select
- 取得连接,会使用到 mysql 中的连接器
- 还会经历 tcp 三次握手,因为 mysql 是基于 tcp 进行通信的
- 这个过程会校验用户名和密码是否正确
- 校验用户权限
- 查询缓存,key 为 sql 语句,value 为 sql 查询结果,不过在 mysql8.0 后被删掉了
- 更新比较频繁的表缓存命中率很低,因为只要一个表被更新了,该表的缓存就会被删掉,维护起来就很麻烦
- 分析器,分为词法分析和语法分析。词法分析就是提取 sql 语句关键字,语法分析就是校验 sql 语法,构建 sql 语法树,方便后面去读取表名,列名,语句类型
- 执行阶段
- 预处理
- 检查 sql 查询语句中的表 or 字段是否存在
- 把*扩展为表上的所有列
- 优化阶段
- 决定如何走索引
- 如何 jion
- 执行阶段:根据表的引擎定义,去执行这个引擎提供的接口
- 预处理
过期key删除策略
redis会把设置了过期时间的key放到一个过期字典里
定期:每隔一段时间从过期字典里随机取一批key判断是否过期,过期就“删除”
惰性:访问到已经过期的key时就直接删除
redis默认使用的是定期+惰性删除
redis默认每秒进行10次的过期检查,我们可以通过redis.config设置hz。随机抽取的数量是写死的
为20
且这个定期删除不会立马删,而是检测到某些key过期了,会把它放到一个List里,但redis的内存使用率
达到某个阈值后再统一删。
还有就是,被删除的过期key原来占用的空间并不会立马被操作系统回收,而是会标记为可重用的内存,
以此来提高性能。(毕竟向系统申请空间or回收是很耗性能的)
如何设置过期时间
expire
pexpire
expireat
pexpireat
或者在设置字符串时也可以一起设置:
set ex,set px
查看key的过期时间 ttl
内存淘汰策略
只有内存满了才会执行
如果从淘汰的对象角度来说的话:
针对所有key
针对设置了ttl的key
如果从淘汰的算法角度来说
LRU
LFU
随机选一个删除
不删,直接返回错误信息
如何配置
通过redis的 maxmemory-policy参数来指定
如何选择?
参考过一些大厂的配置建议
比如腾讯
它是根据redis的使用情况来考虑的,
若你redis当缓存的话,就设置allKeys-lru。会把最近最少使用的key删掉
若你redis当半持久化or半缓存使用,可以使用volatile-lru
不过像腾讯云的redis云产品默认的是不删除
阿里云默认的是volatile-lru
LRU变种实现
redis事务
Redis中的事务,multi表示开启一个事务(类似MySQL中的begin),然后执行一系列命令(放入队列中,提交后依次执行),exec提交(类似MySQL中的commit)
原子性:Redis中的事务不满足原子性,如果命令中有错误指令,如自增一个字符串的key,提交事务后,其它正常的语句仍能执行,事务不会回滚
事务中读请求没有意义,返回值用不了,因为此时命令还没真正执行,只是放到了一个队列中,exec提交后才真正执行;而MySQL开启事务后执行指令,那是真正实打实的执行的
