垃圾回收器
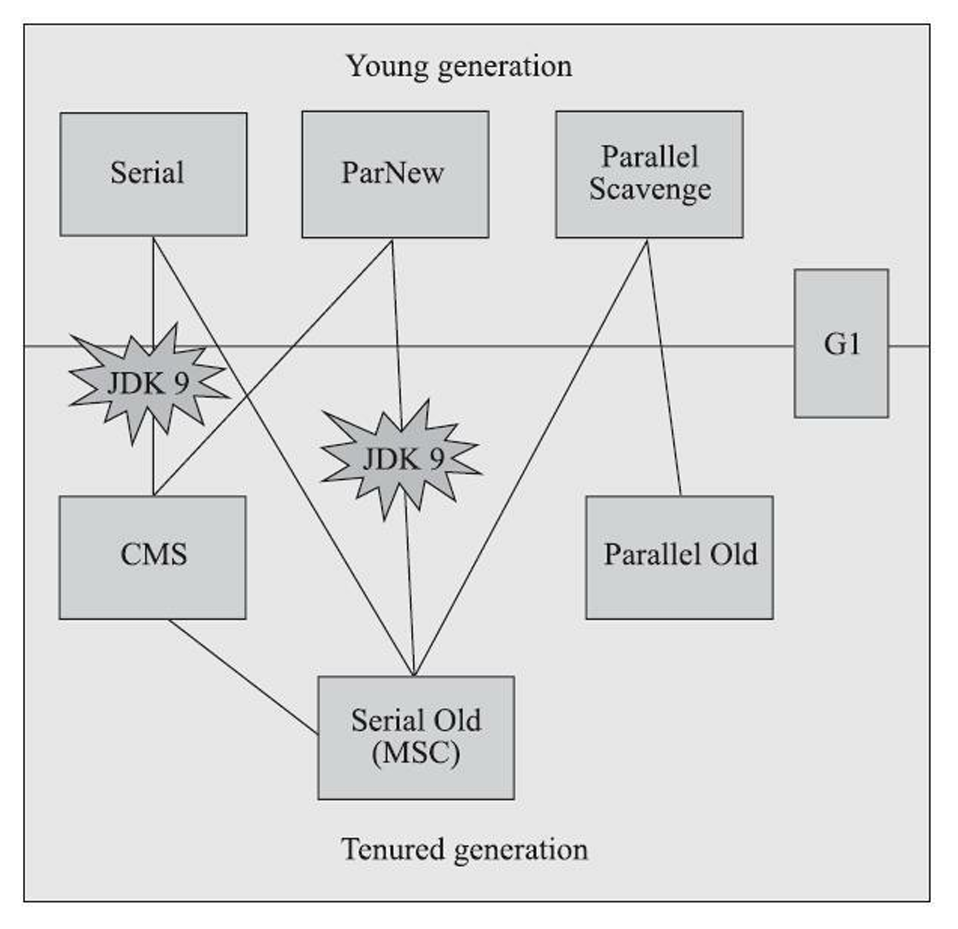
如果两个收集器之间存在连线,就说明它们可以搭配使用,图中收集器所处的区域,则表示它是属于新生代收集器抑或是老年代收集器
Parallel 吞吐量优先算法
CMS(concurrent mark sweep)垃圾回收器
JDK1.5时引入,JDK9被标记弃用,JDK14被移除
可以怎么说吧,它是第一款真正意义上的并发收集器,第一次实现了用户线程和垃圾收集线程一起工作
设计目标就是尽快能地减少STW
工作于老年代
它算法层面采用的是标记清除算法,并且也会stw
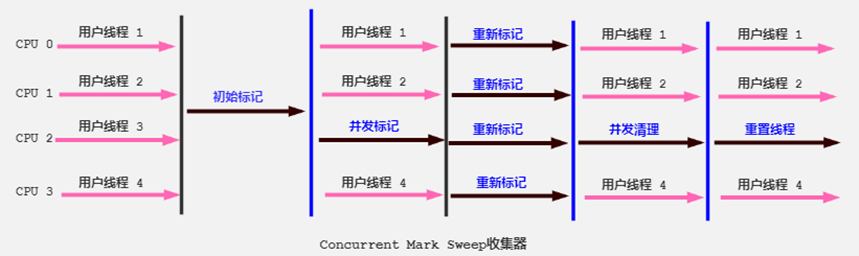
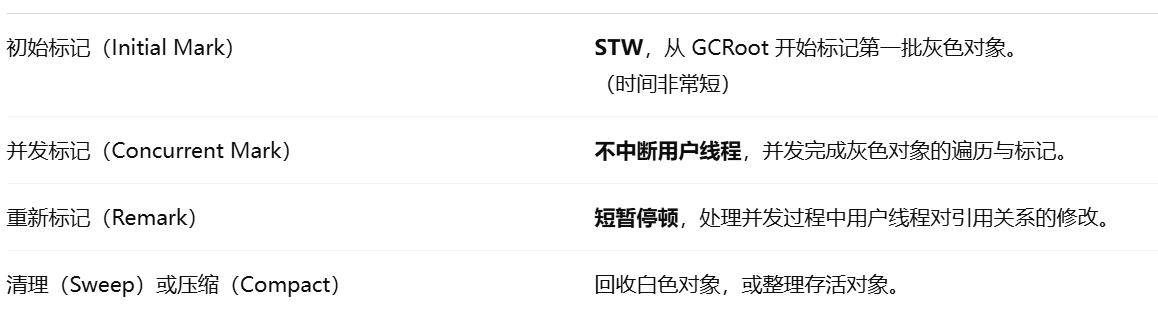
整个垃圾回收过程分为四个阶段:初始标记,并发标记,重新标记,并发清除
