wireshake使用
基本使用
【网络顶级掠食者 Wireshark抓包从入门到实战】https://www.bilibili.com/video/BV12X6gYUEqA?vd_source=cae07b1dce3e6abe67fcf72c43031ede
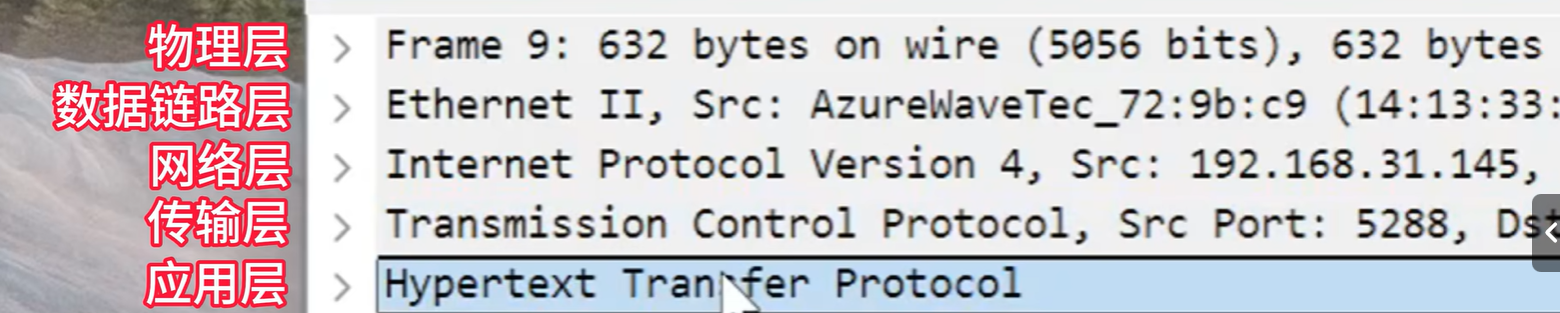
过滤器:
显示器和捕获过滤器,用来筛选我们想要的信息

显示过滤器,哪里想捕获点哪里
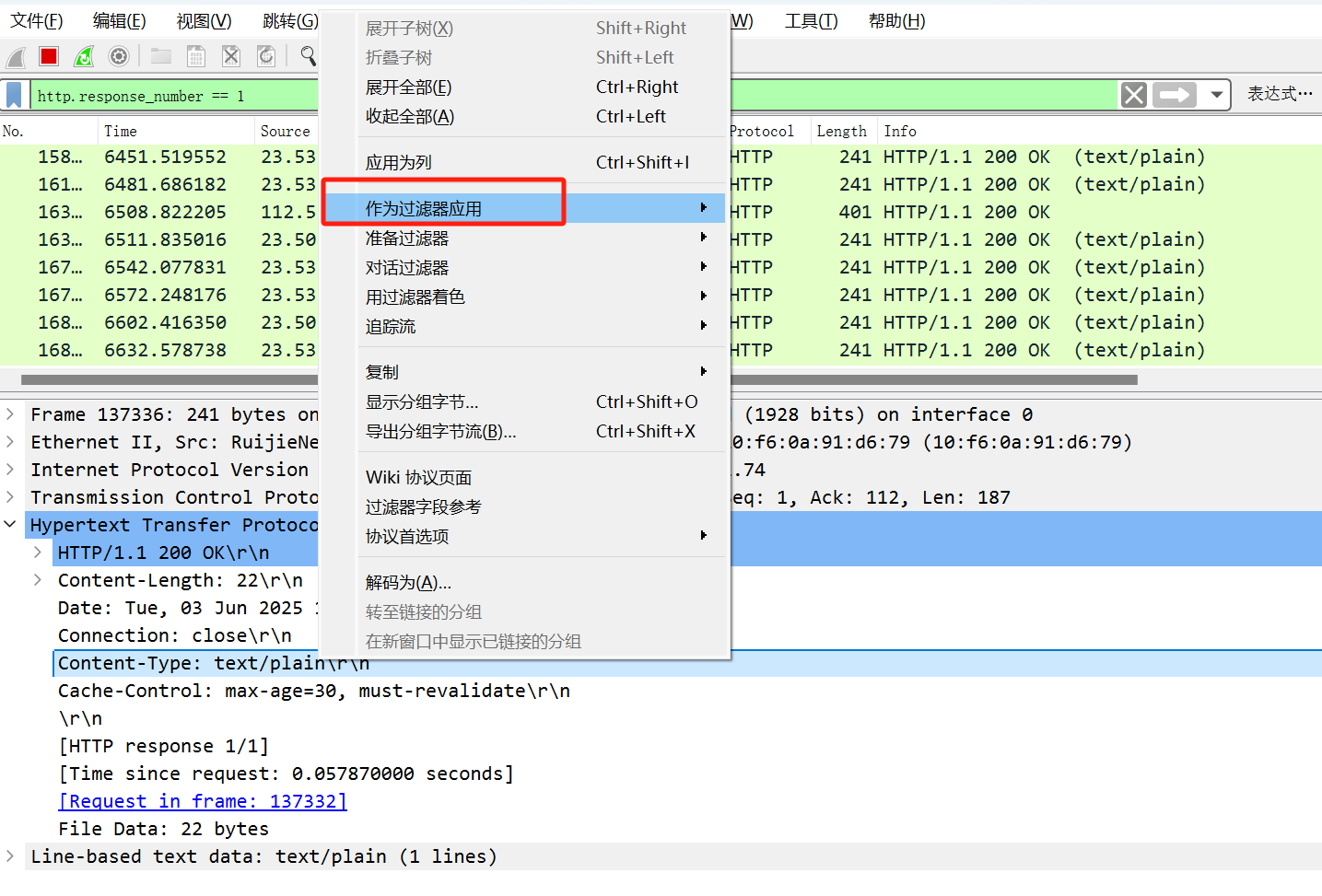
