哨兵
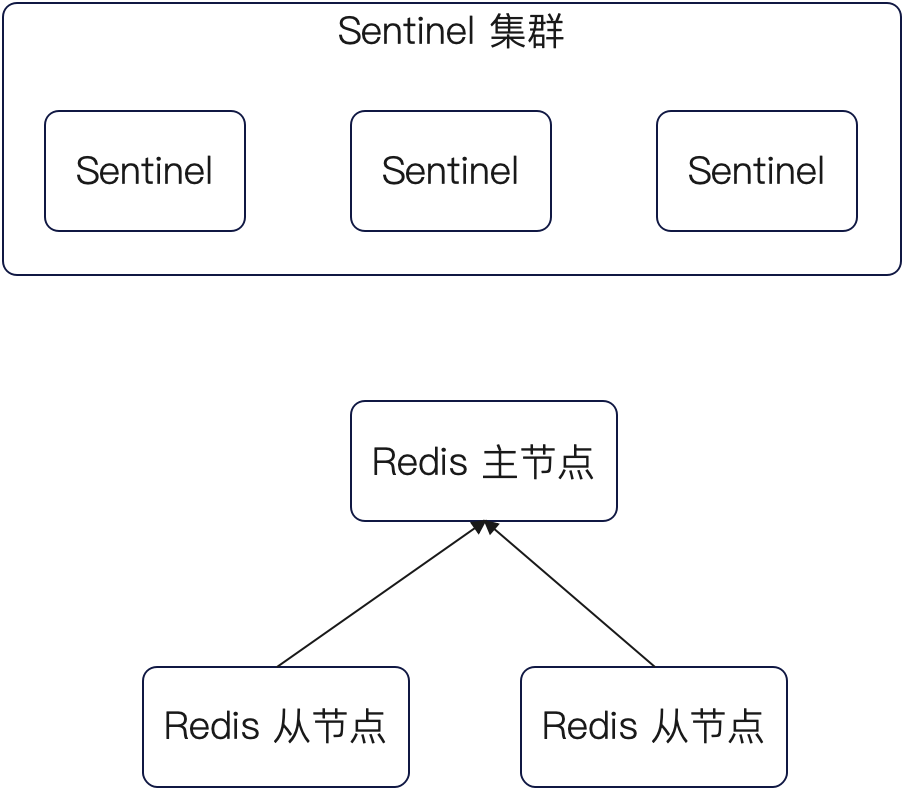
高可用主要来自两方面:
- 数据主从节点之间会有同步,如果主节点没了,从节点还有数据
- 有哨兵节点进行监控,选主。主节点崩了,重新选一个,继续向外提供服务
为什么要有哨兵?
在Redis的主从架构中,读写是分离的,如果主没了,那就没人来处理写命令了,也没法给同节点同步数据了
这时如果要恢复服务的话,需要人工介入,选择一个「从节点」切换为「主节点」,然后让其他从节点指向新
的主节点,同时还需要通知上游那些连接 Redis 主节点的客户端,将其配置中的主节点 IP 地址更新为「新主
节点」的 IP 地址。
redis 2.8后就推出了一种新模式,即Sentinel,干的事情就是监控主节点是否宕机
以及主节点宕机选主,然后把数据同步给从节点和客户端
有了哨兵后,客户端就可以 和sentinel通信,然后获取主节点信息

哨兵如何工作?
哨兵其实是运行在特殊环境下的一个Redis进程,所以它是一个节点,但实际落地哨兵也是有多个的。
主要负责三件事:监控,选主,通知
如何判断主节点是否真故障?
哨兵每隔一秒给主从节点发心跳包,主从节点在规定时间内回了那就是正常的。
如果没有哨兵就会将它们标记为「主观下线」。这个「规定的时间」是配置项 down-after-millisecon
参数设定的,单位是毫秒。
下线分主观和客观,主观就是唯心的即实际不一定的,从节点只会被标记为客观
主节点可能会因为请求压力大,导致网络阻塞从而回消息慢了点,不是真下线
然后为了避免这种情况,即增强纠错机制,哨兵也是议会制的,即多个哨兵都认为它宕机了它才宕机
增加容错度
具体是怎么判定主节点为「客观下线」的呢?