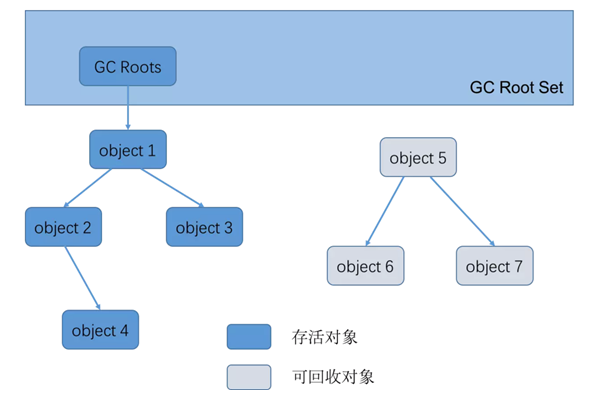
初始标记(STW):暂时时间非常短,标记与GC Roots直接关联的对象。
并发标记(最耗时):从GC Roots开始遍历整个对象图的过程。不会停顿用户线程
重新标记:(STW):修复并发标记环节,因为用户线程的执行,导致数据的不一致性问题
并发清理(最耗时)
因为最耗时的并发标记和并发清理是并发操作,虽然初始和标记会STW,但整体是低延迟的
由于采用标记清除算法,所以会不可避免地出现内存碎片的问题。且在给新数据分配内存时,也无法采用指针碰撞,只能维护一个空闲的内存地址列表
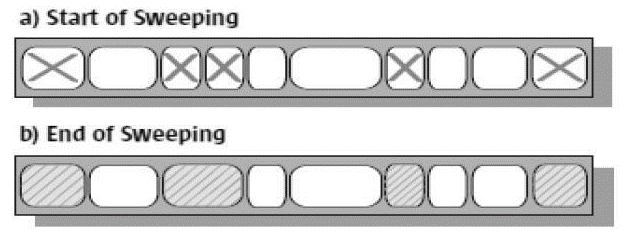
那问题来了,既然标记清除会产生内存碎片,为啥不把算法换成标记整理呢
