快速根据 key 找到 value 的“键值对集合” ,查询和插入平均时间复杂度都是o(1)
底层数据结构
1.7为数组+链表
1.8为数组+红黑树/链表
为什么要用红黑树,为何不一上来就树化?
链表太长,会影响查询性能,出现树化意味着被DDoS攻击了,即 被人恶意哈希冲突攻击(构造大量相同
的hashkey),树化可以缓解这种情况。
而平衡二叉树在极端情况下也是有这个问题,相当于链表了,红黑树比二叉树好一点,因为红黑树追求
大致平衡,自平衡效率高。
树化应该是一种偶然现象,链表短的情况下没必要,查询性能很高了,而且链表的占用内存要比树
要少
何时会树化,树化阈值为什么是8?
数组长度>=64 且链表长度>=8 就会进行扩容
jdk开发者他们基于大量的实验验证出来的,什么泊松分布,在负载因子为0.75的情况下,链表长度为8
的概率为0.00006,即选择8是让树化的概率最小
红黑树何时退化
- 扩容拆分树时,发现树的元素小于6,也会链表化
- remove树节点时,发现root,root.left,root.rigth,root.left.left为null(移除前检查),也会链表化
索引计算?为什么数组容量要为2的n次幂
idnex=hash&(size-1),相当于hash%size,但前提是size为2的n次幂
这个是为了底层能通过位运算来提高性能,还有一个就是扩容的时候如果index=oldCap&(size-1)==0,
说明还在原位,如果不是newIndex=oldIndex+oldSize。综上所叙,size为2的幂次方的好处挺多的
数组容量可以不为2的n次幂吗
可以的。size为2的n次幂虽然性能比较高,但如果hash全是偶数,运算出来的index就都是偶数,这
就导致hash分布不均
若追求更好的hash分布,可以用质数作为容量,这样还不用二次hash
例如hashTable它的扩容策略就是 oldCap*2+1
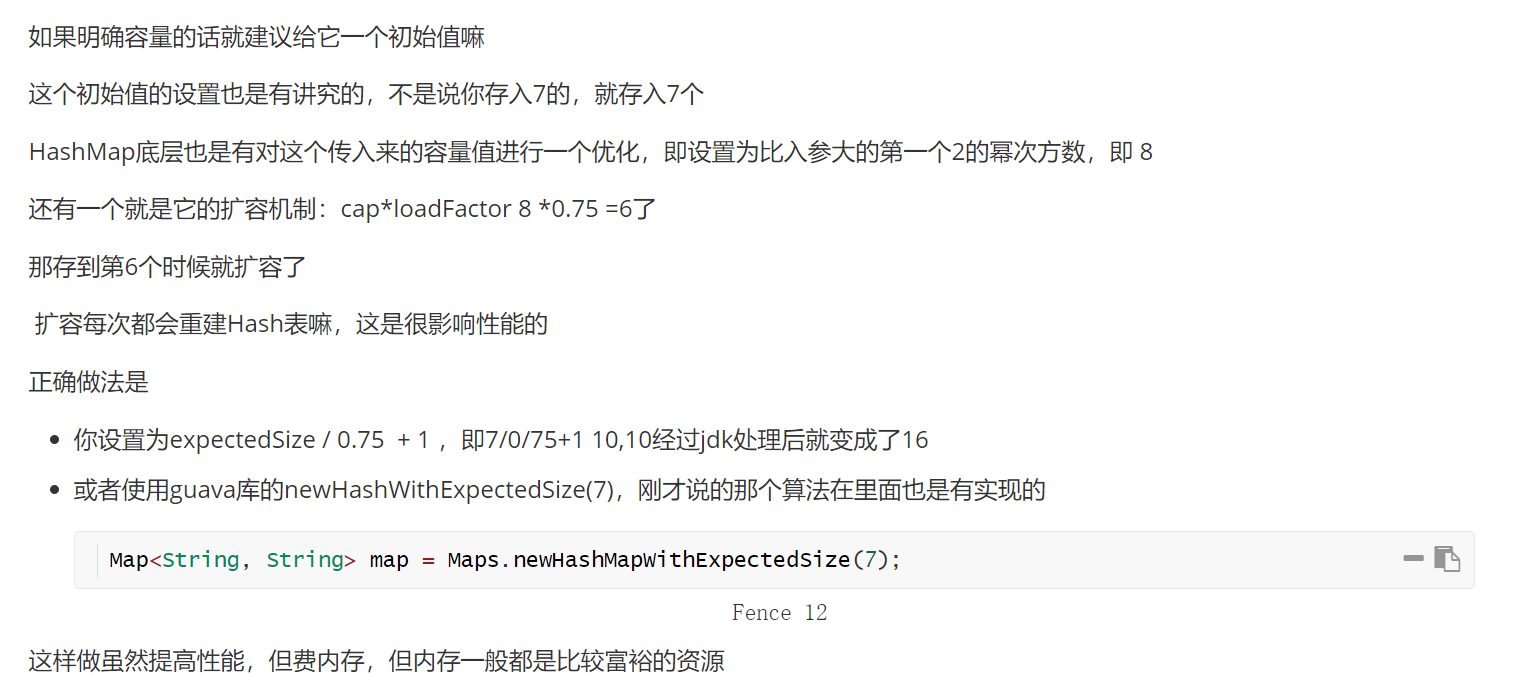
hashmap的容量如何设置?