既然不能在事务中读(没有意义),那就得在事务外面读,然后开启事务,再进行写操作,但这样无法保证读+写的原子性,可能读完后,事务提交前有其它连接更改了数据,解决方案:
- watch命令,用来盯住一个到多个key,如果这些key在事务期间:
没有被其它客户端修改,exec能成功
被其它客户端修改,exec返回nil
例如:
1 | watch a b // 监视a b |
如果第一条指令到最后一条指令期间,有其它客户端修改了a或b的值,exec不会提交事务,返回nil
- lua脚本(2表示接下来的两个值是key,key后面的是参数,即a和b是key,500是参数)

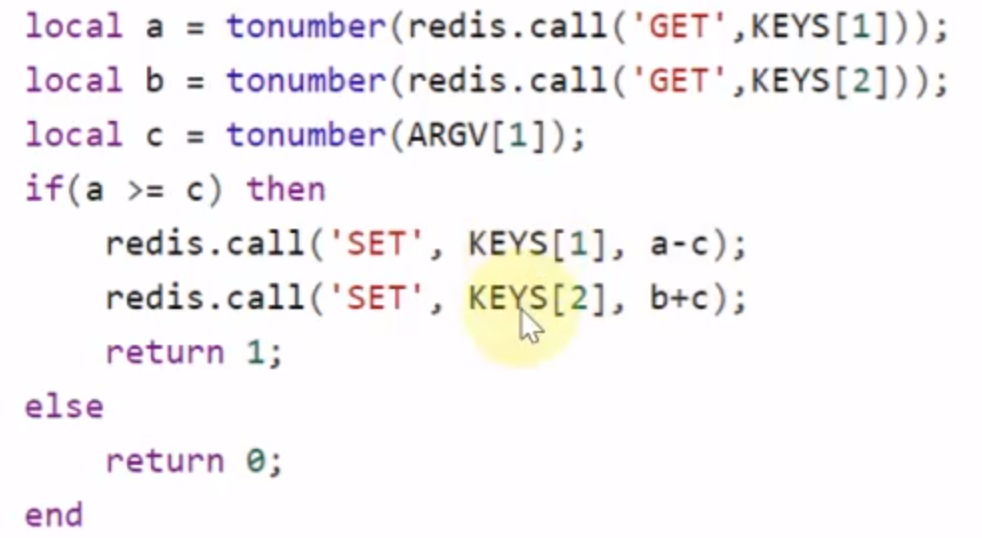
CAS
为什么要上锁?锁的本质是什么?
上锁的本质其实就是为了让资源能被正常的修改。为什么不上锁就不行呢?因为在JMM中,存在
着共享内存以及线程私有内存的,线程不是总会把私有内存里的资源立马加载到共享的,存在着时间
差,也就导致了覆盖的问题,此时就是我们常说的线程不安全。这时候我们使用ReentrantLock or · synchronized去包住一段代码,保证 同一时间内只会有一个线程去操作里面的资源,即使不会立马同步
到共享内存,也不会有其他线程来竞争。而且只要代码执行出了锁的范围,就会立马同步到主存
这里的资源是指堆内的,即成员变量
可以看到synchronized和ReentrantLock锁的是比较大的范围,容易误伤
所以我们可以把锁的范围降低,同时并不总是一直会有 对共享资源的访问和修改,我们可以基于一种乐观的
思想,比较资源的现有值和预期值,如果一致,说明没有人访问过,那么我直接修改
预期值和现有值是指什么?
比如一个对象里有个字段int a,我之前读出来,读出a是2,这个2就是预期值,那么我需要把他加10,更改为12,此时要更改了,我就看他的现有的实际的值,如果还是预期值2,说明在我读出来,再做运算,再到现在打算更改这个过程中,没有其它线程来修改,那么我就可以把它改为12。如果不是2,例如变成5了,那么实际值5,就和预期值2不一样了, 说明这段时间内有其它线程对其修改了,那我就不能动他,否则就产生覆盖了,因为我的12是基于2来计算出来的
即 一起竞争,谁快谁有理
CAS compare And swap 正是这样的锁,其实不只是锁了,更能说是一种思想。但其实也能说是一种锁,毕竟比较和交换这两步得是原子的。
cas基于cpu的一个原子指令来使其原子操作
cmp x chg:cpu执行这条指令时,会自动锁住总线,防止其他cpu访问共享变量;cpu同时自动禁止中断
同时硬件会保证对共享变量的访问是原子的
CAS存在的问题:
ABA,但说实在的业务上根本没有这个问题
CAS与悲观锁的区别:
- 粒度不同,CAS的粒度是针对一个变量的修改, 悲观锁的粒度是一段代码块
- 思想不同,CAS是乐观的思想,失败了大不了再重试,悲观锁是悲观的思想,我就笃定会有其它线程干扰,直接上锁
- 场景不同,CAS适用读多写少,悲观锁适用读少写多
- 开销不同,CAS开销小,悲观锁开销大
有了CAS为什么还要volatile?