捕获过滤器,数据量大的情况下性能更好
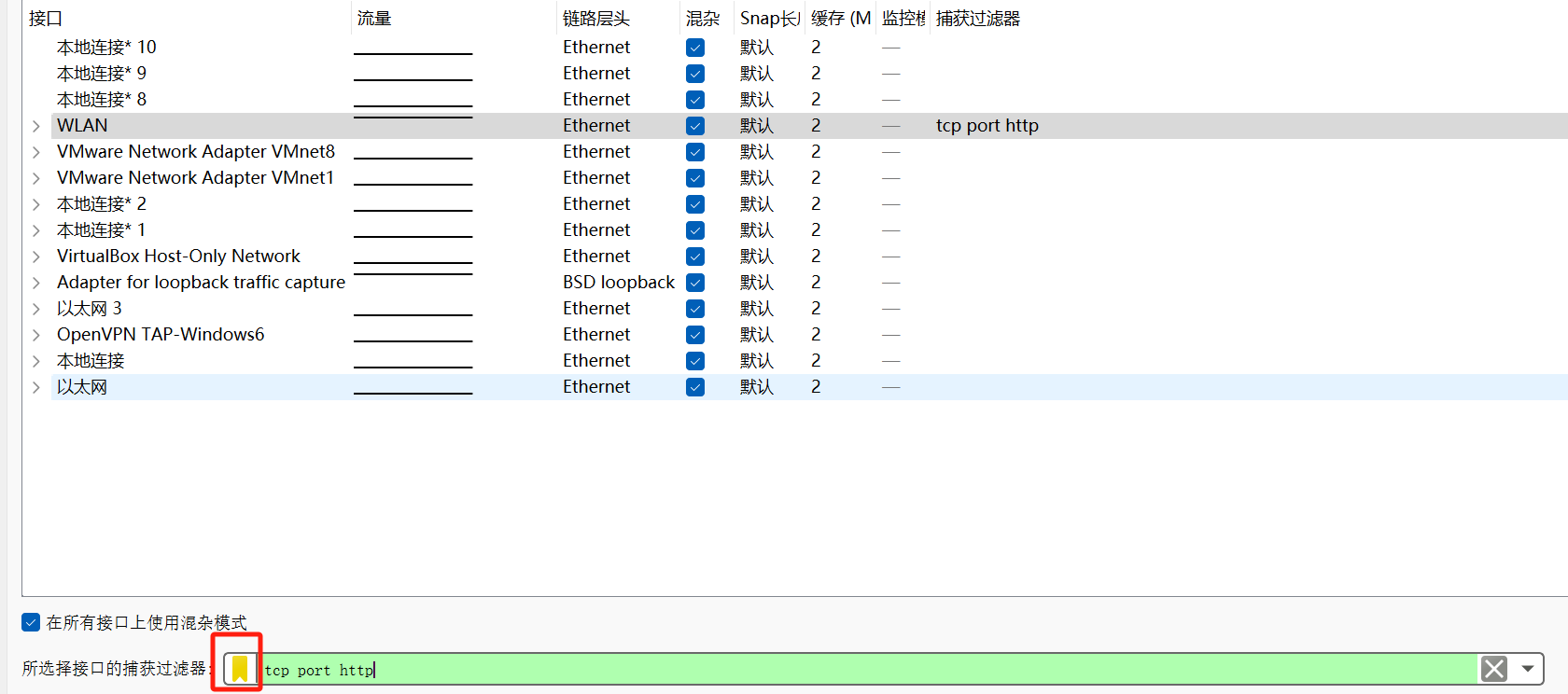
实战
wiresake分析TCP三次握手

【网络顶级掠食者 Wireshark抓包从入门到实战】https://www.bilibili.com/video/BV12X6gYUEqA?vd_source=cae07b1dce3e6abe67fcf72c43031ede
过滤器:
显示器和捕获过滤器,用来筛选我们想要的信息
显示过滤器,哪里想捕获点哪里
