Synchronized
是什么
Java中的关键字,主要用来加锁
怎么用
不管怎么用,最终锁的都是对象
1 | //加到方法上 |
管程
即monitor(管程or监视器),用来实现多个线程对统同一资源的互斥访问
在Java中,每个对象都有Monitor,Monitor伴随Java对象一身
在hotsopt虚拟机中,monitor的实现为ObjectMonitor。
ObjectMonitor是基于c++来实现的,它有几个重要属性:
1 | _owner:指向持有 ObjectMonitor 对象的线程 |
对象头的mark word
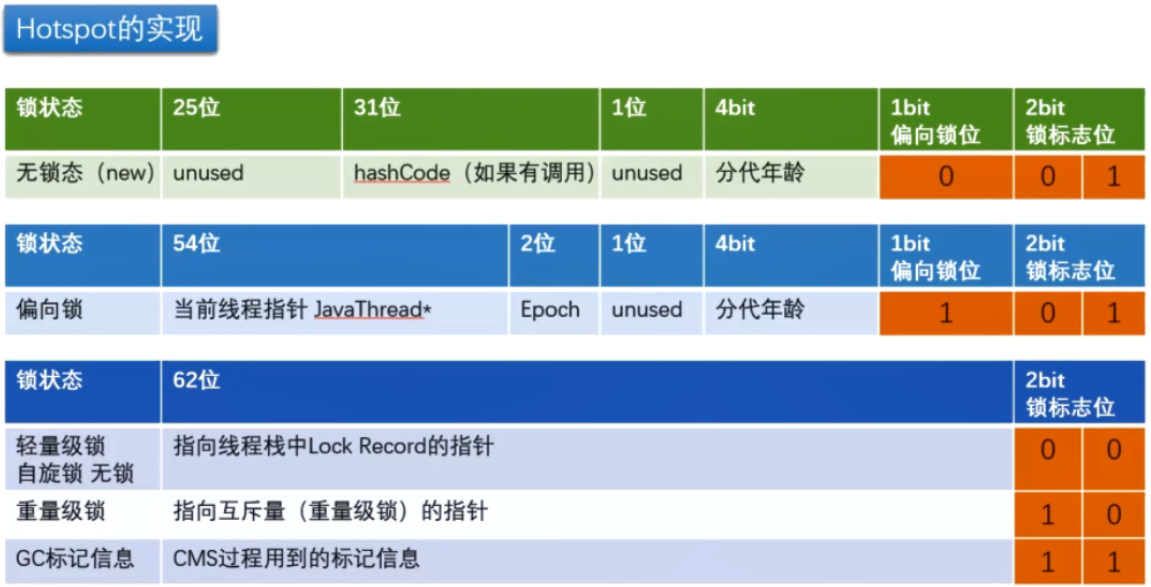
和ObjectMonitor的关系?
如果一个Java对象被线程持有,那么这个Java对象的对象头中的mark word的Lock word就会指向
ObjectMonitor的起始地址
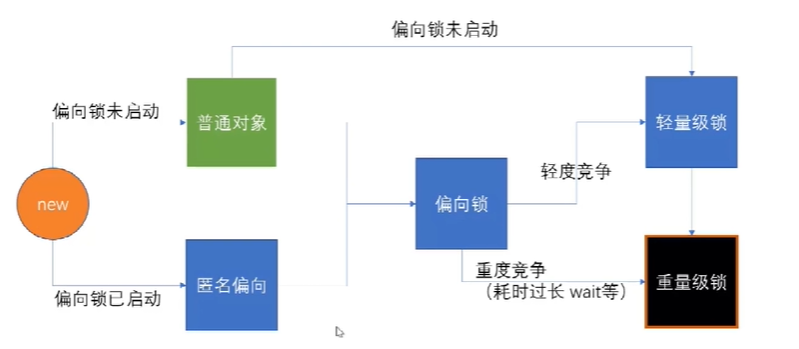
重要级锁
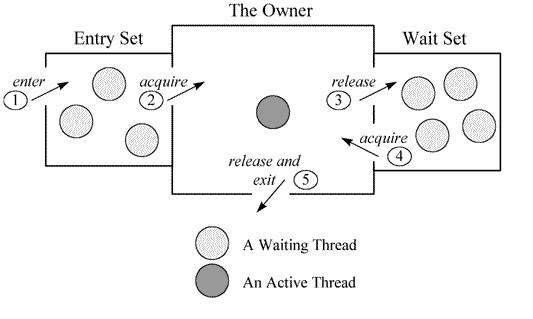
在JDK1.6之前,synchronized的实现才会直接调用ObjectMonitor的enter和exit方法,这种锁被称为
重量级锁。主要实现是通过ObjectMonitor的关键属性来实现的,owner,EntryList,waitset,count
当多个线程同时访问同一段同步代码时,会先进入EntryList队列,当其中某个线程获取得到对象的Monitor后
进入owner区域并把Monitor中的_owner变量设置为当前线程,同时把Monitor中的计数器_count+1 即获得对
像锁。而其他线程这时候来获取锁,获取不到就处于变为阻塞状态。
当持有Monitor的线程调用了wait()方法后,那么他就会释放当前的Monitor,并将owner变量置为null,
count–,同时该线程进入waitset集合中等待被唤醒。若当前线程执行完毕也将释放monitor并复位变量的值
,以便其他线程进入获取monitor,这时候会去唤醒EntryList中的其他线程。
monitor依赖于操作系统的mutexLock
为什么说他重?