CAS只是原子修改,并不能保证可见性,修改完后,其它线程并不一定马上能看到最新值
三种持久化策略
AOF
ps:AOF的诞生是为了解决早期的RDB无法及时持久化的问题
redis执行写命令操作后,会把其命令追加到AOF文件里,AOF是文本格式文件,AOF持久化默认是默认关闭
AOF的刷盘时机有三种,具体是由config里的appendfsync 参数控制的
1.always:每执行一条写命令就写入一次(每次write,每次fsync)
2.Everysec:每秒执行追加到文件一次,会先将命令写到AOF对应的内核缓冲区,后每隔一秒再写入
磁盘中的文件(每次write,每秒fsync)
3.no:由操作系统来决定啥时候刷盘(每次write)
AOF重写
它这个就是说当AOF文件大小到达某些阈值后(可配置),会读取redis中的所有键值对,生成命令写入 新的AOF文件里,然后用新的替换旧的
目的:给文件瘦身,比如说一开始有set saki 69,set saki 91两个命令,重写后就只有set saki 91一条
命令了
为什么要用新的文件替换旧的文件,而不是直接覆盖呢
怕重写一般失败了,污染了旧文件
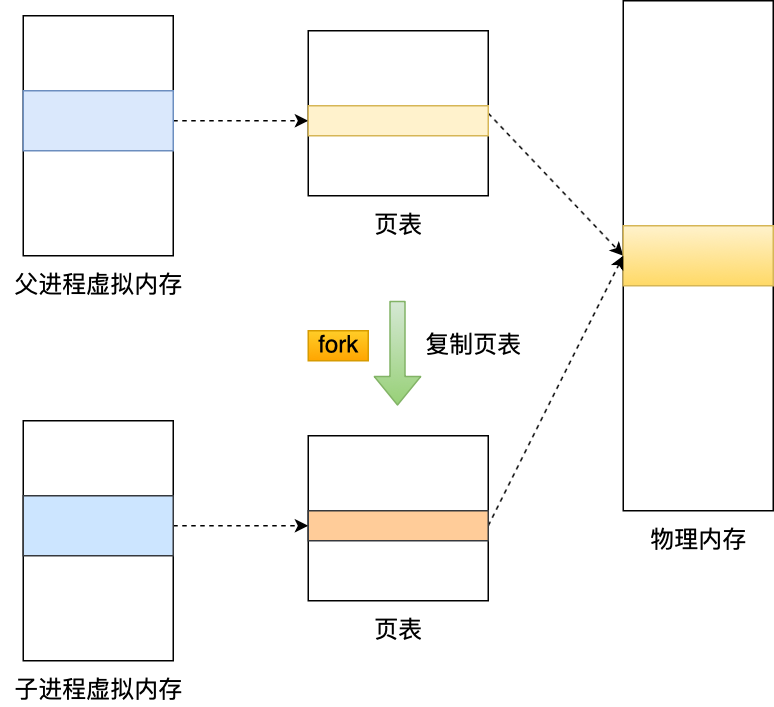
写入是在主线程执行的,因为写入的量不多。但重写是会fork子进程来完成的,这其中会把父进程的数据拷贝一份
….(待补充)
为了避免子进程在重写时,主进程的数据发生了变化,导致AOF文件里的数据和内存里的对应起来不一致。redis对其进行了一层优化,即将重写阶段新来的数据写入AOF的重写缓冲区里,等到AOF重写完成后,再把AOF重写缓冲区里的数据追加到新的AOF文件中。
RDB快照
RDB快照就是指记录某一时间段的内存数据,记录的是实际数据,因此在做内存恢复时效率是要比AOF高不
少的。
RDB可以直接读入内存就好了,不用像AOF那样需要执行命令
RDB是紧凑的二进制文件
RDB还提供了两种命令来生成RDB文件
save:主线程直接执行,会阻塞正常命令的执行
bgsave:操作系统fork子进程执行,可以避免主线程的阻塞
生成RDB时,不会保存过期的key
导入RDB时,主节点会对过期key进行过滤,而从不会
bgsave和AOF重写一致,都会fork子进程,但在bgsave期间新来的数据是不会被保存到此时的RDB的,只能等到下一次RDB
其他生成
正常停机时生成一次RDB
内部触发机制 比如save/bgsave 91 1:代表91秒内至少有1个key被修改,就RDB一次
redis默认的持久化策略:采用RDB
save 900 1
save 300 10
save 60 10000
appendonly no
注意:这个save不会阻塞主线程,**Redis 自动触发 ****bgsave** 来生成快照
4.x后的混合持久化
Redisson看门狗机制
原理
就是开一个定时任务,,然后每隔10s检查一次,并将其续约恢复至我们设置的lockWatchdogTimeout(默
认是30s)
jvm挂了,看门狗会一直续期下去吗
挂了的话,不会一直续期的。看门狗是jvm线程,jvm挂了的话,会终止续期的
加锁线程挂了,但jvm没挂,看门狗会一直续期下去吗
看门狗线程本质就是一个守护线程,且这个线程是和加锁线程绑定的,或者说它续期会去判断加锁线程是否存
活,存活才会去续期
并非守护线程
源码解读
续期任务调度的实现
这个方法是为锁开启续期任务,且一把锁只会有一个续期任务!!!由第一个持有该锁的线程开启,后续第
n个持有该锁的线程只需要把threadId注册到一个concurrentHashMap里
为什么?
