为什么RR为默认的事务隔离级别
兼容老版本,
“MySQL选择RR作为默认隔离级别,核心考虑是保证主从复制的数据一致性。早期MySQL使用statement格式的binlog,如果采用RC隔离级别,并发事务的执行顺序差异可能导致主从数据不一致。RR级别通过GAP锁机制强制事务串行化,确保binlog回放结果与主库一致。虽然这牺牲了部分并发性能,但对于数据库集群的数据一致性保障是必要的设计权衡。”
兼容老版本,
“MySQL选择RR作为默认隔离级别,核心考虑是保证主从复制的数据一致性。早期MySQL使用statement格式的binlog,如果采用RC隔离级别,并发事务的执行顺序差异可能导致主从数据不一致。RR级别通过GAP锁机制强制事务串行化,确保binlog回放结果与主库一致。虽然这牺牲了部分并发性能,但对于数据库集群的数据一致性保障是必要的设计权衡。”
TPS: 每秒钟系统处理的事务数量
MySQL5.5版本,普通8核16G的机器,一张100万的常规表,顺序写性能在2000tps,读性能的话,如果索引有效,tps在5000左右
假设数据库每个数据记录的大小为400字节(50个bigint类型),而用于索引的键占8字节。三层树高(两层索引页,一层数据页)能放多少数据?
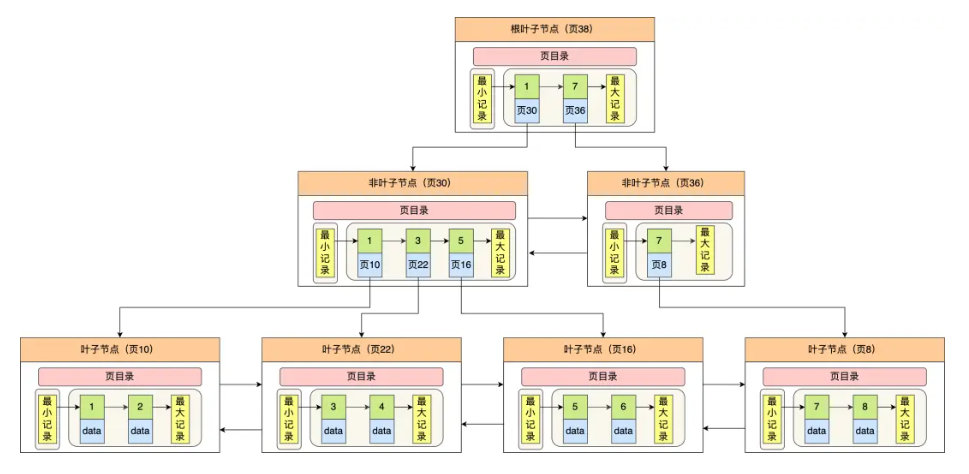
页的大小为16k(实际会有其它信息占用大概200字节),这里按16k来算,非叶子节点中,一行记录包括索引的键和指向其它页号的指针(InnoDB指针占6字节),所以一行记录是8 + 6 = 14字节
每页可以包含的键数 = 16384字节 / 14字节 = 1170
每个数据记录400字节,那么一个数据页16k可以存放16384 / 400 = 40行数据
那么两层b+树高则有1170个叶子节点(第一层为一个索引页根节点,然后第二层扩展出1170个数据页叶子节点)每个叶子节点能存放40行数据,即1170 * 40 = 46800行记录
那么三层b+树高则有1170 * 1170 = 1368900 个叶子节点(第一层为一个索引页根节点,然后第二层扩展出1170个索引页叶子节点,然后第三层扩展出1170 * 1170个数据页叶子节点),每个叶子节点能存放40行数据,即 1368900 * 40 = 54756000(五千万?!)
