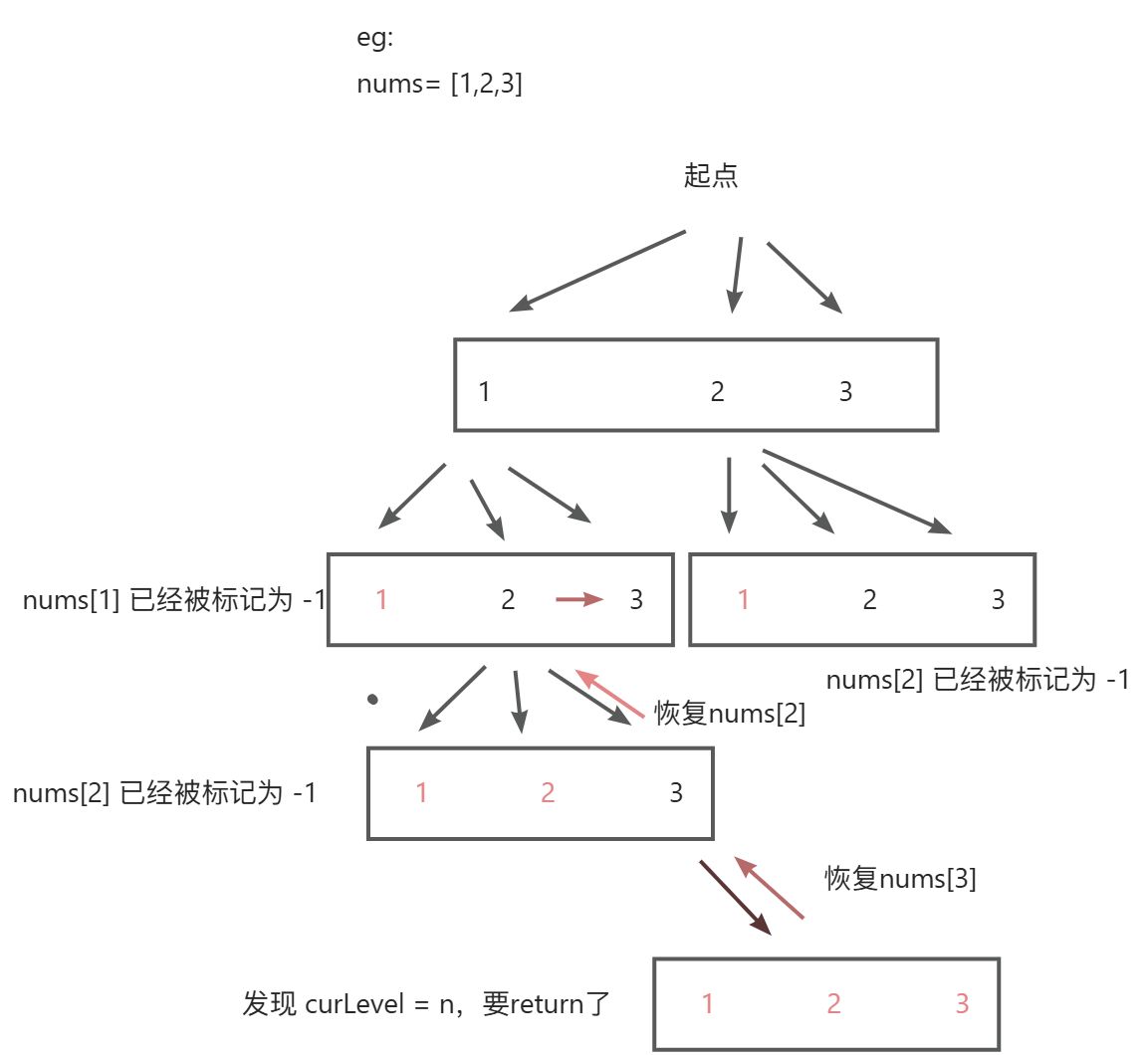
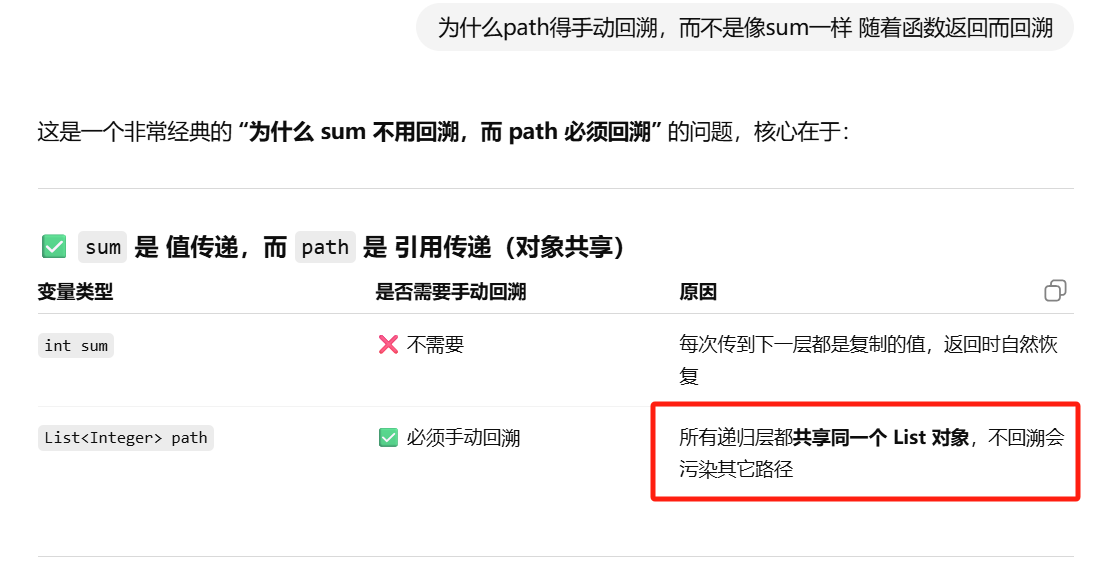
HW
高水平位,用于控制哪些消息是对Consumer可读的。一个普通消费者只能“看到”Leader副本上介于Log
Start Offset和HW(不含)之间的所有消息。follower同步完消息后会更新HW
也就是说在HW之前的数据都是已经被所有的Follower所同步,比较安全
HW取自于所有follower副本的 LEO
LEO
Log End Offset。消息的末尾偏移,表示日志下一条待插入消息的位移值。比如当时log文件里有10条
日志,位移值从0开始,那么,第10条消息的位移值就是9。此时,LEO = 10。
follower故障:
follower长时间没和Leader同步,就会被提出ISR(follower同步集合)。待follower恢复后,会读取本地的H
W,然后截取Log上大于HW的部分,进行同步。当该follower的LEO大于HW,即代表follower追上Leader就
会重新加入ISR
Leader故障
Leader故障后,由Controller从 ISR中选取一个follower成为新的Leader。之后为了保证多个follower副本数
剧一致性,其余的follower会将log中高于新Leader的LEO的部分截掉,然后从新的Leader同步数据
比如一个Leader现在有 3个follower,F1:读到了3,F2:读到了5,F3:读到了4。此时HW=min()=3
然后这时候Leader宕机了,F1成为了新的Leader,F2就会丢弃3-5的消息,F4丢弃4-5的消息
那如果F2成为了Leader呢?F1和F2就不会丢?