你续期任务本质就是一个开一个线程不断轮询,那一个线程配一个定时线程这显然是不合理的。肯定
是不合理的,只需要一把锁对应一个续期任务
1 | protected void scheduleExpirationRenewal(long threadId) { |
续期的实现
1 | /** |
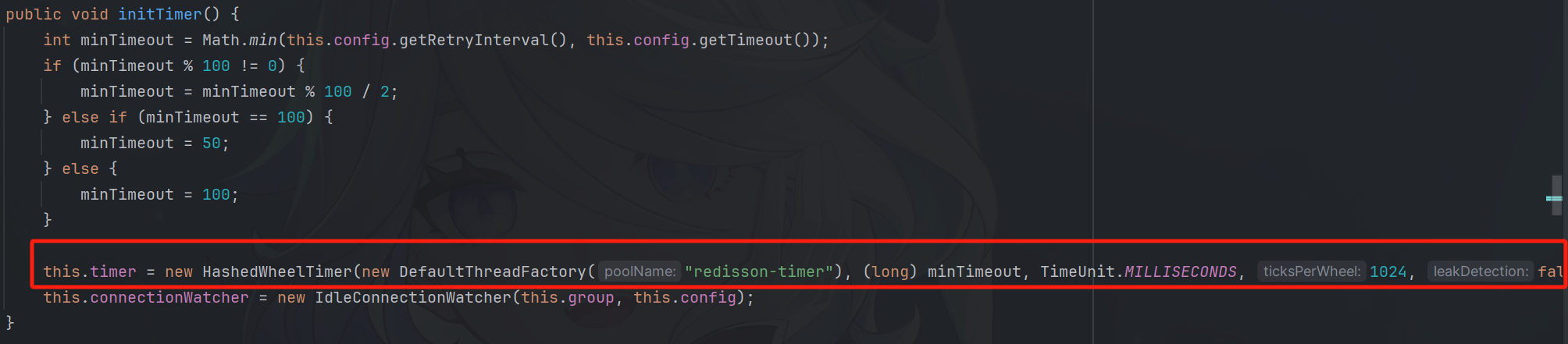
Redisson的定时任务是基于Netty中的时间轮来实现的
时间轮是什么?时间轮算法
Redisson执行定时任务的work线程
timer就是一个HashedWheelTimer(Netty的时间轮)
