全局锁
全局锁,是一种影响整个MySQL实例的锁
flush tables with read lock,执行此条命令,整个数据库处于只读状态
unlock tables, 释放全局锁,会话断开时,也会自动释放全局锁
全局锁,是一种影响整个MySQL实例的锁
flush tables with read lock,执行此条命令,整个数据库处于只读状态
unlock tables, 释放全局锁,会话断开时,也会自动释放全局锁
InnoDB:
索引分为聚集索引与二级索引
支持事务
支持行级锁
支持外键
必须有主键,如果没有,会选择第一个非空唯一索引当主键,如果没有非空唯一索引,自动创建隐藏主键
对于自增长字段,InnoDB必须有 只有该字段 的索引
MyISAM:
索引只有一种(索引字段作为索引数据,叶子节点包含了该记录数据页地址),数据页和索引页分开
不支持事务,没有undo 和 redo
仅支持表锁
不支持外键
会保存表的总行数(InnoDB为什么不保存?因为InnoDB支持事务,保存了也不精准,就不这么设计了)
可以没有主键
对于自增长字段,MyISAM可以和其它字段一起建立联合索引
MyISAM数据页和索引页分开
jion 是用来多表关联查询
jion方法有三种:left jion,right jion,innner jion
inner jion(等值连接):获取两个表字段匹配关系的记录,即只有两表的交集
left jion:获取左表的全部记录,即使右边无对应匹配的记录
right jion:获取右边的全部记录,即使左边无对应匹配记录
配合一起使用的还有ON关键字,用来指明查询的条件
原因是早期MySQL版本,jion的时间复杂读很高。它的实现原理是基于嵌套循环来实现关联查询的。简单地
说就是通过一张表作为外循环,一张表位内循环,然后一一比对,符合条件的就输出。具体算法的实现有三
种,simple nested loop,block nested loop和index nested loop。但效率都不是很高。而且随着你jion表数
量越来越多,时间复杂度以指数级别增长
simple nested loop
从名字上就看出来,简单除暴,就是全量扫描连接两张表进行数据的两两对比,时间复杂度可以认
为是N*M
index nested loop
当内循环(即被驱动表)关联的字段有索引的话,可以用索引进行查数据。因为索引的结构是b+树的,
复杂度可以近视为N*logN
block nested loop
其实是引入了一个Buffer,提前把外循环的一部分数据放到JION BUFFER里,然后再一一比对,虽然整
体还是N*M复杂度,但基于内存,效率会高不少
orderby是做排序的,它排序方式有两种,一种是索引排序,一种是filesorted(我们可以在extra中看到提示:using filedsorted),但具体哪种还得看优化器来抉择,而且确定性也不是很强。
在filedsort排序中,如果排序的内容比较少,就会直接内存的sort_buffer进行排序,否则就得使用临时文件了
。且当在sort_buffer排序时,如果排序的字段并不是很长的话,就会使用全字段排序的方式直接在sort_buffer里排好序后返回结果集。但如果字段特别长,就会基于空间考虑,采用(隐藏ID)row_id进行排序,然后回表查询后返回结果集
ps:字段长度指的是 **参与排序的字段 + SELECT 返回的字段的总长度 **
索引天然有序的,那么借助索引进行排序自然是最高效的。但这个过程中,是否真的用索引,完全取决于优化
器的选择。查询优化器会根据成本评估来进行选择是否通过索引进行排序
我平时开发比较好奇,就有去测到底哪一种情况最容易做索引排序
1.用到了索引覆盖且遵循最左匹配原则
2.查询条件中有limit,且limit的Size不高,像之前测的时候我80万数据的表,limit超过2w就不会走了
3.用到了索引跳跃机制
前面我们知道,filesort 如何排序的内容不多时,会直接在内存的sort_buffer里面排,多的话就基于临时文件
排序了。这种行为是由sort_buffer_size即sort_buffer的大小所决定的。排序的数据量小就在内存,大就在文
件。
filesort是如何进行排序的?