捕获过滤器,数据量大的情况下性能更好
wiresake分析TCP三次握手
客户端发送DNS访问请求
当客户端需要解析域名时,就会构造一个DNS(应用层的协议)请求,并通过UDP协议将其发送到DNS
服务器进行域名解析。一般是本地的DNS缓存或者配置的比如ISP的DNS服务器或者一些公共DNS服务器
比如google的8.8.8.8
查询请求的构造
DNS请求一般包含什么
标识符:请求唯一ID,由客户端发送,服务端响应时返回
标志:标志字段,包括查询,响应
问题计数:表示查询请求中的问题数
问题区域:查询的域名
客户端发送UDP数据包
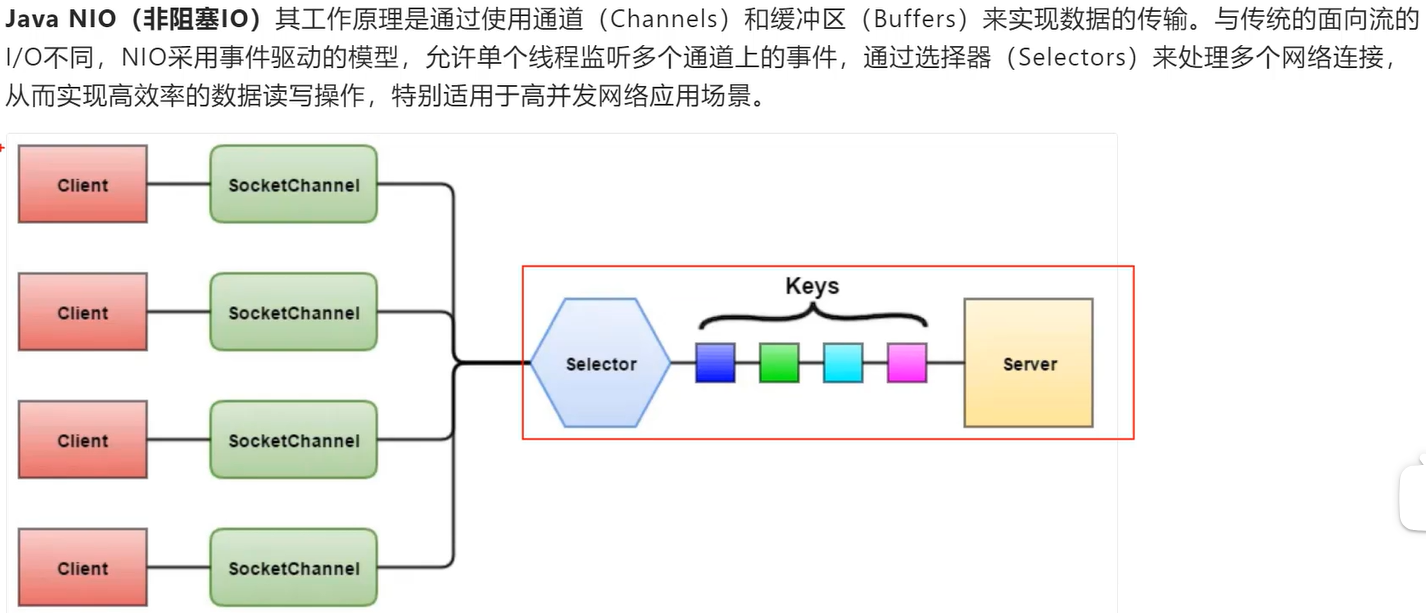
早期tomcat采用的网络IO模型:一个连接即一个线程
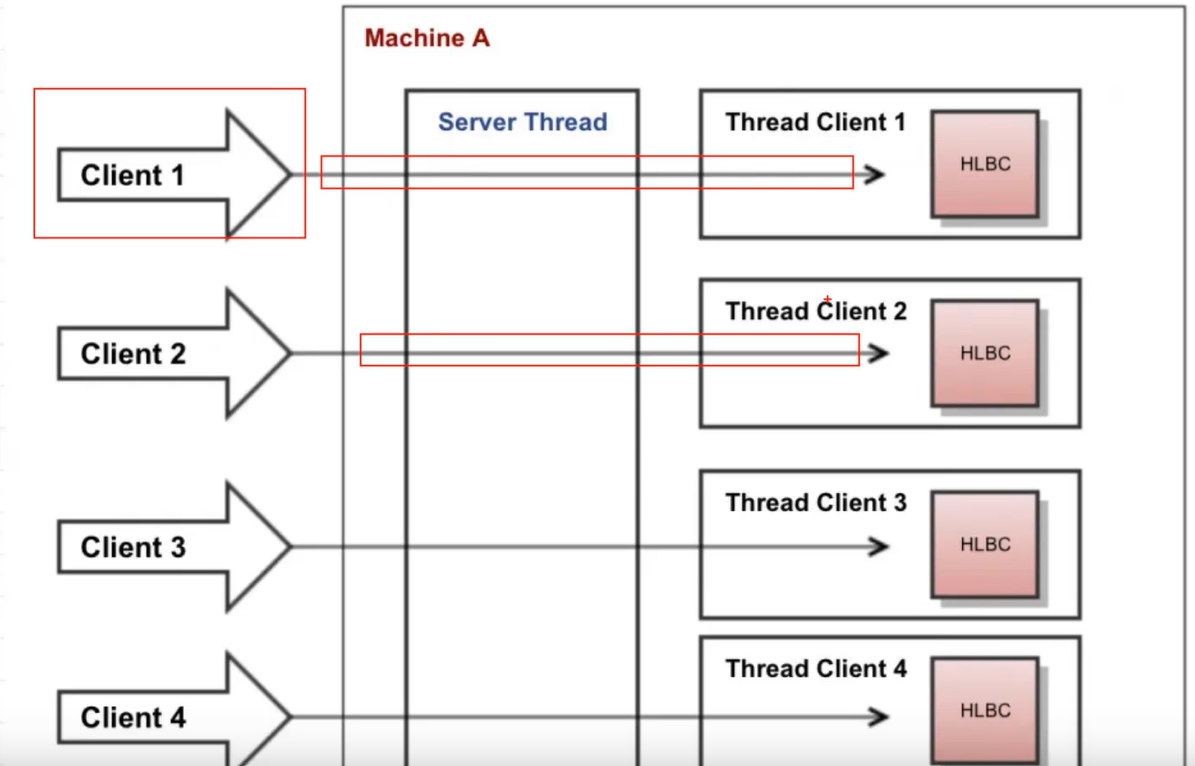
Java NIO:用尽量少的线程管理尽量多的网络连接(原生的NIO是 单线程管理多个连接)
Reactor响应式编程

单线程Reactor
多线程Reactor
Reactor和Java NIO的关系