return 一个Timeout(表示你刚刚注册的这个定时任务,你可以通过这个timeout来查看任务状态等等)
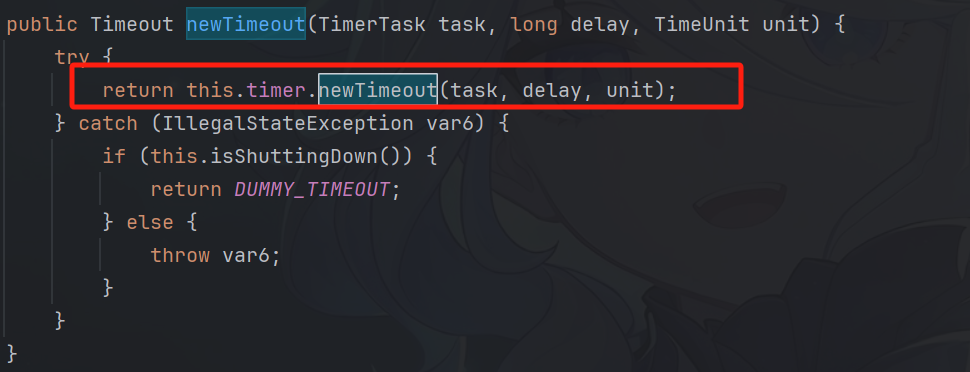
newTimeout:往时间轮里面 注册一个定时任务
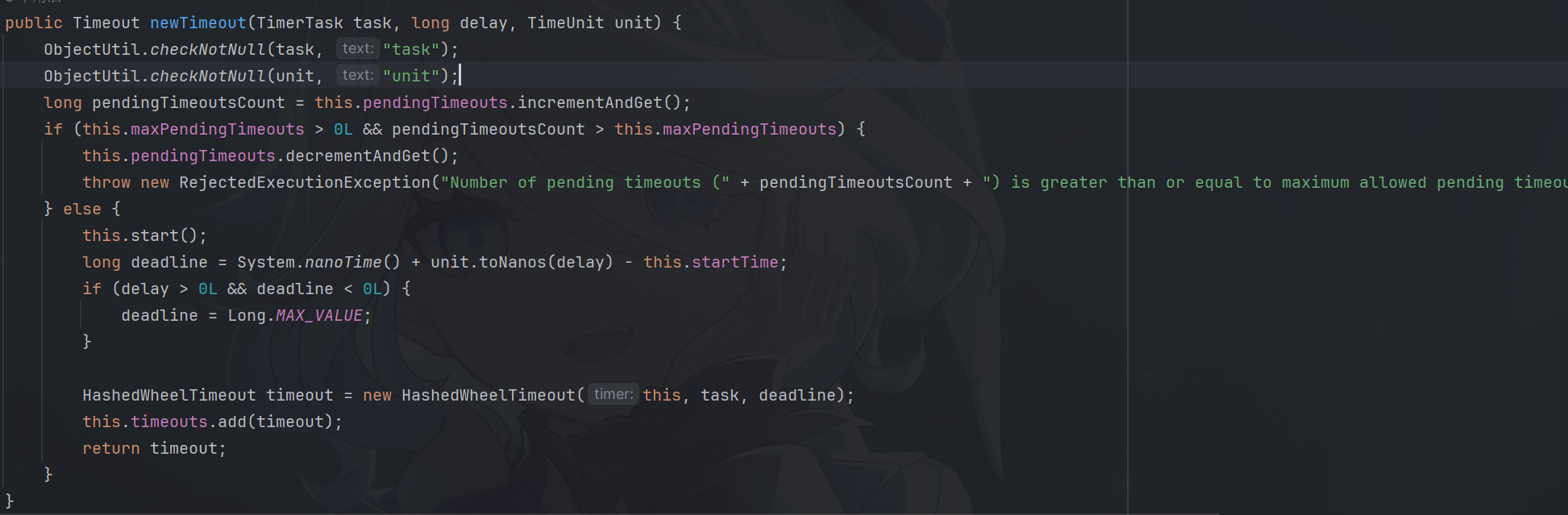
Redisson分布式锁
使用
两个常用API
tryLock:非阻塞锁,如果不设置waitTime的话,就直接return了
lock:阻塞锁,线程获取不到锁,会阻塞住
为什么基于lua脚本实现而不是事务?
