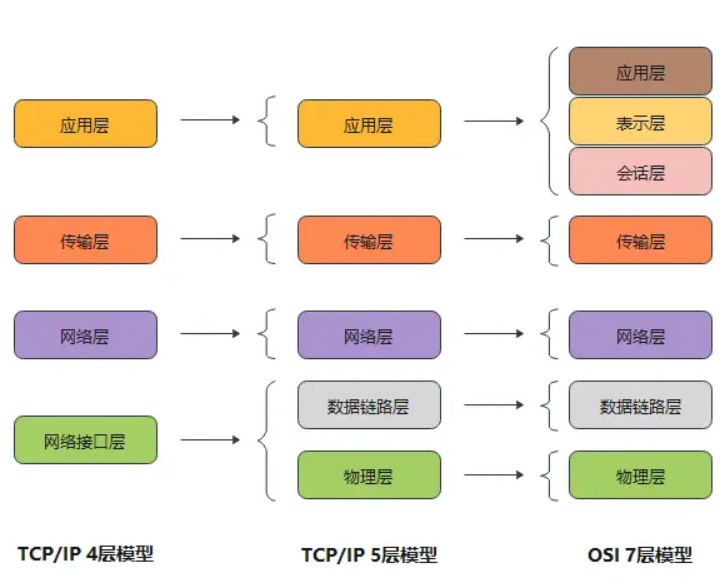
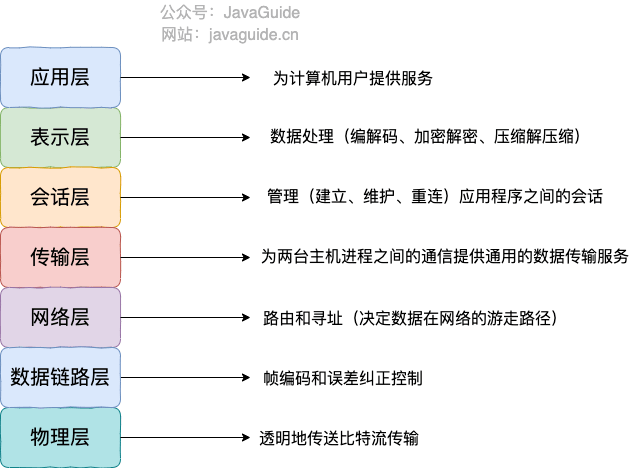
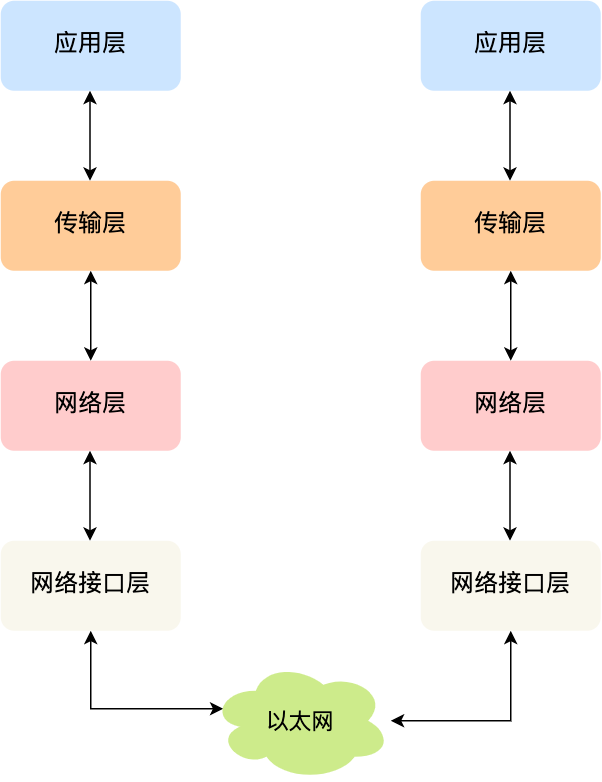
HTTP各个版本之间的变化
1.0和1.1
HTTP/1.1相比HTTP/1.0带来了多项改进:
首先,HTTP/1.1默认启用长连接,减少了TCP握手的开销,这对于频繁交互的应用尤其重要。
其次,在缓存控制方面,HTTP/1.1提供了更精细的Cache-Control头部,使得缓存管理更加灵活。
第三 HTTP/1.1 通过引入Host头部,支持虚拟主机,这使得多个网站可以共享同一服务器资源,降低了成本。
第四在错误处理方面,HTTP/1.1引入了更详细的错误状态码和描述,便于开发者定位和解决问题。
这些改进使得HTTP/1.1 的网络通信得到了极大的提升。
但是 HTTP 1.1 虽然有了很多改进,但是这并不是终点,因为 HTTP 1.1 依旧有很多缺点。
最显著的缺点就是请求阻塞,也就是当一个请求在等待服务器响应时,后续请求必须等待,即使它们与前面的请求无关。这导致了队头阻塞,降低了性能。
此外还有头部数据量太大,高并发下长连接容易成为性能瓶颈,并且 HTTP 1.1 是明文传输,不支持服务端主动发送数据等缺点。
所以在后续又引入了 HTTP 2.0,而 HTTP 2.0 则是进一步引入了多路复用,头部压缩 和服务器推送等功能,解决了 HTTP 1.1 的缺点。
1.1和2
HTTP/2.0相比HTTP/1.1带来了多项性能优化和效率提升。
首先,HTTP/2.0支持多路复用,允许在单个连接中同时发送多个请求和响应,解决了HTTP/1.1中的队头阻塞问题。
其次,HTTP/2.0使用HPACK算法压缩请求和响应的头部,减少了冗余数据,提高了传输效率。
第三,HTTP/2.0引入了二进制分帧层,将HTTP消息分解为独立的帧,提高了数据传输的效率和解析速度。
第四,HTTP/2.0还允许服务器主动向客户端推送资源,减少了客户端需要发送的请求数量,提高了页面加载速度。
最后,HTTP/2.0要求使用TLS进行加密传输,增强了安全性,防止了中间人攻击。
这些改进使得HTTP/2.0成为现代网络应用的首选协议。
HTTP/2.0虽大幅提升了性能,但仍存在依赖TCP导致的建连延迟和队头阻塞问题,且头部压缩复杂、明文传输风险未根除。
而HTTP/3.0基于QUIC协议,运行在UDP上,实现更快的建连和彻底解决队头阻塞,采用更高效的QPACK头部压缩,并强制TLS加密,全面提升了传输效率和安全性。
2和3
HTTP/2.0 和 HTTP/3.0 的区别,主要集中在底层协议、并行传输能力、握手效率、头部压缩、网络适应性等层面。
HTTP/2.0 是基于 TCP 的,一旦某个数据包丢失就必须等重传,这会造成整个连接里的所有数据流都被阻塞,也就是所谓的队头阻塞问题。HTTP/3.0 用的是基于 UDP 的 QUIC 协议,可以把每个数据流都独立分配 ID,只要某个流丢包,就只重传那个流,不会拖慢其它流,这在高丢包或弱网环境下会表现得更好。
