大型订单系统分库分表设计
什么时候应该分库?
如果你是为了解决并发量太高,数据库连接数不够,CPU,内存,磁盘不够的原因
什么时候时候应该分表?
只是说单表数据量太大,需要提高查询性能
所以说分表解决的是大数量的问题,而分库解决的是高并发的问题
什么时候应该分库?
如果你是为了解决并发量太高,数据库连接数不够,CPU,内存,磁盘不够的原因
什么时候时候应该分表?
只是说单表数据量太大,需要提高查询性能
所以说分表解决的是大数量的问题,而分库解决的是高并发的问题
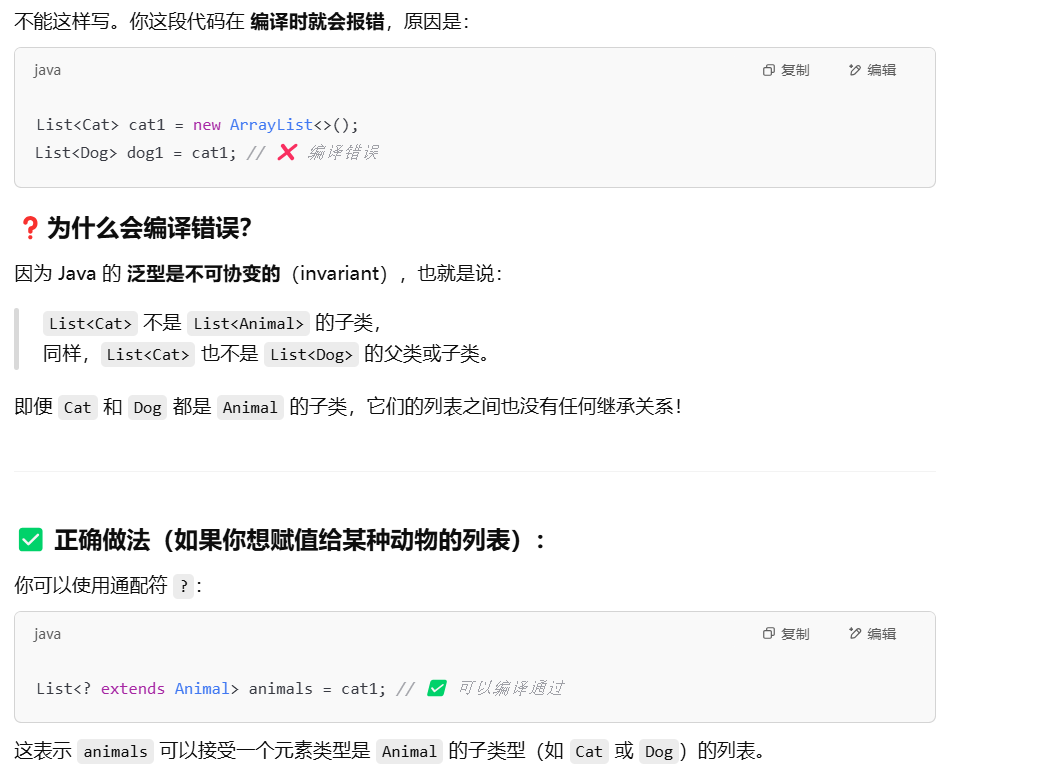
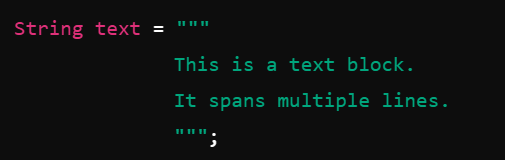
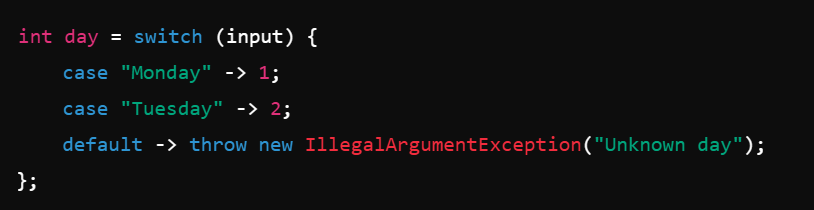
JDK 8:
JDK 17:
创建多态对象时使用 invokespecial 字节码,调用对象方法时使用 invokevirtual 字节码
invokevirtual 指令在运行时的解析过程可以分为以下几步:
可以动态地获取类的全部信息和方法
优点:
- 灵活性和扩展性
缺点
- 破坏了封装性
- 可读性和可维护性低
- 执行性能低
反射为什么性能差?