两者都是可以保证原子性的,但
可重入锁?
redisson是基于redis的数据结构hash去实现可重入锁的。key为lock,field为线程名,value为count。这个
count就是用来表示一个锁被同一线程持有的情况
加锁流程:就是会先判断锁是否被当前线程持有或者说有没有线程持有,不是就表示加锁失败,是的话,就
count++;
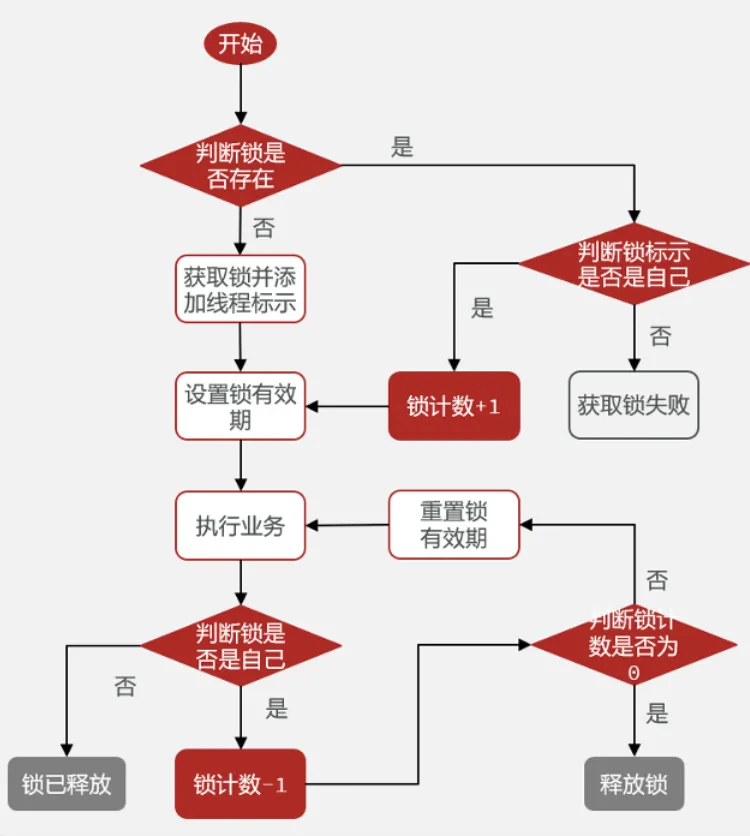
解锁流程:每次执行完毕就count–。直到count==0,就把其key删除掉,表示锁完全释放
加锁流程和解锁流程都是基于lua脚本实现的
不止hash结构?
1.字符串拼接,把count拼进去
2.redis那里还是使用string,服务内部通过concurrentHashMap保存:key为线程唯一标识,value为锁
计数器
1 | // 用于保存线程对应的锁和重入次数 |
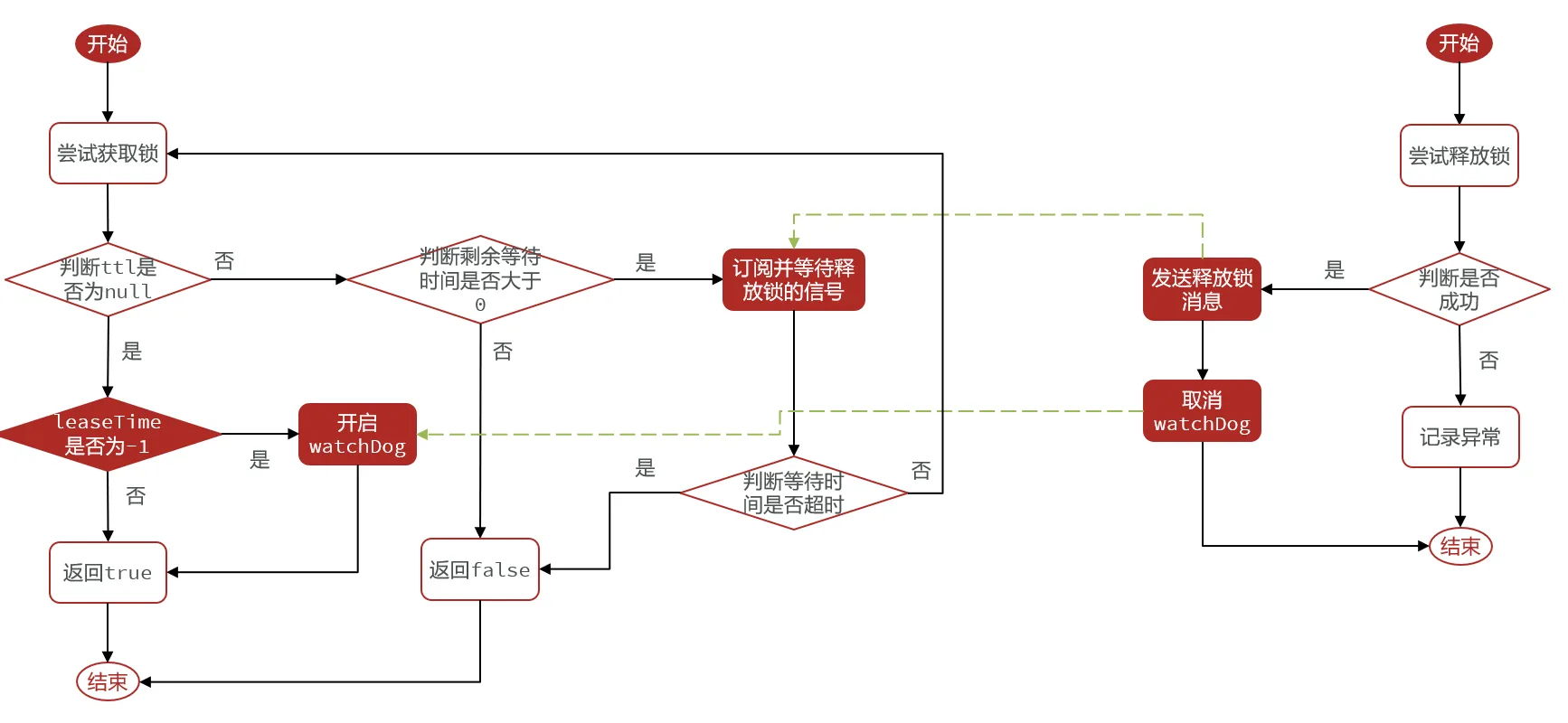
可阻塞锁,可重试锁?
Redisson的可阻塞锁是基于Redis的发布订阅模式来实现等待,唤醒,获取锁失败的重试机制的
获取锁失败不是直接重试or返回,而是订阅一下,然后等待
当获取锁成功的线程释放锁后,就会发布一条消息
其他线程就会收到这条消息,从而重新获取锁,获取失败就会继续等待
但也不是无限等待,超过一定时间,就不会继续等了,而是会返回false(针对于tryLock())
联锁?