基于归并排序的算法,把排序的数据拆分成多个临时文件,然后进行一个merge返回给客户端
这里还有一个影响排序算法的重要参数,即max_length_for_size_data,是MySQL中用于控制 用于排序的行数的长度一个字段,默认为1024bit。如果单行的长度大于这个值,就会进行rowId 排序,否则就进行全字段排序
实例SQL
1 | select a,d,f from t2 where a = "Hollis" order by d; |
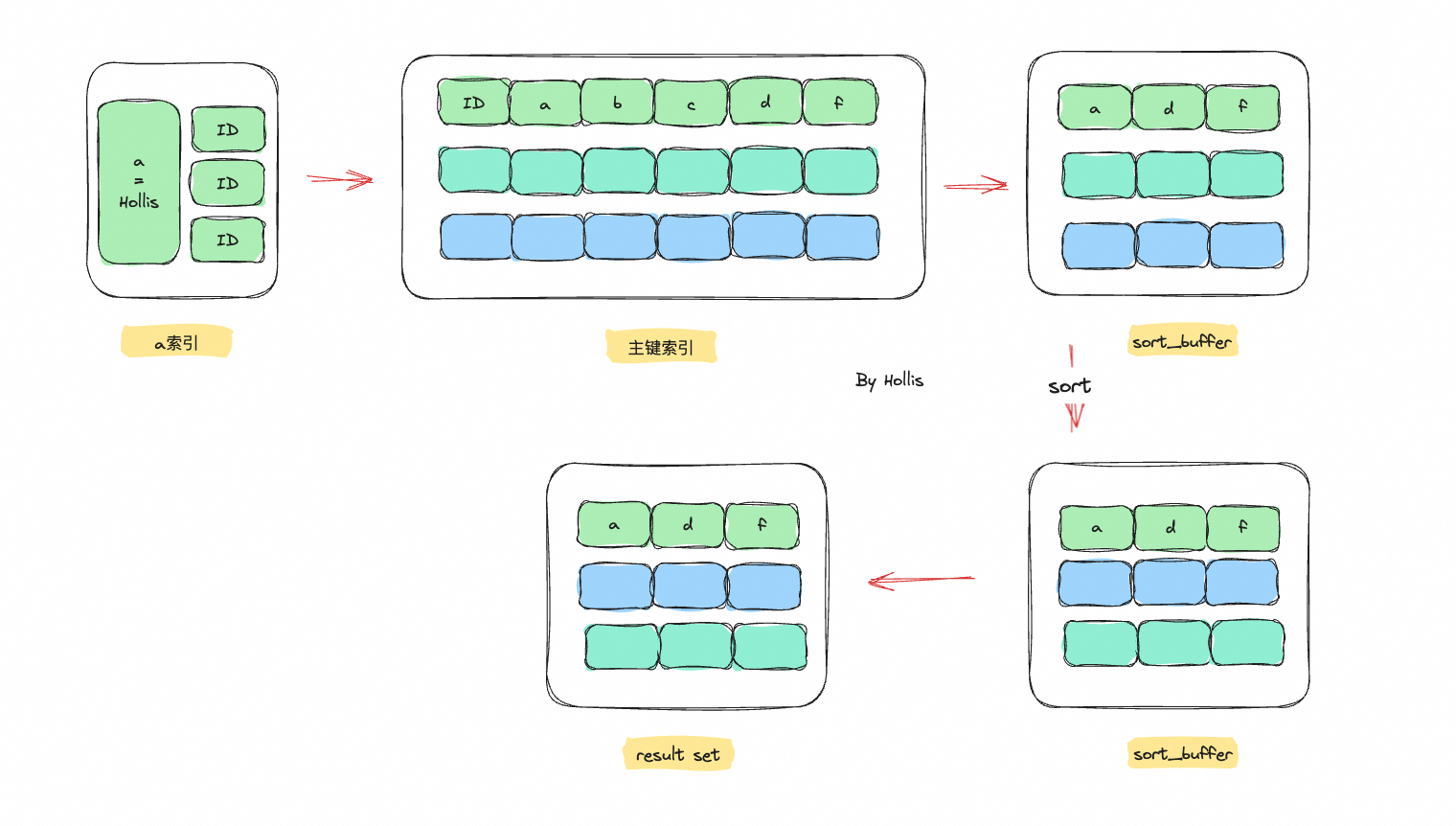
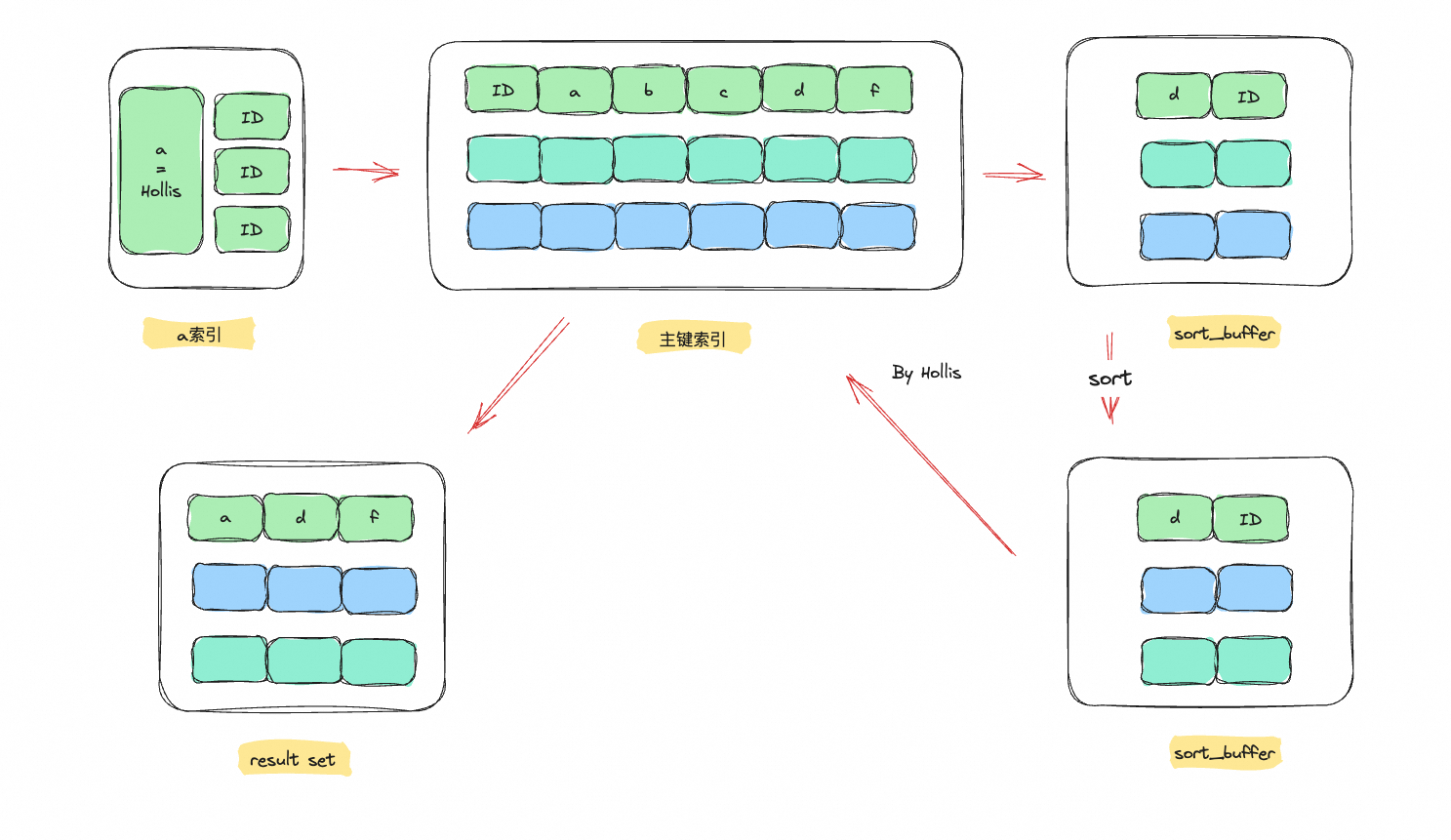
速度>内存>一次回表
对select,update,delete(后两个是告诉你他是怎么查找数据的)。对insert无效的
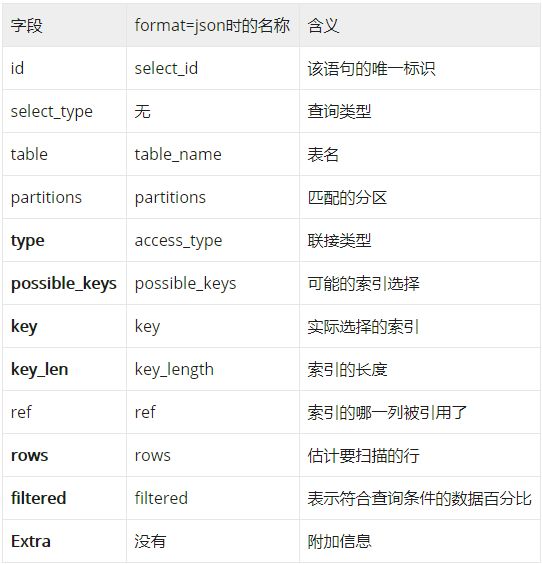
id:
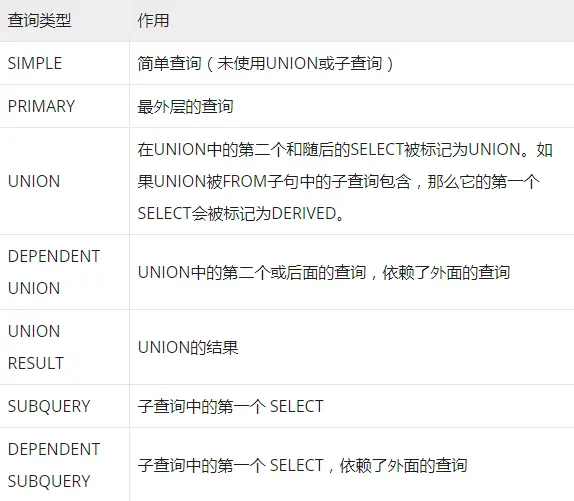
表示单一SQL的执行顺序,该语句的唯一标识。如果explain的结果包括多个id值,则数字越大越先执行;而
对于相同id的行,则表示从上往下依次执行
select_type
table
表示当前sql作用的表名
type
explain select * from t2 where f='Hollis';explain select * from t1 join t2 on t1.id = t2.id where t1.f1 = 's'; explain select * from t2 where a = 'Hollis'; explain select * from t2 where a > 'a' and a < 'c';explain select c from t2 where b = 's';explain select * from t2 where d = "ni";需要注意的是,这里的index表示的是做了索引树扫描,效率并不高。以上类型由快到慢:
system> const > eq_ref >**ref>range> index **>ALL
possible_keys
展示当前查询可以使用哪些索引,这一列的数据是在优化过程的早期创建的,因此有些索引可能对于后续优化过程是没用的。
key
表示MySQL实际选择的索引
key_len
索引使用的字节数。由于存储格式,当字段允许为NULL时,key_len比不允许为空时大1字节。
filtered
表示符合查询条件的数据占全部数据的百分比,最大100,越高则越好
rows
mysql估算会扫描的行数,越小越好
extra(额外信息)
Using filesort:当Query 中包含 ORDER BY 操作,而且无法利用索引完成排序操作的时候,MySQL Query Optimizer 不得不选择相应的排序算法来实现。数据较少时从内存排序,否则从磁盘排序。Using tempporary:在对MySQL查询结果进行排序时,使用了临时表,这样的查询效率是比外部排序更低的,常见于order by和group by。
Using index:使用了索引覆盖
Using where:使用了where进行过滤,即使用到了索引,如果没有索引,说明是去聚集索引全盘扫描,说明
没用到where进行过滤,只用where进行判断
Using index condition:使用了索引下推
Using MRR:使用了Multi-Range Read优化
Using join buffer:使用了连接缓存,比如说在查询的时候,多表join的次数非常多,那么将配置文件中的缓
冲区的join buffer调大一些
Distinct:查找distinct值,当找到第一个匹配的行后,就不再搜索了
事务会产升的问题:
查看隔离级别:
select @@TRANSACTION_ISOLATION;