我们不是说三层树高是2000w数据吗,现在算怎么三层树高就能存5000w数据?实际上,2000w的那个数据是每行数据记录大小为1k计算得来的,也就是1024个字节,128个bigint,而我们不是每个表都会定义这么多字段,所以还得根据表的具体情况来计算,而且每个页都需要一定空间存放其它信息,每行也需要存放其它的信息,实际的话还需要考虑这些内存占用
QPS:即每秒查询量
硬件优化
1.CPU
2.内存
3.磁盘 SSD
参数设置
1.InnoDB_buffer_pool_size
2.redo log buffer大小
3.连接数
业务层面
1.读写分离
2.数据库分片
3.冷热分离
事务:一组操作的集合
底层基于数据库事务和AOP来实现的。也就是说如果你数据库用的存储引擎不支持事务,那
Spring事务就肯定没有的。(声明式事务才会基于AOP,编程式事务只是基于数据库的事务)
首先它会对使用了@Transitional注解的Bean(怎么判断Bean上是否有的?类、或者父类、或者接口、或
者方法中有这个注解都可以),创建一个代理对象
当调用代理对象的方法时,就会去判断方法上是否加了@Transitional
如果是,那么就用事务管理器创建一个数据库连接
并且把其自动提交置为false,变为手动提交,这是Spring重要的一步,即把事务交给Spring管理
然后就会执行SQL
执行完当前方法后,就直接提交事务
如果有异常,且这个异常是要回滚的异常,就会回滚事务,如果不是就还是直接提交
Spring事务的隔离级别对应的就是数据库的事务隔离级别
Spring事务的传播行为是Spring自己来实现的,也是Spring事务中最复杂的地方
Spring事务的传播是基于数据库连接来做的,一个事务对应着一个数据库connection
@Transitional
无侵入性,但粒度大,只支持方法级别
粒度小,可以避免Spring AOP失效的问题
基于TransitionTemplate
1 | @Autowired |
基于TransitionManager
1 | @Autowired |
spring 事务失效的 12 种场景_spring 截获duplicatekeyexception 不抛异常-CSDN博客
声明式失效的场景
方法访问权限不为public,因为方法要想被Spring代理,就必须是public
方法被final修饰,被final修饰意味着不能被重写。声明式事务使用了AOP,底层是用到jdk和cglib了动态代
理,都得通过重写重写方法去实现代理
方法内部调用时,没通过代理对象调用方法,而是通过this调用
Bean没被Spring所管理
多线程事务
表不支持事务
事务回滚不了的场景
错误的传播特性
自己捕获了异常,且不抛出
自定义异常
手动抛了别的异常,默认情况下不指定只会抛运行时异常
嵌套事务回滚多了
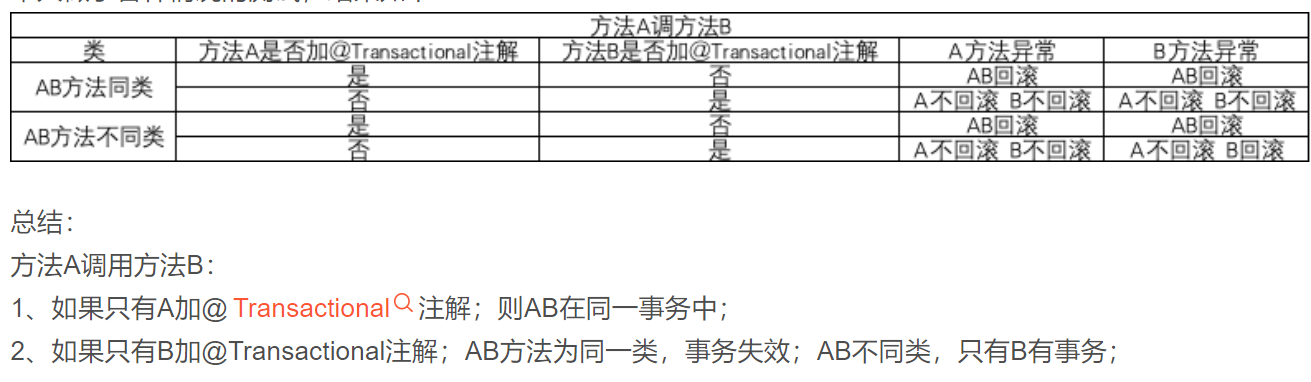
表空间——段——区——页——行
表空间:
默认情况下InnoDB有一个共享表空间ibdata1,所有数据放入这个表空间,如果开启了innodb_file_per_table(默认ON),每张表都可以放到一个单独的表空间,但只把数据、索引和Insert Buffer Bitmap放入单独表空间,其它数据,如undo信息、插入缓冲索引页、事务信息,二次写缓冲等还是放共享表空间
段:
表空间由各个段组成,数据段、索引段、回滚段等,数据段即B+树叶子节点,索引段即B+树非叶子节点。每个段开始时,先用32个页大小的碎片页存放数据,使用完这些碎片页,再去一个区一个区地申请内存,这保证了小段如undo这样的段可以省空间
区:
区由连续的页组成,一个区固定是1MB,页默认16KB,即一个区有64个连续的页,InnoDB1.0.x引入压缩页,页的大小可以是2K、4K、8K,但不管怎么变,区都是1MB
页:
InnoDB磁盘最小的管理单位,默认16KB,InnoDB1.2.x开始可以更改默认大小innodb_page_size为4K、8K、16K,更改后,不得再次修改,除非mysqldump导入导出产生新的库
常见的页类型:
数据页(B-tree Node)
undo页(undo Log Page)
系统页(System Page)
索引页(Index Page)
事务数据页(Transaction system Page)
插入缓冲位图页(Insert Buffer Bitmap)
插入缓冲空闲列表页(Insert Buffer Free List)
未压缩的二进制大对象页(Uncompresses BLOB Page)
压缩的二进制大对象页(compressed BLOB Page)
行:
行存储有四种格式,Redundant、Compact、Dynamic和Compressed。MySQL5.1开始默认使用Compact,MySQL5.7开始默认使用Dynamic
Compact:
| 变长字段长度列表 | NULL标志位 | 记录头信息 | row_id | trx_id | roll_ptr | 列1数据 | 列2数据 | …… |
|---|
变长字段长度列表:当数据表有变长字段时才出现,记录本行中各变长字段实际长度,当长度小于255时用1个字节表示,大于255时用2个字节表示,不会用3个字节,因为变长字段有长度限制,最多65535字节
NULL标志位:当数据表存在允许NULL的字段时才出现,本行每个字段是否为null用0或1表示,同时必须是整数个字节大小,即不足8个bit位的高位补0
记录头信息:存储一些信息,固定5个字节,如delete_mask,标识删除位;next_record下条记录的地址;record_type,记录类型,0为普通,1为B+树非叶子节点,2为最小记录,3为最大记录
变长字段长度列表和NULL是逆序存储(方便寻址)
row_id:当建表时没指定主键时,选择第一个非空唯一索引当主键,如果没有,添加该列作为主键,6字节大小
trx_id:事务id,这条数据是哪个事务生成的,6字节大小
roll_ptr:上个版本的指针,7字节大小
一个页最多有16KB,16384字节,而varchar(n)最多可以存储65533字节,那么一个页可能都放不了一条记录,这时就会行溢出,溢出的数据会放到“溢出页”中,原页会保留20个字节指向该溢出页的地址。
Compressed和Dynamic行格式和Compact非常相似,主要是行溢出时的处理,这两个不会在原页保存数据,只用20字节指针指向溢出页,数据全在溢出页,而Compressed还会对BLOB、TEXT、VARCHAR这些大长度类型的数据进行zlib算法压缩
varchar类型理论最多可以存放65535个字节,但实际上最多65533个字节:
除了TEXT、BLOBs这种大对象类型,其它所有列(不包括隐藏列和记录头信息)占用的字节长度加起来不能超过65535字节
所以65535字节>=变长字段长度列表 + NULL标志位 + 各列长度
当一列只有varchar时,需要占用2字节的变长字段长度列表 + 0或1的NULL标志位(看varchar允不允许为NULL)+ varchar长度
所以最多varchar最多存储65533个字节(当varchar不允许为NULL时)
char和varchar?
char存储固定长度字符串,最大长度255字节,当存储长度小于定义的长度时,MySQL在后面补空格(如果本身存储的字符串尾部就有空格,就会丢失空格信息!)