1.7和1.8的区别
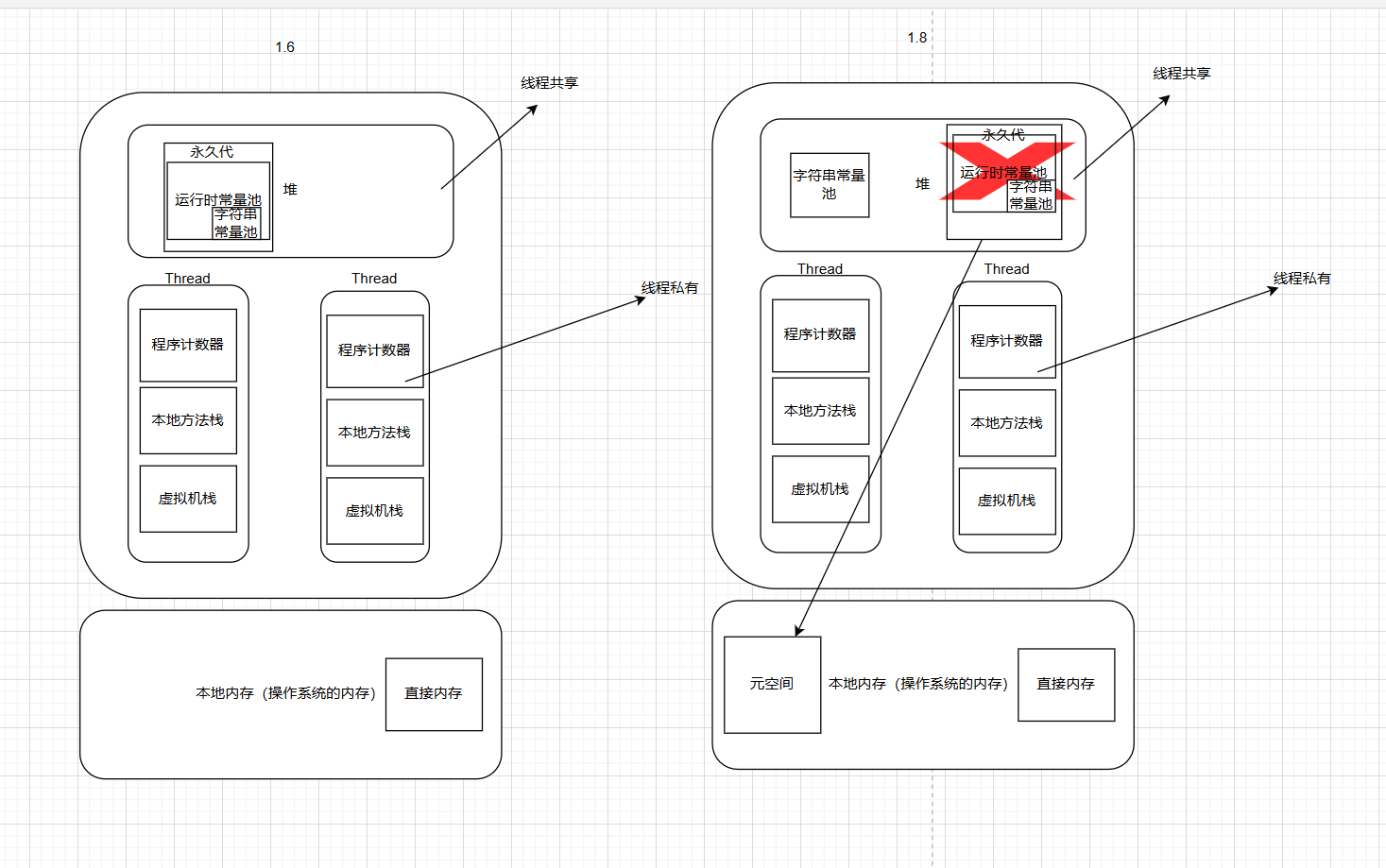
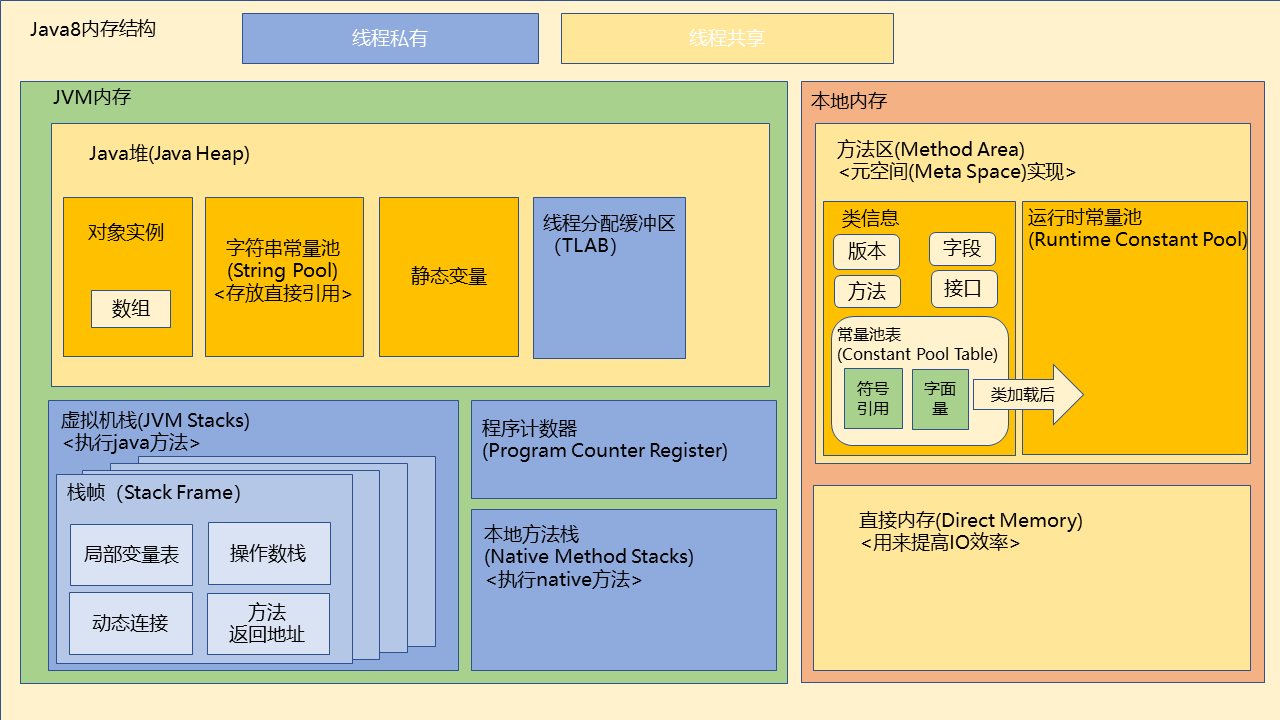
程序计数器:线程私有,程序控制流的指示器,分支、循环、跳转、异常处理、线程恢复等基础功能都依赖这个计数器完成。唯一一个不会OOM的
如果线程正在执行一个Java方法, 这个计数器记录的是正在执行的虚拟机字节码指令的地址;
如果线程正在执行一个本地方法,这个计数器的值应为空
虚拟机栈:线程私有,每个方法被执行时,Java虚拟机都会同步创建一个栈帧用于存储局部变量表,操作数栈,动态连接,方法出口等信息。
每一个方法被调用直至执行完毕的过程,就对应着一个栈帧在虚拟机栈中从入栈到出栈的过程。
本地方法栈:线程私有,和虚拟机栈作用类似,本地方法栈内部执行的是本地方法,在hotspot里和虚拟机栈合二为一了
Java堆:线程共享,几乎所有的对象都在堆上分配(逃逸分析可能导致对象在栈上分配)
线程分配缓冲区:线程私有,提升对象分配时的效率
方法区:线程共享,存储已经被虚拟机加载的类型信息、常量、静态变量、即时编译器编译后的代码缓存等数据。