因为你整理内存时,原来的用户线程要怎么用?因为你整理时会移动对象,移动对象时是会STW的。
优缺点
优点:并发收集,低延迟
缺点:内存碎片问题,占CPU资源(吞吐量可能会有所降低),
G1垃圾回收器
在JDK1.7版本正式启用,是JDK 9以后的默认GC选项
为了在大内存的情况下也有短暂的STW,G1是java 7后引入的一个新的垃圾回收器
相比于其他分代收集器(G1物理不分代,但逻辑分代)的全量回收,G1采用了增量回收,每次只回收垃圾最
多的region,且实现了STW真正意义上的可控,大内存的毫秒级别的STW
并行和并发:
并行:回收期间多个GC线程可同时工作,但用户线程STW
并发:G1拥有跟应用程序交替执行的能力,不会在回收长期阻塞应用程序
不分代收集
物理不分代:将堆分为不同的region
逻辑分代:但不要求相同代之间内存连续的
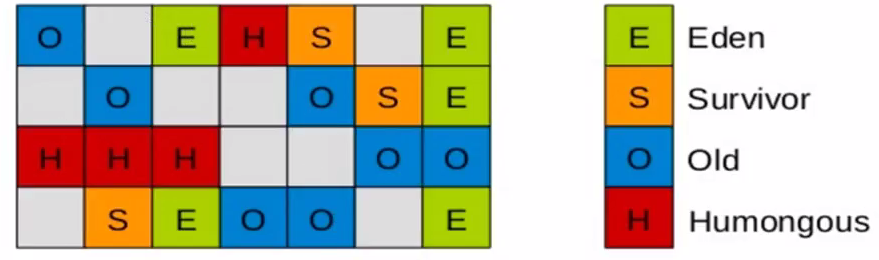