hashCode都有了,为什么还要调用HashMap的hash()方法对hashCode进行二次哈希?为什么用异或?
jdk1.8中是拿着hashcode()的高16位和低16位进行异或
jdk1.7中是拿hashcode()多次移位,异或
用异或是为了扰乱hash,让hash分布更加均匀,只要32位中的一位不同,hash()返回的结果就不同
put方法流程?1.8和1.7的区别
1.HashMap为懒加载,即初始化只会初始化负载因子,而不是初始化容量
2.计算索引(桶下标)
3.判断索引位置是否为null,为null就创建Node节点插入
4.不为null,则判断是链表还是树,创建对应的节点走相应的添加or更新。如果是链表达到了树化的
逻辑,就走树化的逻辑(链表长度>=8且数组长度>=64)
5.添加后,判断是否需要扩容
1.7和1.8的扩容也是有所不同
1.7扩容时链表节点移动为头插入法,而1.8为尾插法
1.7是大于阈值且插入的桶没空位才会扩容(懒扩容),1.8是大于阈值就会扩容(主动扩容)
1.8扩容时计算Node的索引时,会有优化(位置不变+oldCap)。1.7是重新hash

get()方法流程
1.计算hash值
2.定位桶索引
3.通过hash()和equals方法和第一个桶节点比较是否相等,若相等就返回,不相等就进行链表or红黑树的
查询逻辑
加载因子为什么为0.75
在空间和时间查询性能之间能取得较好平衡
大了,链表长度容易长
小了,就经常扩容,影响性能
但其实根据二项分布,0.693是最好的选择,但考虑到size为2的n次幂,故取到了0.75,其实0.695….其
实也可以,只不过从中位数的角度,0.75是最好的
多线程下出现的问题
1.7的时候扩容时为头插入法,就会出现死循环
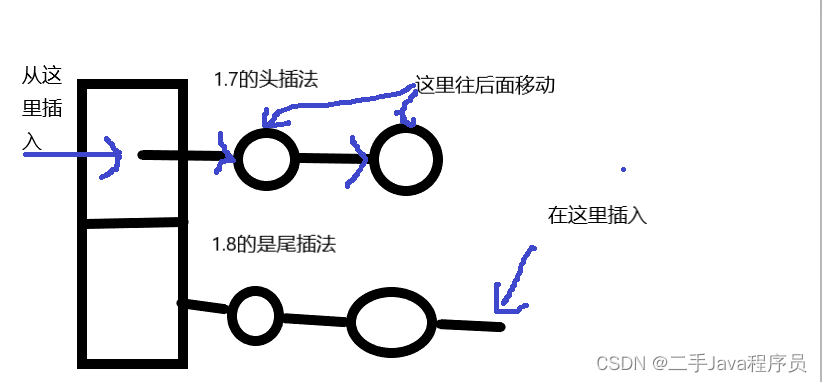
丢数据
两个线程同时判断一个桶位置可以插入位置,就插入了,然后就造成数据被覆盖了,而不会走解决
hash冲突的逻辑
1.7为什么要采用头插入法
首先HashMap本身就不是为多线程设计的,头插入法在线程安全的情况下完全是合适的,而且实现起来
也很简单
还有就是jdk开发者认为后插入的元素更加热点,放在头节点比较合适
jdk8为什么采用了尾插入法
1.jdk8引入的红黑树,那么可以顺便遍历一下链表的元素,统计个数,判断是否需要树化
2.避免多线程下扩容可能产生的死循环
key能否为null?key对象有什么要求?
HashMap的key可以为null。对象必须实现hashcode()和equals方法,hashcode()是定位,equals是比较
两者是否相等,并且key的内容必须不能被修改
hash冲突解决方法
拉链法:hash冲突时,同一槽位的拉成一条链表,hashmap采用的
开放寻址法:发生hash冲突时,寻找其他位置,这就保证了一个位置只有一个元素
线性探测:hash冲突时,往后找,直到找到第一个为null的位置,ThreadLocalMap采用的
二次探测:跟线性探测类似,只不过往后探测的步长是有规律的,2,4,8,16
二次hash