方法区一直是个概念上的区域,在不同jdk版本有不同实现
jdk6及6之前,方法区是使用永久代实现的,发现放到永久代不太好,决定开始放到本地内存
jdk7把原本放在永久代的字符串常量池、静态变量等移出,此时运行时常量池还是在永久代中
jdk8彻底废弃永久代的概念,将永久代的剩余内容(主要是类型信息)全部移到元空间,使用元空间实现方法区
永久代时,默认大小64MB;元空间时,大小不受JVM限制
运行时常量池:当类被加载时,类中的字面量与符号引用被放入运行时常量池,由符号引用翻译出来的直接引用也存储在运行时常量池
直接内存:并不是Java虚拟机规范中定义的内存区域
总所周知,java中数据类型分为 基本数据类型和**引用数据类型,**基本数据类型一开始就被jvm定义好了,故类
加载的类型是针对于 引用数据类型
准确地说应该是一个类只能被同一类加载加载一次
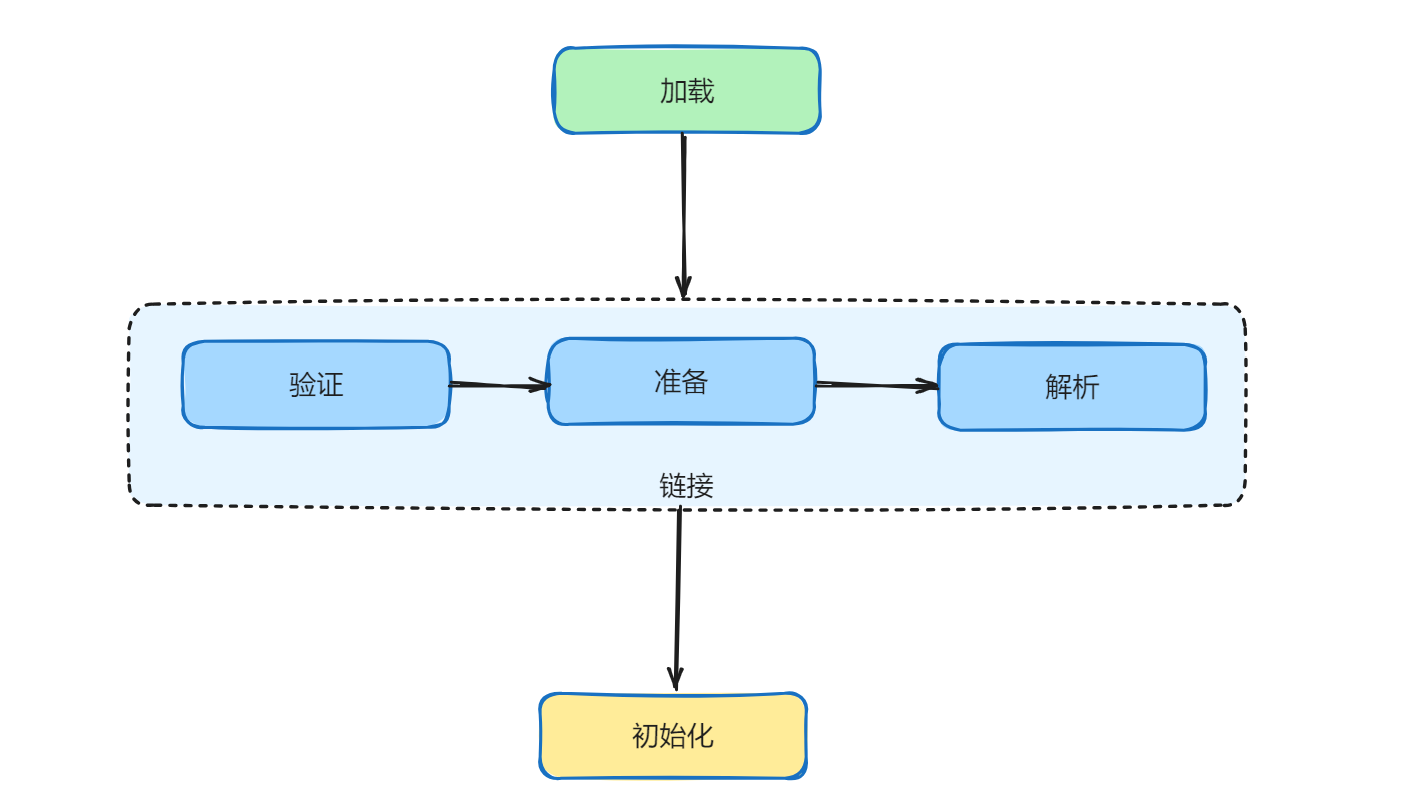
loading:简而言之,就是把磁盘里的字节码文件加载到内存,并在堆上生成一个Class对象(类模版对象)