空间整合
内存回收是以region为基本单位的。region之间为复制算法,但整体可以看成标记整理,可以避免内存碎
片
可预测的停顿时间模型
可以让用户指定在一个长度为 M 毫秒的时间片段内,消耗在垃圾收集上的时间不过N毫秒
可简化调优
第一步:开启G1 -XX:+UseG1GC
第二步:设置堆的最大内存 -XMS
第三部:设置最大停顿时间 -XX:MaxGCPauseMillis
分区region
每个区大小相等,根据堆实际大小而定,整体被控制在1MB到32MB之间,在且生命周期相同
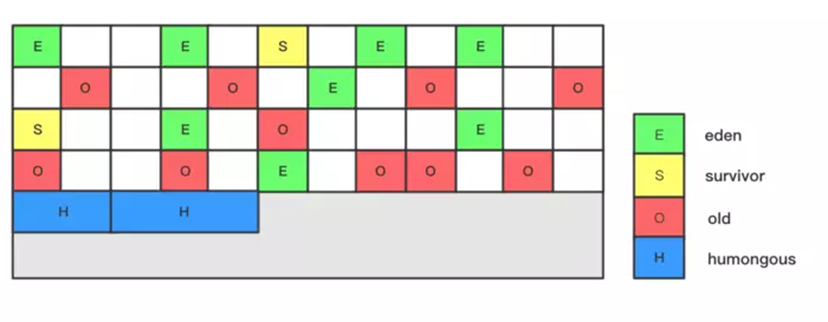
H区??:用来存放大对象,如果对象超过1.5region,就会放到这里
为啥要这个区
有些短期的大对象进入老年代不太好,会触发FullGC