1.对NIO进行了扩展,NIO对多线程支持不好,得自己封装

推特两个业务:发布推文和主页时间线
两种方案:
读扩散
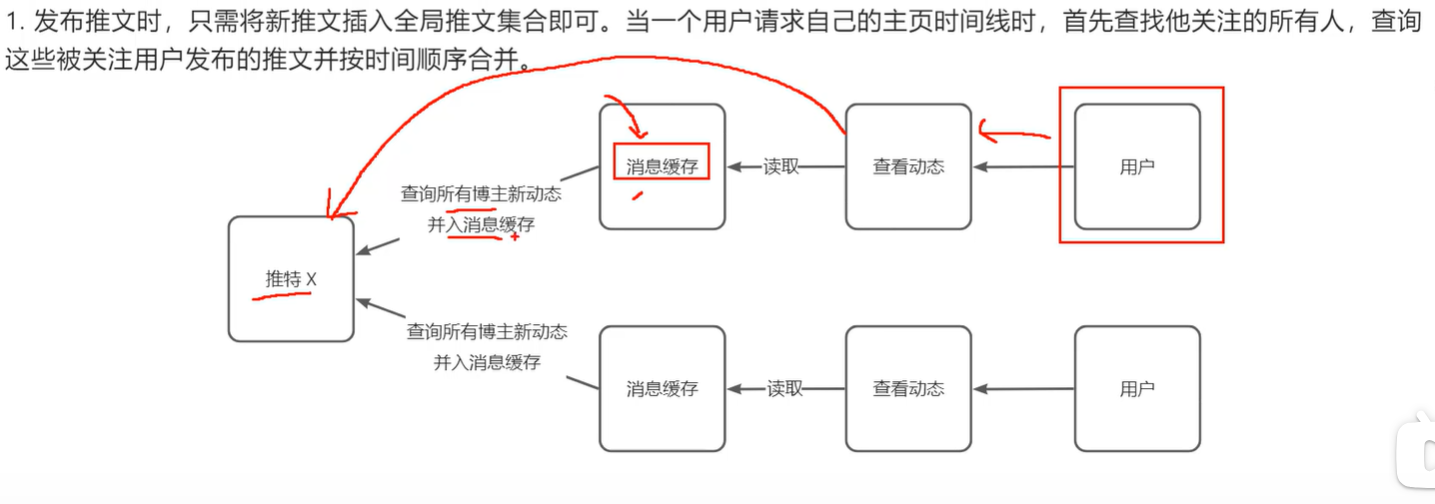
不足:读取压力大
写扩散
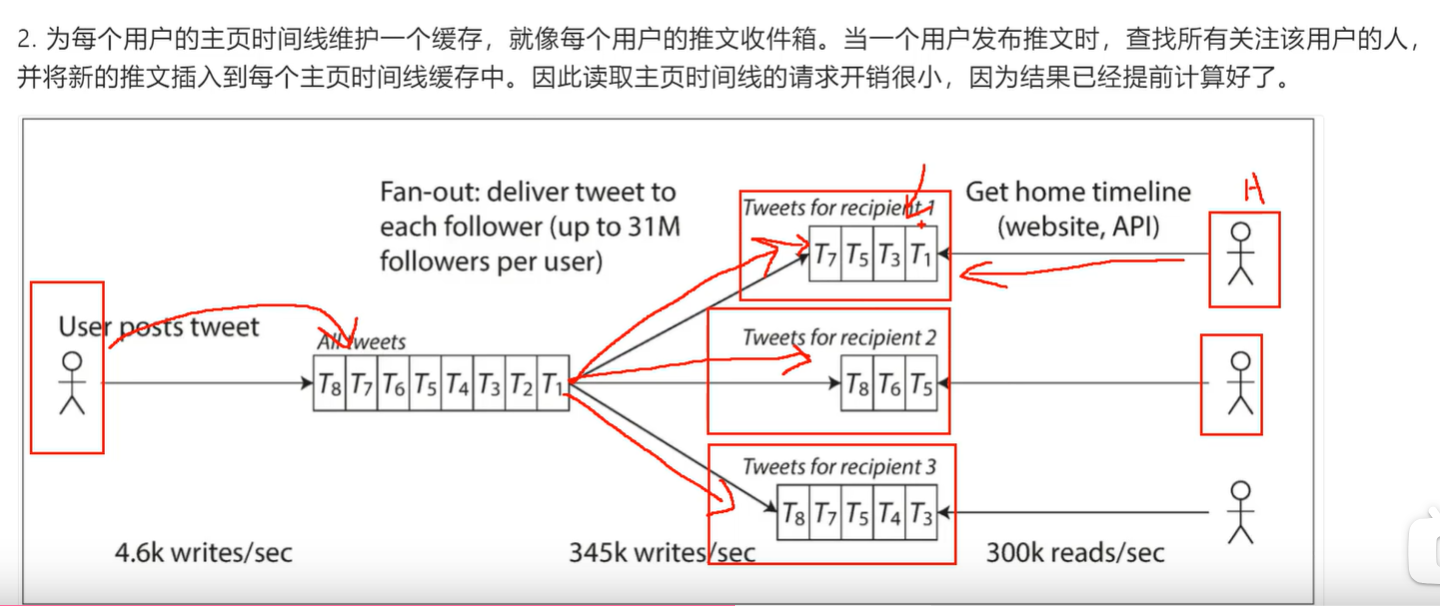
写要比读的好,因为发推的频率要比主页刷新的频率低很多
不足:有些up的博主粉丝量大。写入的粉丝收件箱的数量很大,写入请求量级巨大
在推特的例子中,粉丝数是一个重要参数,推特采用了两种架构的结合