Linking(验证)阶段
验证:验证加载的字节码是否合法,合理符合规范
准备:为类的静态变量分配内存,并将其赋为默认值。不包含static final修饰的基本数据类型,final类型
的在编译就分配好内存了,准备阶段就是显性赋值了
解析:把符号引用变成直接引用
ps:java虚拟机并没有规定以上三步一定要按顺序。比如在hotspot vm中,解析操作是在初始化化后
的,因为涉及到内存的分配
初始化阶段:重要工作就是执行类的初始化方法:
1.clinit<>()是由jvm来控制的,我们不能在代码中重写or调用它,本身就是字节码指令
2.它是由类的静态成员变量语句以及static代码块组成的
3.在虚拟机加载一个类之前,会先尝试加载该类的父类,因为父类的clinit<>()方法总是在子类之前被执行
也就是说父静态代码块优先于子类
4.clinit<>()是加锁的,多线程尝试去初始化同一个类的,只能有一个线程去执行初始化,其他线程都得阻
塞
5.clinit<>()采用的是懒加载思想,类or接口只有在被第一次主动使用时才会初始化
类的主动使用和被动使用?
主动使用:
1. 创建一个实例对象,如new,clone,反序列化
2. 调用类的静态方法,即执行字节码指令invokestatic
3. 当使用类,接口的静态变量(final变量另外说),即执行字节码指令getstatic,putstatic
4. 通过反射API去创建
5. 当初始化一个类时,其父类还没初始化,会先初始化其父类
6. 虚拟机启动时,main方法所在那个类也会先被初始化
7. jdk7中methodHandle第一次使用调用它的invoke时也会初始化其目标类
只有主动使用xx类,类才会被初始化,而被动使用是不会的
被动使用的情况:
1. 只有真正声明静态变量的类才会被初始化,比如子类去调用父类的静态变量,子类并不会被初始化。至于子类有没有验证,准备,则需要通过使用-XX:+TraceClassLoading来追踪类的加载信息
2. 调用类的引用常量该类并不会被初始化
3. 通过数组定义类引用,不会触发此类的初始化 即 MyClass[] arr=new MyClass[6];

什么时候加载类?
JVM规范并没有强制约束,交给虚拟机具体实现来自由把握