对于分布式锁在主从架构中的锁丢失问题,Redisson提供了一种联锁机制。它要求Redis使用多主多从或者多
主,那么只有所有Redis主节点都上锁成功,才算上锁成功。这样的话,如果某个主节点宕机了,那么其他主
节点也是有锁的数据的,新线程想要给所有主节点加锁,那还是会加锁失败的
ps:主从架构中的锁丢失问题:当主节点setnx成功后,这时候来没来得及同步就挂了。那么这时候就会重新
选主,但这时候新的主节点是没锁数据的,服务器就会认为锁已经释放了,导致锁的互斥性失效了。
红锁?
但对于联锁而言,还可能会存在以下问题
1.所有主节点都得上锁,若某个主节点由于网络原因,导致加锁时间长,加锁失败
2.或者某个主节点宕机了,一直加锁失败
那么如果出现以上情况,就会导致一直加锁失败,失败概率很高,而且加锁失败后是要回滚所有Redis主节点
的数据的,性能很差的。
那么基于以上问题………………
Redis官方提供了一种红锁机制,也要求Redis要多主部署,但加锁时只要半数以上加锁成功就OK了。如果
当前线程加锁加到半数以上,那么其他线程就不可能加锁加到了半数以上了,那么这样就满足了互斥性
但redLock也是有很大问题的,
主要原因是Redis创始人不推荐在严格一致性的分布式情况下使用它
有什么可以替代的吗?业界无公认的方案
我个人的思考
1.使用单实例的Redis锁,虽然会有单节点故障
2.业务做好唯一性校验
3.使用强一致性组件来实现分布式锁,如zookeeper
分布式锁检验死锁?
观察看门狗线程,如果出现某两个看门狗线程存活时间过长,则这两个看门狗对应的分布式锁可能产生死锁