varchar存储可变字符串,读取速度相对更慢一点,因为需要先读长度,再读数据
一般使用varchar存储较好,但考虑到极端情况,varchar因为长度可变,可能出现页分裂的情况
如果是身份证号、订单号、国家编码等这些固定长度的,可以用char
如果是产品描述、用户地址、用户名称这种,可以用varchar
数据页结构:
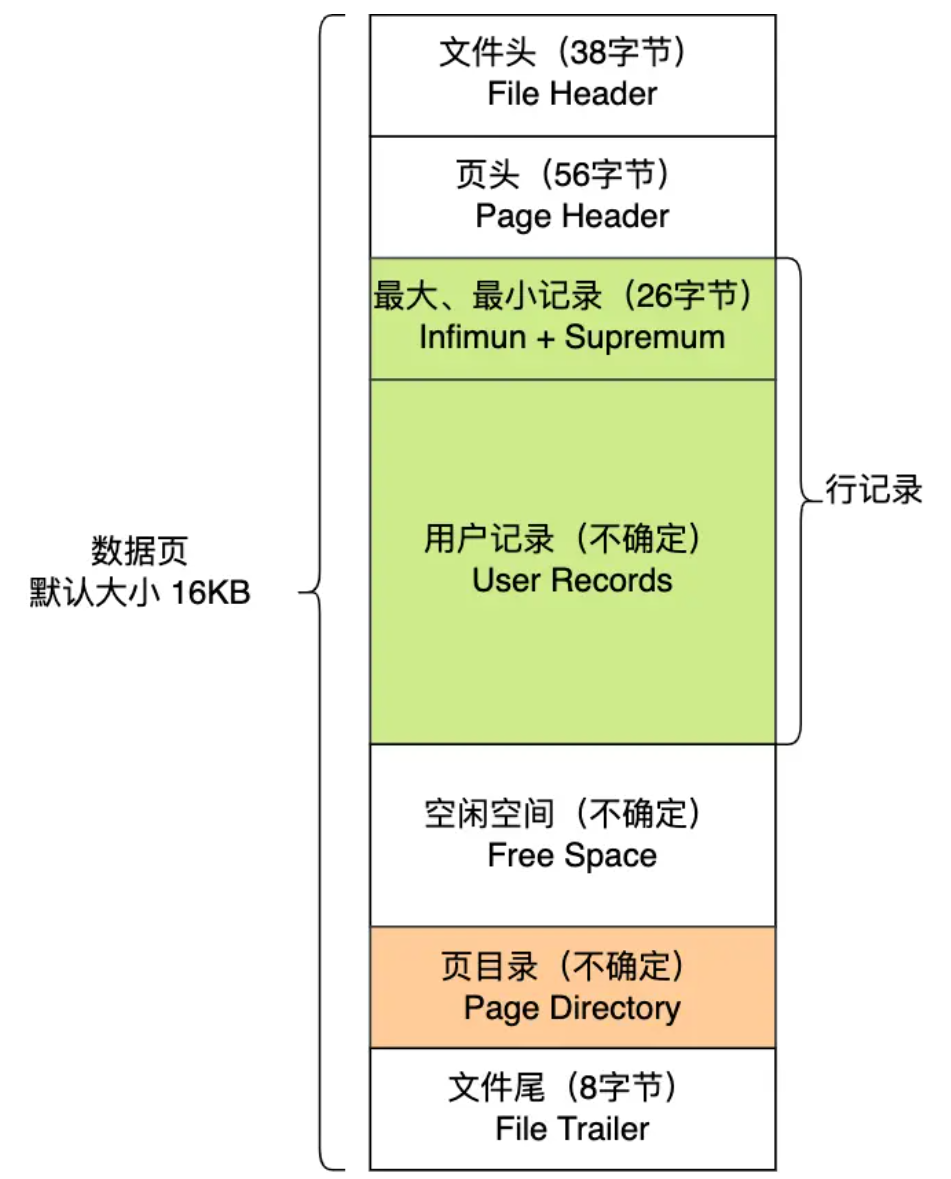
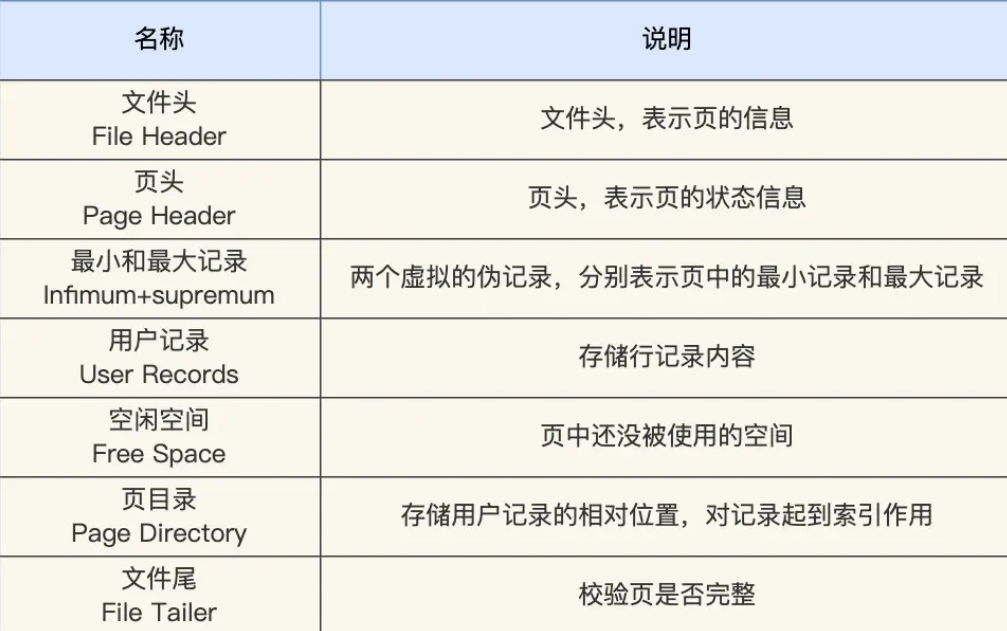
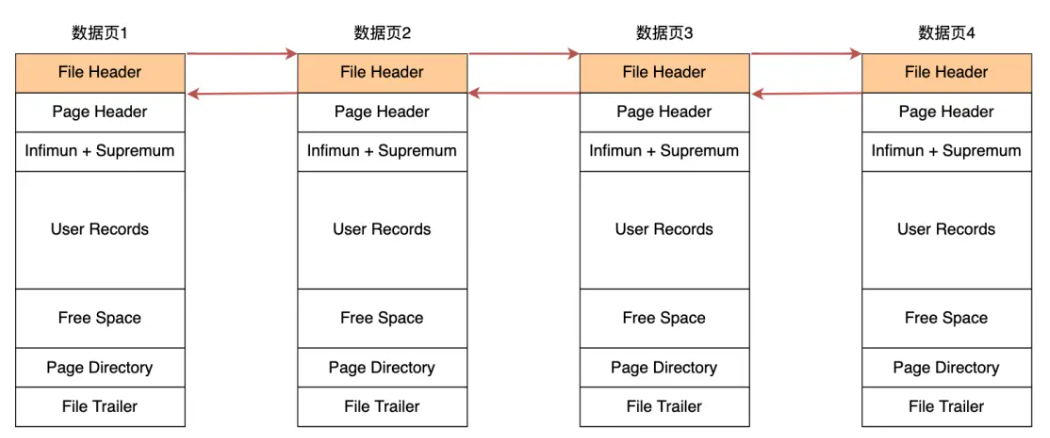
采用链表的结构是让数据页之间不需要是物理上的连续的,而是逻辑上的连续。
数据页中的记录按照「主键」顺序组成单向链表,单向链表的特点就是插入、删除非常方便,但是检索效率不高,最差的情况下需要遍历链表上的所有节点才能完成检索。
因此,数据页中有一个页目录,起到记录的索引作用,就像我们书那样,针对书中内容的每个章节设立了一个目录,想看某个章节的时候,可以查看目录,快速找到对应的章节的页数,而数据页中的页目录就是为了能快速找到记录。
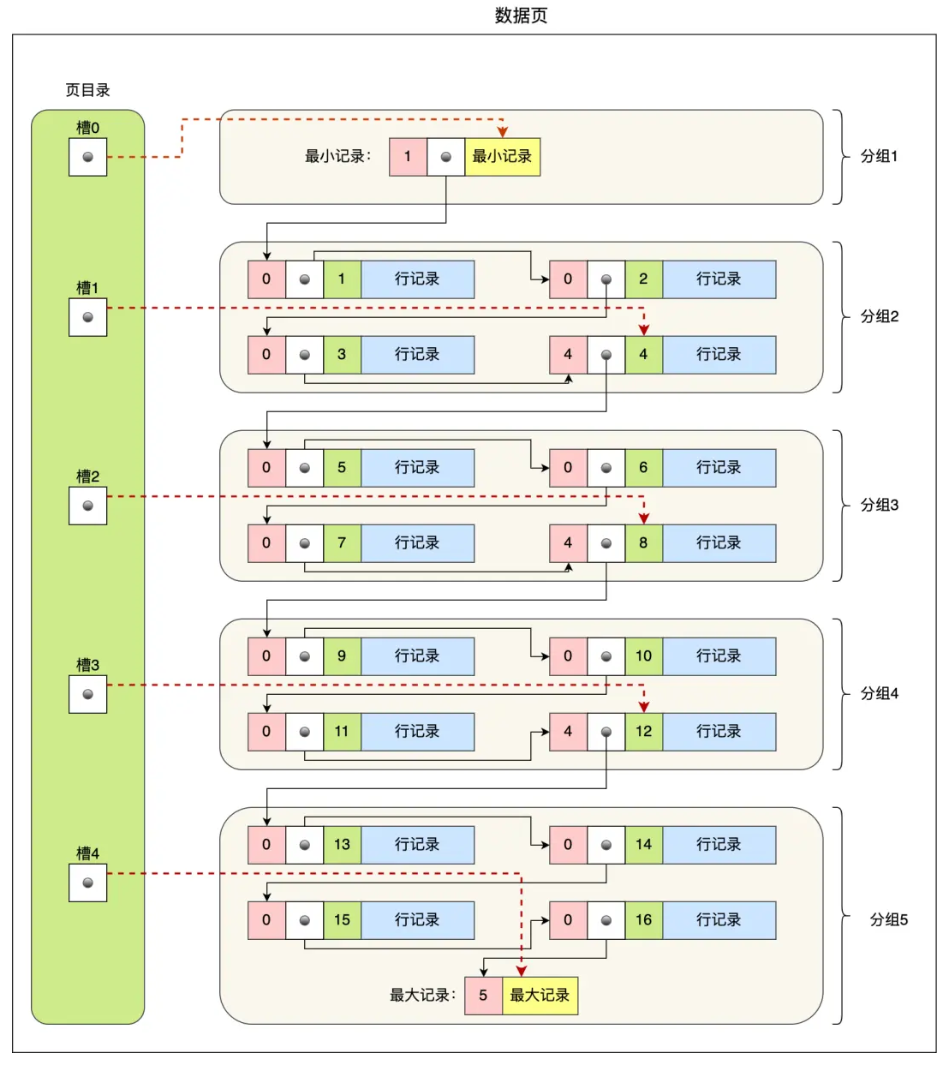
从图可以看到,页目录就是由多个槽组成的,槽相当于分组记录的索引。然后,因为记录是按照「主键值」从小到大排序的,所以我们通过槽查找记录时,可以使用二分法快速定位要查询的记录在哪个槽(哪个记录分组),定位到槽后,再遍历槽内的所有记录,找到对应的记录,无需从最小记录开始遍历整个页中的记录链表。
索引:
索引页的行记录是指针,指向一个页,索引页的索引键值就是指向的页的最小索引键值
数据页的行记录就是数据(聚簇索引,如果是二级索引,存放的是主键值)
页合并和页分裂:
页合并:
当一个数据页的使用率低于一定阈值(50%)时,MySQL 就会将该页与相邻的空闲页合并成一个页面。