当有一个哨兵认为主节点下线后,就会通知其他哨兵,根据自身和主节点的网络情况,做出攒成和反对的投
票。
当这个哨兵的赞同票数达到哨兵配置文件中的 quorum 配置项设定的值后,这时主节点就会被该哨兵标记为
「客观下线」。
PS:quorum 的值一般设置为哨兵个数的二分之一加 1,例如 3 个哨兵就设置 2。
判断完后就会从从节点里选一个出来作为主节点
哪个哨兵来进行选主呢?
哨兵投票投出来的。一般会有候选者。
哪个哨兵节点判断主节点为「客观下线」,这个哨兵节点就是候选者,所谓的候选者就是想
当 Leader 的哨兵。
每个哨兵只有一次投票机会,如果用完后就不能参与投票了,可以投给自己或投给别人,但是只有候选者才能
把票投给自己。
那么在投票过程中,任何一个「候选者」,要满足两个条件:
第一,拿到半数以上的赞成票;
第二,拿到的票数同时还需要大于等于哨兵配置文件中的 quorum 值。
举个例子,假设哨兵节点有 3 个,quorum 设置为 2,那么任何一个想成为 Leader 的哨兵只要拿到 2 张赞成票,就可以选举成功了。如果没有满足条件,就需要重新进行选举。
如果某个时间点,刚好有两个哨兵节点判断到主节点为客观下线,那这时不就有两个候选者了?这时该如何决定谁是 Leader 呢?
简单来说,谁先发现有个节点故障了,谁就是候选者,如果只有一个候选者,一般就是它成为Leader,如果
同时有多个候选者,看其它投票者先给谁投票,谁就是Leader
主从故障转移的过程是怎样的?
- 从已下线的主节点下的从节点里挑一个出来
- 让从节点修改copy目标
- 将新主节点的ip地址和信息,通过pub/sub通知到客户端里去
- 继续监视已下线的主节点,如果它复活了,那就将它设置为新主节点的从节点
步骤一:挑选过程
先过滤掉网络不健康的从节点,然后三轮考察,一是优先级,二是复制进度,三是ID号
前两个都是谁大谁win,id号是谁小谁win