基于责任链模式实现某跨服活动,依次校验红包、库存、物流等正向触点,基于Spring的Bean发现实现高扩展设计,使用单例模式减少每次执行时的内存开销,线上用户订单留存率提升约4%:
外部actor查询时通过launch()协程来优化handler方法,实现一个actor同时处理多条查询请求。因为actor本
身就只能处理一条命令
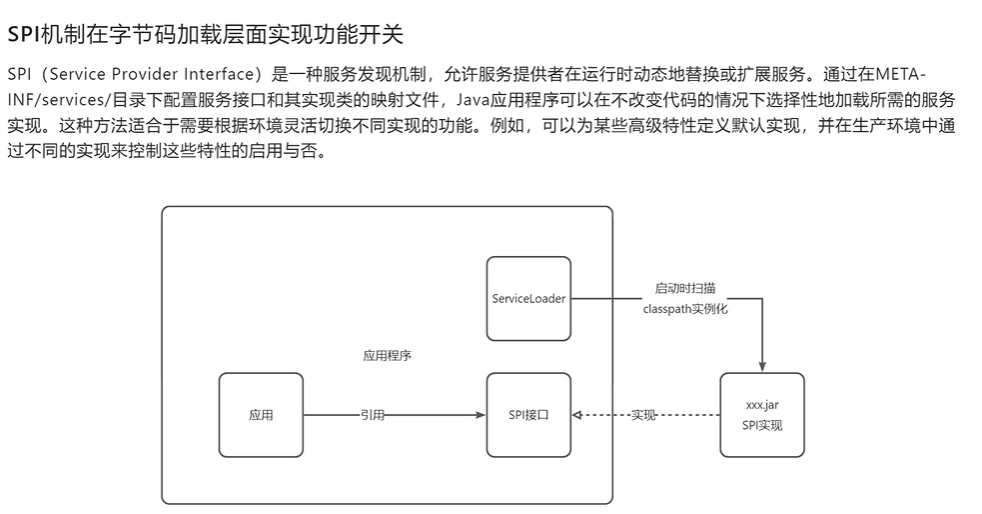
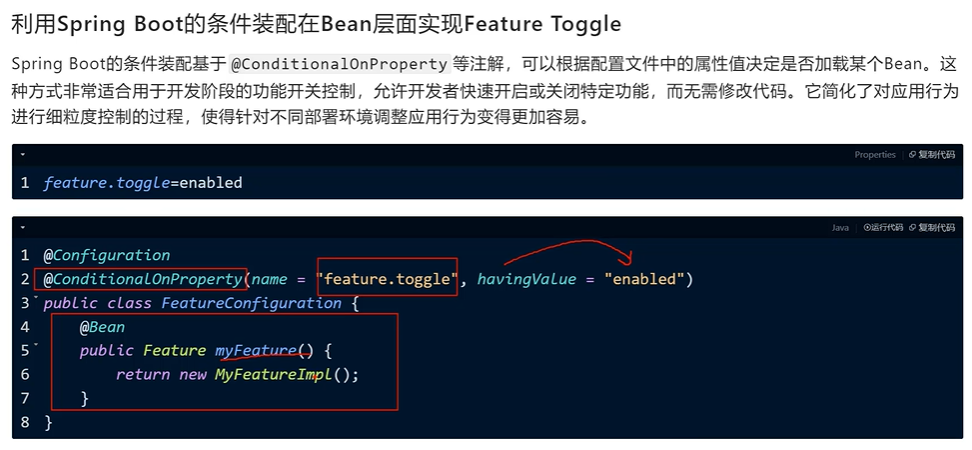