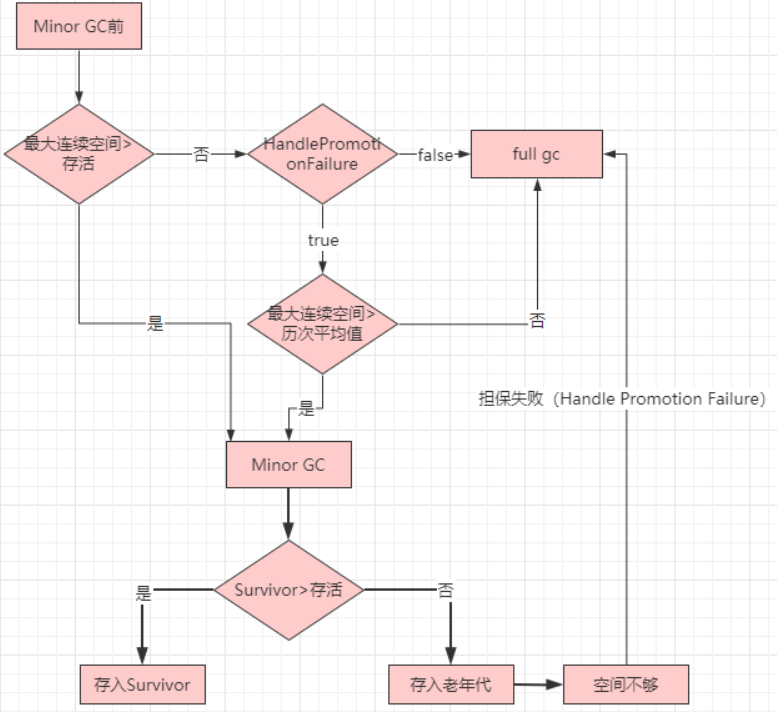
Minor GC:复制算法
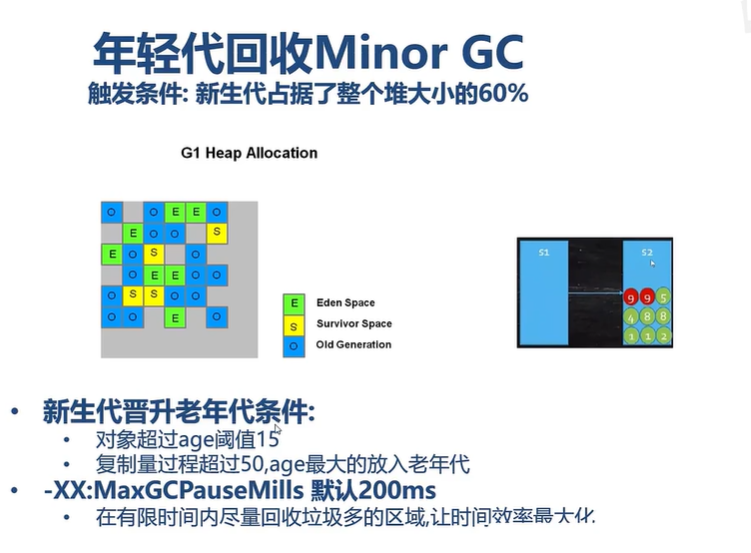
Mixed GC:标记整理算法
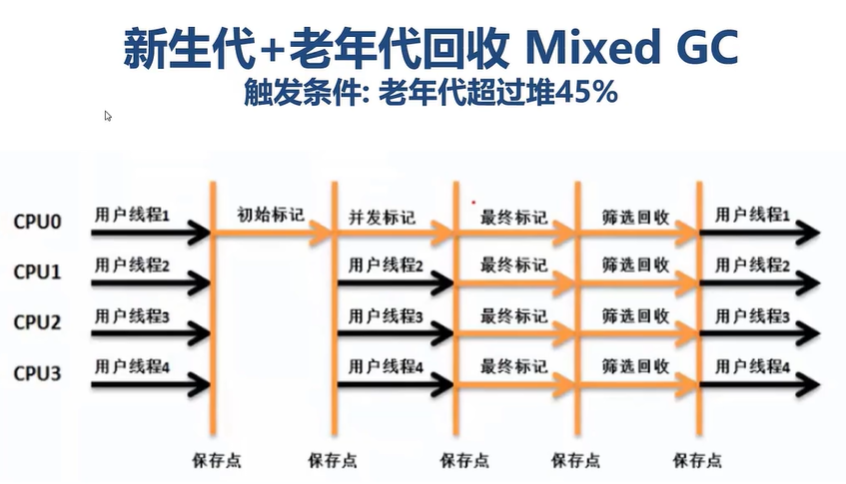
mixed GC过程
1.初始标记(STW):只是标记一下GCRoot能直达的对象
2.并发标记:并发完成GCRoot引用链,标记可达对象
3.最终标记(STW):确认垃圾
4.筛选回收(STW):开辟最多5%堆空间的内存用于标记整理的数据交换
STW200ms最多回收10%的垃圾最多区域,且回收会检查老年代是否低于45%
没达标就重新来一次,最多8次,8次没达标就FULLGC
oldGC
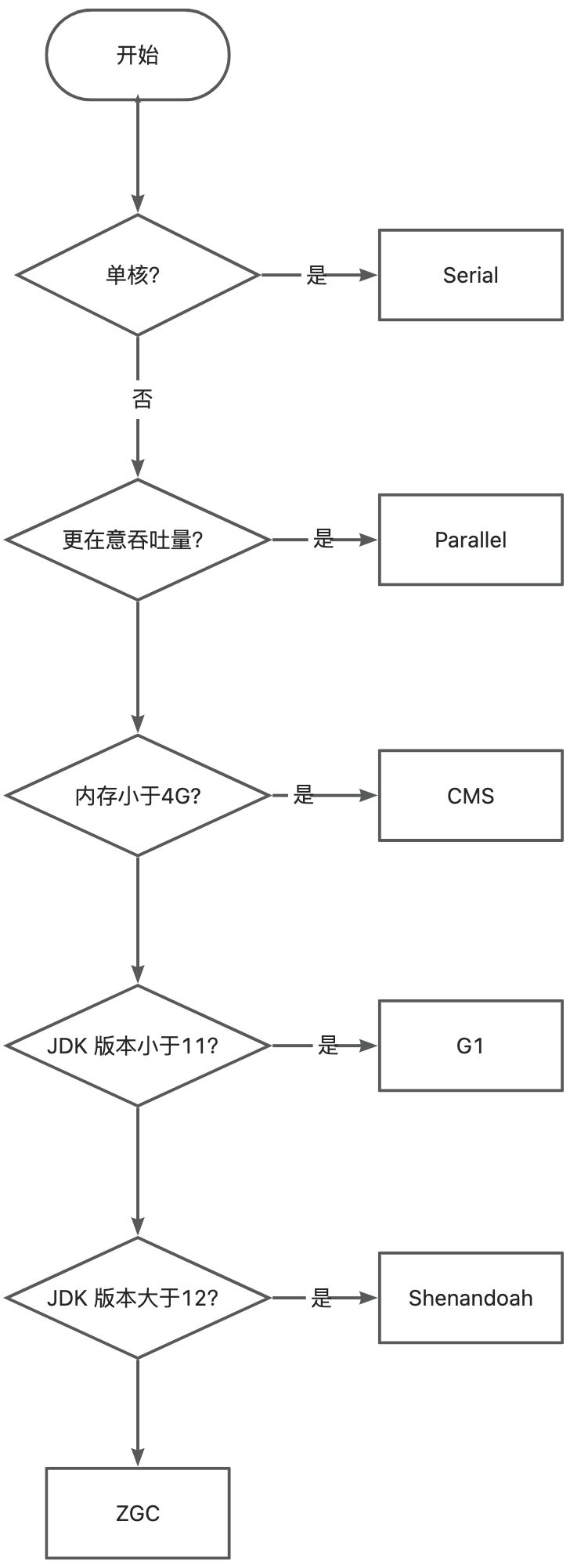
如何选择垃圾回收器?