例如,数据页能存放7条数据,有两个相邻的数据页,一个存储 [1, 2, 3, 4],另一个是[5, 6]。当删除4时,会检查本页,本页数据只有三条,小于阈值,MySQL 就会将两个页面合并成一个页面,存储的数据变成 [1, 2, 3, 5, 6]
页分裂:
当一个数据页已经满了,而有新的数据要插入到该页时,MySQL 就会进行页分裂操作。
例如,数据页能存放5条数据,假设一个数据页已经存储了 [1, 2, 3, 4, 5],而有新的数据6要插入到该页中,MySQL 就会将该页拆分为两个页面,一个页面存储 [1, 2, 3],另一个页面存储 [4, 5, 6]。
页分裂是为了保证插入顺序的同时不大量挪动数据
采用逻辑删除可以减少页合并
采用批量顺序插入可以减少页分裂
简单地说就是 一个字段干一个字段该干的事,一张表干一张表该干的事
第一范式:每个属性不能再拆,例如地址需要拆成省、市、区、街道、小区等等多个字段才满足第一范式,否则如果是长文本的话,不满足第一范式
第二范式:所有信息必须直接和整个主键相关,不能只依赖不分主键(比如只依赖联合索引的部分),比如【(订单号,包裹号),收件人,包裹内容,收件人电话】,这里面(订单号,包裹号)是主键,而收件人和电话其实只依赖订单号,而不依赖包裹号,所以不满足第二范式
第三范式:非主键外的字段互不依赖,比如【订单号,收件人,驿站编号,驿站地址】,这里面驿站地址依赖的其实是驿站编号,而不是直接依赖订单号,所以不满足第三范式
满足范式的好处:
减少数据冗余
增强数据一致性
数据易于维护
一Java接口,它代表了Java中线程安全的队列,不仅可以多线程地访问元素,还添加了等待-通知机制,
可以实现在阻塞等待取元素,阻塞等待插入元素
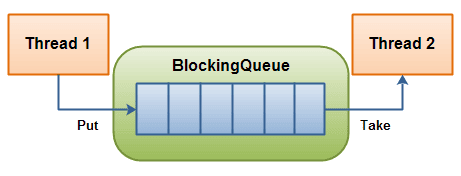
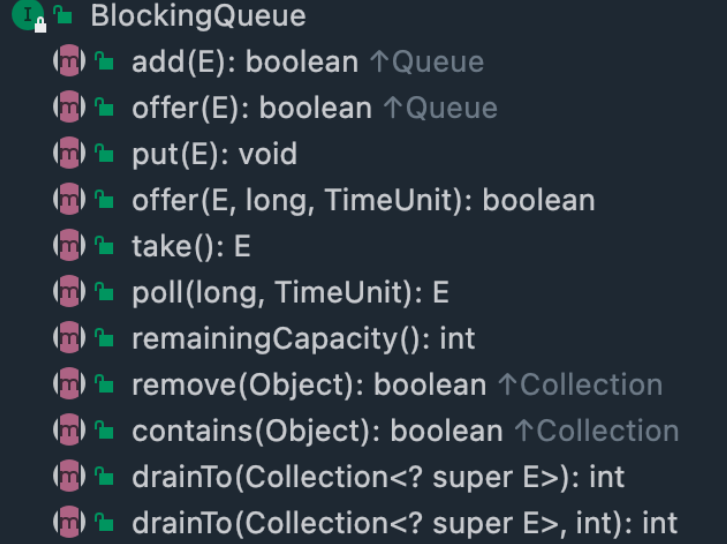