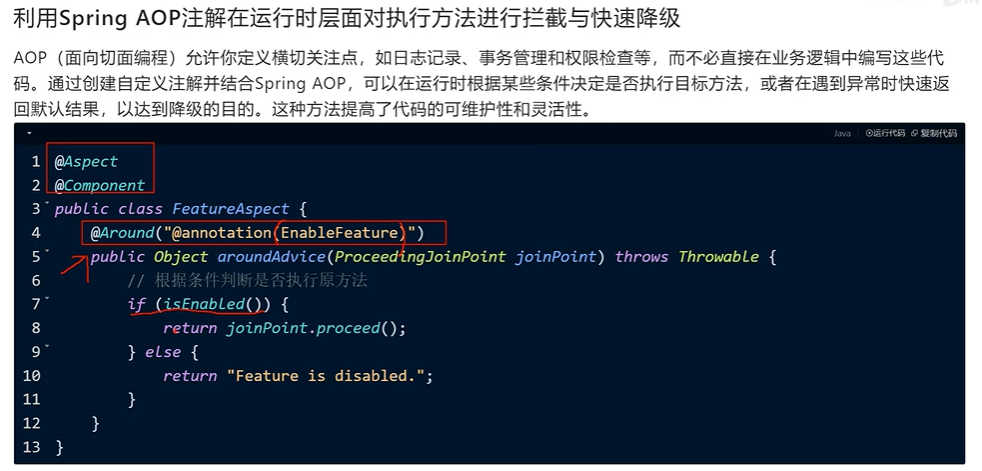

PS:isEnable() 如何感知到配置文件内容的变化
1.结合配置中心

2.将变量的修改应接口的方式暴露出去

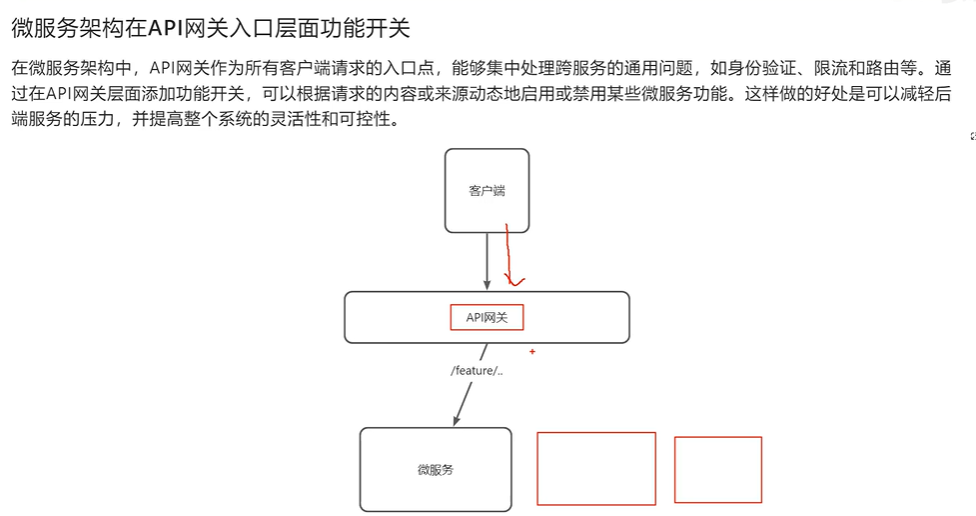
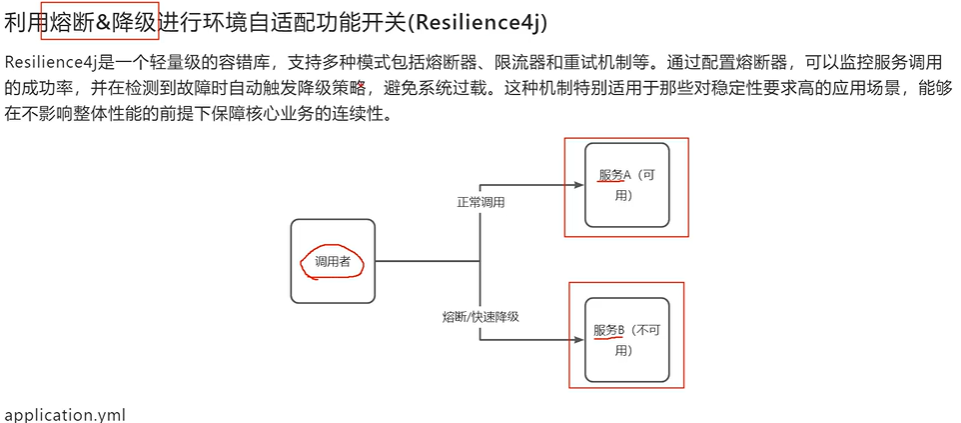



可以先写本地,再由统一的日志收集程序去读取并写到库里

利用Spring validation的分组校验功能可以实现