Java的线程模型默认是一个用户线程对应着操作系统的一个内核线程。那么在synchronized中涉及到大
线程的阻塞和唤醒,这些都是从用户态切换到内核态来实现的,而这个切换操作在早期CPU是很耗时的
偏向锁
在JDK1.6引入,在JDK13默认为关闭了,JDK 15 完全禁用,JDK 17彻底移除代码
正确地来说,它并不是一个真正的锁。当第一个线程抢到锁时,会在java锁对象中的对象头的markword里填
入自己的线程名字。下个线程还获取时就会进行一个判断(这个判断操作是很轻的),如果还是同一个的话,
就会直接获取。不是的话,就得进行一个锁升级了
匿名偏向?
还没有人去持有偏向锁,这时候锁就是匿名的
为什么要有这个锁?
因为在通过Java开发团队的大量统计,其实在开发中很多代码都是同一个线程在执行
为什么偏向级锁不要设置为一开始就启动,默认是JVM启动后4s才会开启
如果一开始就明确就是多线程环境,那么偏向锁还有什么意义?JVM启动涉及到10多个线程,本身就是
多线程环境
为什么JDK 15要废弃偏向锁?
早期很多集合都是一把synchronized梭哈,比如vector,HashTable。不可否认,偏向锁能保证这些老集
合在单线程使用的环境下的性能,但后来随着HashMap,ArrayLIst等集合的出现。偏向锁变得不是很
重要了

而且官方还说偏向锁的引入导致代码的复杂度升高了,不好维护
微博禁用偏向锁,性能直接飙升
偏向锁这种东西会让对象迟迟无法被回收,导致对象一直越来越多,STW时间变长
锁撤销
轻量级锁
它的出现是为了优化重量级锁在竞争少的场景下的开销大的问题
当另外一个线程获取非匿名偏向锁时,偏向锁就会被撤销,锁就会自动升级为轻量级锁
轻量级锁状态时,JVM为锁对象的对象头markword预留了一部分空间,用来存储指向线程栈中Lock record
的指针
当一个线程尝试获取轻量级锁时(即发现对象头里的锁标记位为 00),就在线程虚拟机栈中开辟一快空间,
即Lock record,里面有两个部分
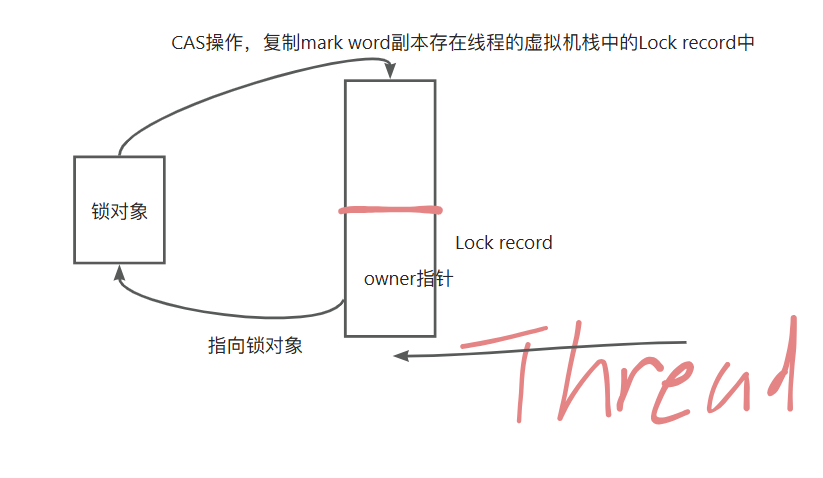
然后尝试通过CAS操作将对象头的mark word更新为指向锁记录的指针
自适应自旋?
锁膨胀
发生在轻量级—> 重量级锁
锁升级

锁升级过程
synchronized 的锁能降级吗?
对于HotSpot虚拟机来说,是没办法的。即一旦锁升级为重量级锁后,你的锁状态就会一直维持重量级锁,直到释放。
不过还有一种特殊的“降级”情况,即重量级锁的monitor对象不再被任何线程持有时,被清理和回收的过程。
JDK6对synchronized的优化?
自旋锁
JDK1.4引入,JDK1.6默认开启
锁消除
JIT层面的优化,即在使用synchronized的时候,如果JIT经过逃逸分析后发现并无线程安全的问题的话,
就会做锁消除
锁粗化
如果在一个循环里,频繁地获取资源释放资源,这样带来的消耗会很大,锁粗化会扩大锁的范围,把加锁
逻辑放到外面。
ps:锁粗化和“平时我们在开放中要尽可能地减少锁的粒度”矛盾吗?
不矛盾
锁升级
JDK1.6引入了偏向锁,轻量级锁。当线程竞争不激烈时,可以减少性能开销
Synchronized的缺点
无法知道线程是否获取到了锁
锁只有阻塞状态