winer出来后,然后向这个「从节点」发送 SLAVEOF no one 命令,将这个「从节点」转换为「主节点」
步骤二:让从节点更改
哨兵向原从节点发送 slaveof 命令
步骤三:通知客户的主节点已更换
经过前面一系列的操作后,哨兵集群终于完成主从切换的工作,那么新主节点的信息要如何通知给客户端
呢?
这主要通过 Redis 的发布者/订阅者机制来实现的。每个哨兵节点提供发布者/订阅者机制,客户端可以从哨兵订阅消息。
哨兵提供的消息订阅频道有很多,不同频道包含了主从节点切换过程中的不同关键事件,几个常见的事件如下:
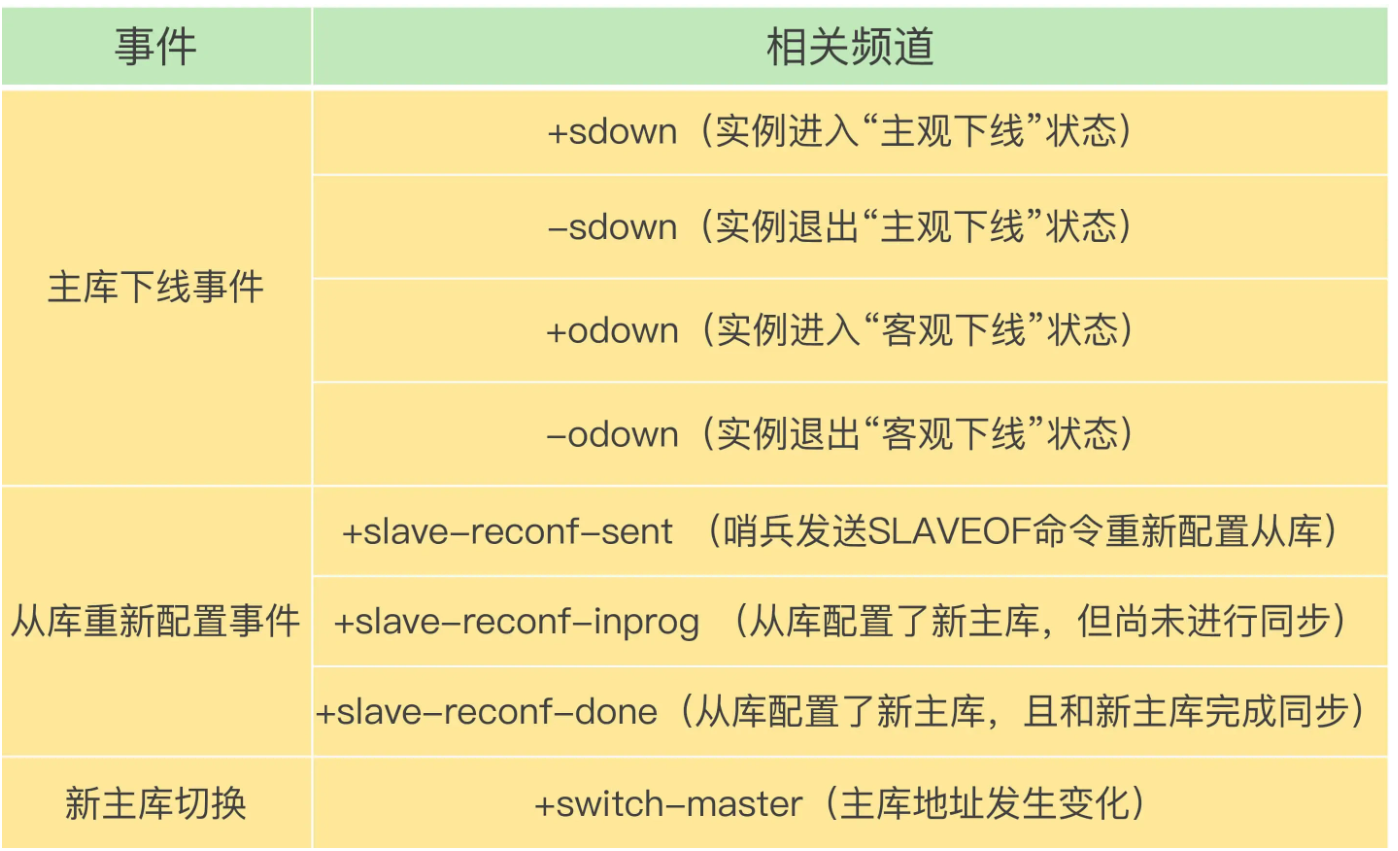
客户端和哨兵建立连接后,客户端会订阅哨兵提供的频道。主从切换完成后,哨兵就会向 +switch-master 频道发布新主节点的 IP 地址和端口的消息,这个时候客户端就可以收到这条信息,然后用这里面的新主节点的 IP 地址和端口进行通信了。
通过发布者/订阅者机制机制,有了这些事件通知,客户端不仅可以在主从切换后得到新主节点的连接信息,还可以监控到主从节点切换过程中发生的各个重要事件。这样,客户端就可以知道主从切换进行到哪一步了,有助于了解切换进度
步骤四:将旧主节点变为从节点
故障转移操作最后要做的是,继续监视旧主节点,当旧主节点重新上线时,哨兵集群就会向它发送 SLAVEOF 命令,让它成为新主节点的从节点
哨兵集群如何组成?
在配置哨兵信息的时候,只需要设置这几个参数,主节点名字,主节点的IP地址和端口号以及 qunorum值
不需要填其他哨兵的信息,哨兵节点之间是通过订阅发现机制来互相发现的
在主从集群中,主节点上有一个名为 sentinel:hello的频道,不同哨兵就是通过它来互相发现的,
实现互相通信的
哨兵主节点只要发布信息到到这个频道上,哨兵b,c订阅了这个频道,就可以互相通信了,集群就这样形成了
哨兵如何知道从节点信息?
