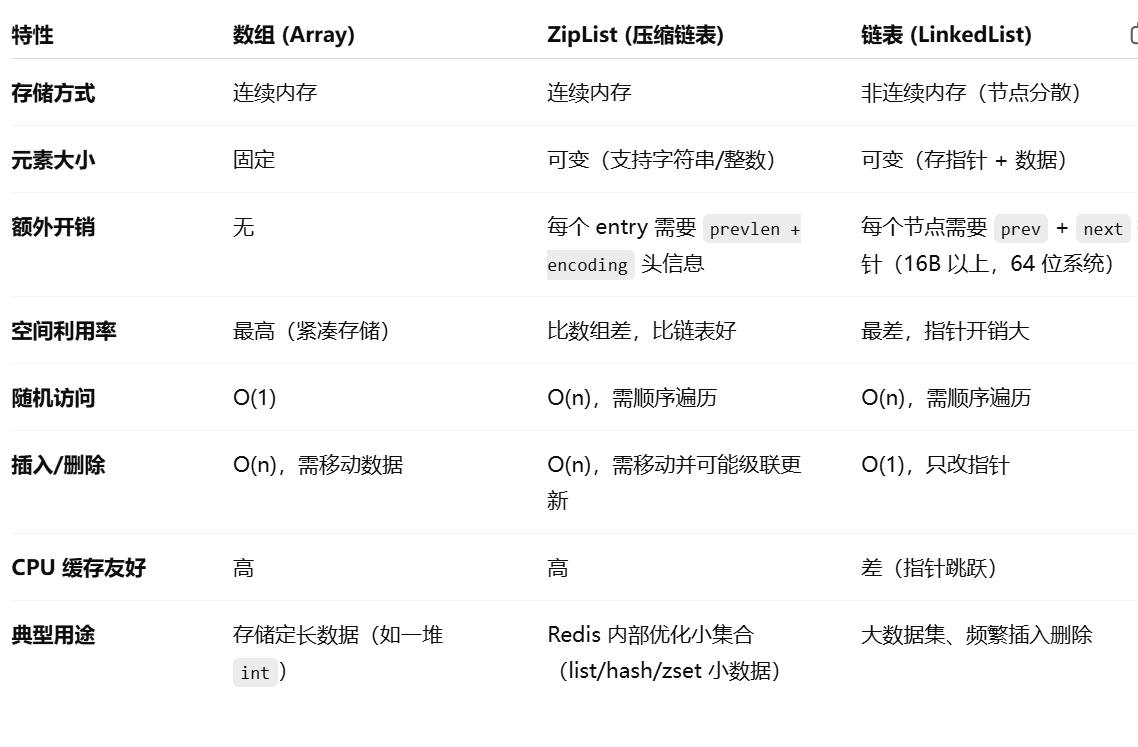
redis实现悲观锁
如果实现比较简单的悲观锁。基于setnx和lua脚本,这个命令能保证了
加锁流程
set….nx这命令就是说只有当key不存在时才会插入成功,来模拟上锁流程
SET myLock uuid NX PX 10 # 设置过期时间,避免死锁
key:myLock
value:uuid 为什么不用线程ID呢,在分布式部署的情况下,线程ID会出现重复的
PX:设置过期时间,保证线程异常了无法执行解锁逻辑,锁也能自动释放
解锁流程
分为三步:拿到锁,判断是否为当前线程上的锁,释放锁
这三步不是原子性的,因此需要用lua脚本来保证原子性
如果持锁线程挂了怎么办?不会自动释放锁!
如果设置有效期,持锁线程a被阻塞,锁到期了自动释放,其他线程b获取到锁,a使用完后就会释放锁,但这个锁其实是b持有了,这就乱套了
如果添加锁业务标识,不是自己的锁就不释放,因为判断锁是否是自己的和释放锁是两个操作,如果两个操作中间出现了阻塞,仍然有错误释放的可能
那么用lua脚本保证原子性 ,这样是还不错的,但如果真出现了线程a阻塞,锁自动释放,b线程获取到锁,这就相当于临界资源可以进入多个线程了,所以我们最好是锁快过期了能自动续约时长,如果是线程挂了那就不续约了,直接走人。
就像去网吧上网,快下机了但还想玩,那就续费,如果人都直接回家吃饭了,网管肯定把你机子给其它人用了