HTTP/2.0 需要先完成 TCP 三次握手,然后再进行 TLS 握手,如果要恢复会话,也会多一次 RTT。而 QUIC 把传输层和加密层放在一起,相当于只需要一次握手就能建立安全连接,比 HTTP/2.0 快了大约一半。更进一步,QUIC 还支持 0-RTT 恢复,如果客户端保存过相关密钥信息,重连时几乎可以立刻发送数据,尤其在网络波动或需要频繁断网重连的场景下非常有效。不过,要注意 0-RTT 可能带来重放攻击风险,服务端通常要配合额外的安全逻辑做校验。
HTTP/2.0 使用 HPACK 来压缩头部,但它依赖顺序传输,对网络乱序的容忍度不高。而 HTTP/3.0 则是用 QPACK,在无序或丢包的条件下也能更好地解码头部,减少了因为乱序导致的性能损耗。
得益于QUIC使得HTTP/3.0在网络适应性上也更突出,它通过 Connection ID 来标识连接,这意味着用户从 Wi-Fi 切到蜂窝网络时,只要保持同一个 Connection ID,连接就能平滑迁移,不用重新握手下载证书。移动端在遇到丢包高或延迟大的情况时,QUIC 的拥塞控制也能更适配弱网环境,实现更流畅的体验。
总而言之,HTTP/3.0 的确代表了未来的发展趋势,但如何在实际项目里落地,依然要根据网络环境和服务端能力做通盘考虑。如果是固定网络而且丢包率不高,现有的 HTTP/2.0 完全能满足需求。如果业务对实时性要求很高,用户网络情况又比较复杂,比如移动端场景、大规模跨区访问或者弱网环境,HTTP/3.0 可以显著改善访问体验。不过在企业内网或对兼容性要求极高的场合,最好采用双协议或者逐步升级的方案,避免因为 UDP 流量受限或中间设备不兼容而导致服务不可用。
http和https
HTTP与HTTPS的主要区别在于安全性和数据传输的可靠性。
HTTP使用明文传输数据,容易受到中间人攻击,数据可能被窃听或篡改。而HTTPS在HTTP基础上增加了TLS协议,对数据进行加密传输,确保了数据的安全性和完整性,需要使用数字证书来验证服务器身份
虽然HTTPS的加密和解密过程会增加一定的延迟,但现代硬件和优化技术已大幅减少了这种影响。此外,HTTPS有助于提高搜索引擎排名,浏览器显示安全锁标志,增强用户信任。
在实际应用中,尤其是在处理敏感信息如登录凭据、支付信息的场景下,HTTPS是必不可少的。通过使用HTTP/2.0和优化TLS配置,可以进一步减少性能开销。
随着互联网安全重要性的提升,HTTPS已成为现代网络应用的标配。
简述
安全,安全,还是 TMD 安全;1
HTTPS相比HTTP,在通信步骤中显著增加了TLS握手、证书验证和密钥交换等关键步骤。
具体而言,HTTPS在建立TCP连接后,首先进行TLS握手,客户端发送支持的TLS版本、加密方法和随机数,服务器回应并附上服务器证书;
接着,客户端验证证书合法性,确保通信对方可信;
随后,双方协商生成会话密钥,用于后续数据的加密传输。
这些额外步骤不仅确保了数据的安全性和完整性,还验证了通信双方的身份,显著提升了安全性。