主节点知道所有从节点的信息,所以从节点每秒10s就向主节点发INFO请求获取所有从节点的信息
redis使用最佳实践
1.对于一些更改操作多的数据,可以考虑使用hash存储
2.使用时避免存储过大的数据块
3.线上的一些命令使用
不要用keys,会扫描所有key,导致主线程阻塞
避免使用FLUSHALL,FLUSHDB删除数据库
5.合理设置key的过期时间
4.高并发场景,对于一些热点key要做好监控告警措施
5.根据redis的使用场景,选择其持久化策略
迭代器的fail-safe和fail-fast
Fail-safe
Fail-safe迭代器在迭代过程中如果检测到集合的结构被修改,将抛出ConcurrentModificationException。这
种行为主要是通过迭代器中的一个modcount的计数器实现的,元素增or删都会发生变动。迭代器遍历时都会
检查这个计数器是否与size符合,不符合就抛错
主要集合
HashMap,Set,ArrayList等
优点:快速响应错误,帮助开发者早点知道错误
缺点:多线程环境下,如果不进行外部同步,容易抛错
Fail-fast
Fail-fast迭代器允许在迭代过程中对集合进行修改,不会抛concurrentModification异常但不会在原集合上修
改,而是在集合的副本上修改,即修改不会影响到迭代过程。这样的话这种机制在多线程环境下更加安全
copyonwrite….
concurrenthashmap….
ArrayList和LinkedList
ArrayList底层是个数组
LinkedList双向链表,添加和删除元素比ArrayList性能高一点,get()和set()就要比其低点,只不过这里的比较基于大数据量来说,少数据量其实没啥可以忽略不计
GC常见问题
system.gc()?
finalize()?
是一个protected方法,我们可以去重写这个逻辑。回收对象时会去调用这个方法,但最多只能调用一次
STW
任何垃圾回收器都是会STW的
开发时不要使用system.gc(),会STW!!!
内存泄漏是什么
简单地说,就是本该回收即不会再被使用的内存没被回收,俗话讲就是占着茅坑不拉屎
内存泄漏多了就会发生内存溢出即OOM
什么情况下会发生?
安全点和安全区域
哪些情况新生代会进入老年代?
- 新生代gc后survivor区不够存放存活下来的对象,会将对象通过内存担保机制晋升到老年代
- 大对象直接进入老年代,-XX:PretenureSizeThreshold=1048576配置,因为大对象在新生代发生来回复制的话,影响gc性能
- 长期存活的对象,比如经过了15次gc后还存活的对象,由-XX:MaxTenuringThreshold=10配置
- 但是这个年龄是会动态调整的,每次新生代GC后,JVM都会动态调整这个阈值大小,调整的方式是,从年龄为1的所有对象向上累加,直到内存大小大于-XX:TargetSurvivorRatio(默认50%)
- 例如总共有100MB新生代大小,阈值就是50MB,累加年龄为1的对象,此时10MB,累加年龄为2的对象,此时25MB,累加年龄为3的对象,此时45MB,累加年龄为4的对象,此时55MB>50MB,那么阈值就被设置成4,下次GC时年龄大于等于4的对象会晋升到老年代
- 算法源码地址:jdk/hotspot/src/share/vm/gc_implementation/shared/ageTable.cpp at jdk8-b120 · openjdk/jdk (github.com)
- 为什么默认是15?因为对象头里有个age字段,占4个bit位,所以最大就是15,初始值设为最大,然后依靠后面动态调整。那这样的话,小于等于15都可以吧,反正有动态调整,为什么选15呢?因为-XX:MaxTenuringThreshold其实是限定了一个动态调整年龄范围的上限,设为15能让动态调整更为灵活
什么时候full gc?
- 程序代码中调用System.gc()
- 当新生代对象需要晋升老年代或大对象直接在老年代开辟内存时,老年代空间不足
- 空间分配担保失败
- 元空间或永久代(JDK7以前)空间不足,full gc回收未使用的类(需要这个类没有对象,所以要gc回收)和元数据
- 执行CMS GC的过程中同时有对象要放入老年代,而此时老年代空间不足(可能是 GC 过程中浮动垃圾过多导致暂时性的空间不足),便会报 Concurrent Mode Failure 错误,并触发 Full GC。
- G1内存回收速度赶不上内存分配的速度,也会导致Full GC
什么是Concurrent Mode Failure
CMS收集器在工作时,因为用于线程和垃圾回收在并发标记和并发清除阶段是并行的,此时老年代空间不足(例如浮动垃圾过多,用户创建对象频繁,新生代晋升老年代),就会出现Concurrent Mode Failure
出现Concurrent Mode Failure会怎样
触发Full GC