boolean add(E e) :将元素添加到队列尾部,如果队列满了,则抛出异常 IllegalStateException。
boolean offer(E e):将元素添加到队列尾部,如果队列满了,则返回 false。
void put(E e):将元素添加到队列尾部,如果队列满了,则线程将阻塞直到有空间。
offer(E e, long timeout, TimeUnit unit):将指定的元素插入此队列中,如果队列满了,则等待指定的时间,直到队列可用。
take():检索并删除此队列的头部,如有必要,则等待直到队列可用; 一般会上锁保证只有一个线程take到头部
poll(long timeout, TimeUnit unit):检索并删除此队列的头部,如果需要元素变得可用,则等待指定的等待时间。
boolean remove(Object o):从队列中删除元素,成功返回true,失败返回false
E poll():检索并删除此队列的头部,如果此队列为空,则返回null。
E element():检索但不删除此队列的头部,如果队列为空时则抛出 NoSuchElementException 异常;
peek():检索但不删除此队列的头部,如果此队列为空,则返回 null.
双端阻塞队列,继承于blockingQueue,可以想使用blockingQueue的API一样使用它

数组阻塞队列,有界的,且因为是基于静态数组实现的,一旦初始化,数组大小无法修改,且必须在构造时
初始化。
FIFO:队列操作符合先进先出
ArrayBlockingQueue并不能保证绝对的公平,即先到先得,因为还有线程调度的存在。想要保证绝对的公平
,可以在构造时置 fair=true
并发控制基于ReentrantLock和对应的Condition实现,读和写都得先获取锁。
基于链表实现的线程安全的阻塞队列