set global TRANSACTION ISOLATION LEVEL
读的时候不加锁,也不使用MVCC,能直接读到最新数据,update时加记录锁,事务问题最多
读的时候有快照读和当前读,快照读使用MVCC,每次快照读都产生新的readview,读的是最新提交的数据
不算脏数据,解决了脏读。update只会加记录锁。
读的时候跟读已提交差不多,区别是只在第一次快照读时生成readview,后面会复用,解决不可重复读。
update会加间隙锁和临键锁。
读和写都加锁,读都是当前读
快照读通过MVCC
RR的快照读只会生成一次readview,那么该事务中途有其他事务插入数据,对当前事务是不可见的,
即避免了幻读
当前读通过加锁
当前读select…for upate会通过加临键锁的方式阻塞其他事务想往锁范围的数据插入数据,直到当前事务
提交结束
但有两种特殊情况
1.当前事务去主动更新“不存在”的记录(这里的不存在指的是对当前事务不存在,其实其他事务已经插入
进来了),然后这条记录就对当前事务可见,于是发生了幻读
2.快照读,然后当前读
第一次快照读,第二次当前读
在数据库层面的原子性指的是要么都成功,要么都失败(不同于并发编程中的原子性:操作不可被打断),它在InnoDB中是由undo log日志来保证的
即
事务完成时,修改后的数据要满足数据库对于数据完整性的约束,包括主键约束、约束检查等,同时要满足数据库中业务数据的一致性,比如银行转账,有人多钱就肯定要有人少一样数量的钱
这里是靠原子性,隔离性,持久性一起保证的
分布式理论中也有一致性,但它指的是所有服务节点都保持一致
各个事务并发操作下互不影响
靠MVCC和锁机制来保证的,比如在可重复读的事务隔离级别下,MVCC保证了快照读的隔离性,锁保证了当
前读的隔离性
事务一旦提交or回滚,它对数据库的修改是永远不变的
InnoDB是通过redo log来保证事务修改的数据不丢失