可实现头部和尾部的高效插入
可在构造时指定最大容量,若没指定,即为Integer.MAX_VALUE,即受限于内存大小,但还是有界的
相同点:
都是通过从condition通知机制来实现可阻塞的插入和获取
不同点:
1.一个基于链表,一个基于数组
2.ArrayBlockingQueue读和写都是一把锁,而LinkedBlockingQueue读和写两把锁,锁的粒度更小
具有优先级特性的无界队列,元素在队列里面的排序基于自然的排序,或者我们实现Compare接口来实现自
定义排序,适用于根据优先级来执行任务
延迟队列
AbstractQueueSynchronized 抽象队列同步器。是Java并发编程整个体系的基石,是用来构建锁或者同步组件的基础框架。它通过FIFO队列来实现线程获取资源的排队工作,并通过一个int变量来表示锁的获取状态
锁和同步器的关系
锁是面向锁的使用者,你调用就好了
同步器是面向锁的实现者,比如说你开发的时候需要自定义锁,而同步器可以为你提供实现锁的框架,帮你简化了实现,比如你不用去关心同步状态管理,阻塞队列的排队情况等等
独占意味着同一时刻只有一个线程可以获取同步状态,是互斥锁的基础
共享意味着多个线程可以同时获取同步状态,如 信号量,ReadWriteLock
FIFO虚拟双向队列,是CLH队列的变种
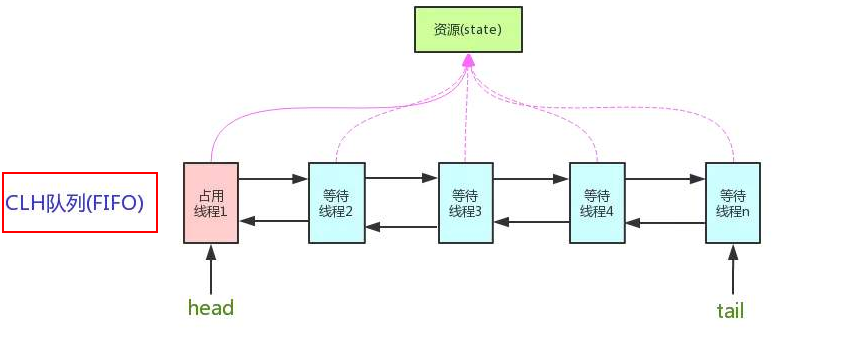
想要加锁失败后导致阻塞,阻塞就得排队,那么排队就得有队列
如果资源被占用,那么就得有一定的线程阻塞等待唤醒机制来保证锁的分配。FIFO
1 | //基本结构 |
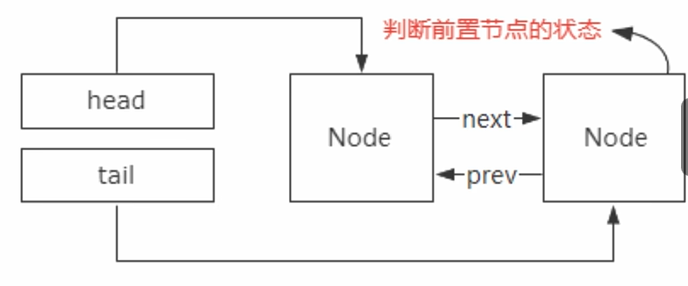
双向链表有两个指针,一个指向前驱节点,一个指向后驱节点
需要前驱节点:
能够实现常量级别的前驱节点查找,增删操作比单向链表更加高效和简单。
AQS在设计的时候为了去避免有线程节点因为异常而导致后置的节点无法被正确唤醒的情况,所以线程节点
在入队的时候都会去判断前置节点的状态,如果这时候没有前驱指针的话,那找到前驱节点就得从头开始遍历
了。
Lock接口里有个lockInterrupt方法,该方法就是说允许加入到阻塞队列里的线程节点被外部所中断。当阻塞队列里的线程被中断后,当线程节点并不会被立马删除,而是会被标记为cancelled状态,然后从尾节点找到离cancelled节点最近的正常节点进行唤醒。同样如果没有前置节点的话,得一个个往下遍历,查询性能很低
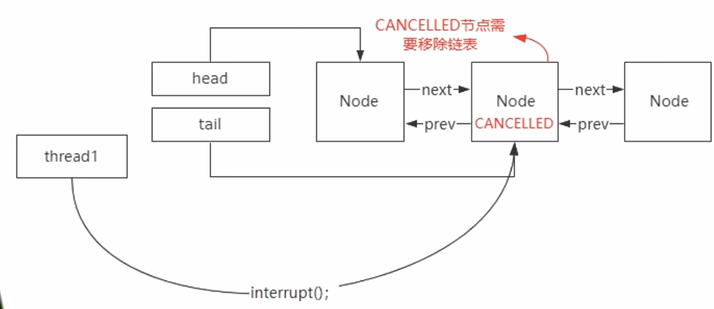
按照公平锁的设计,只有头结点的下一个节点才有必要去竞争锁。那么这里就涉及一个前置节点的判断,这个
是单向链表无法实现的。
总的来说就是存在需要高效查找前置节点的需求
ps:上面说的线程节点被外部中断后不会立马删除,那啥时候删除呢

这个官网没说这么做的原因,网上也没人提为啥这么干。我当时是觉得这样可以减少对头部节点的竞争。因为在高并发情况下,头结点一定是被频繁访问or修改最大的节点,因为头节点是释放锁or被唤醒的首选位置。从尾结点向前遍历就可以减少在头结点上的竞争。
查询数据时分页查,写入多个sheet页
看多线程
导出慢的话,改成异步,用户不需要等待,生成完成,用户点击按钮下载即可
Easy Excel基于事件流,一行一行读
内存占留的记录也不要太多,分批插入数据库
使用 .csv 文件代替 .xlsx:CSV 文件结构简单,解析更快,占内存更小
避免一次上传过大的 Excel(分批上传)
异步上传,先保存到对象存储服务器,消费者根据实际情况拉取进行处理
1 | InputStream inputStream = new FileInputStream("your_excel_file.xlsx"); |

1 |
|