同一个请求对象,同一份校验注解,不同接口,不同的校验逻辑。
User
1 | class User{ |
GROUP
1 | interface Groups{ |
Controller
1 | void methodA( String xx) |
gobal exception handler


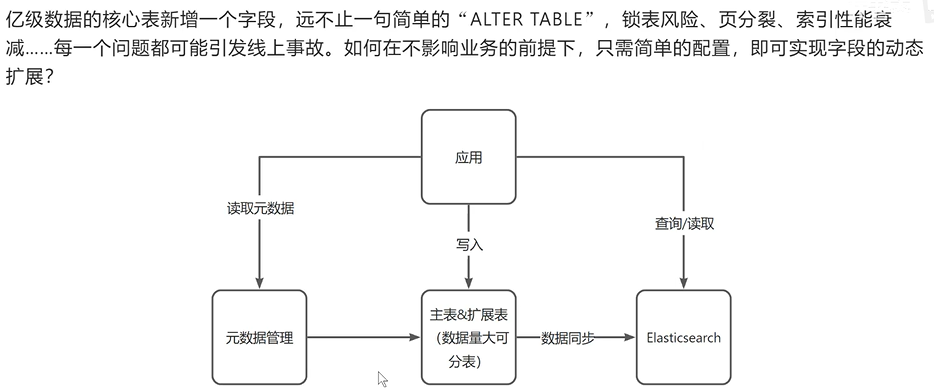
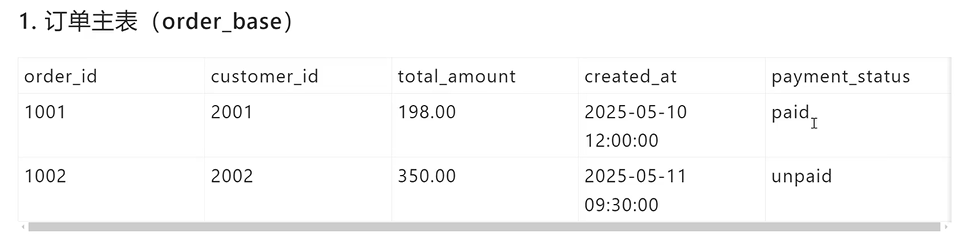
就是那些灵活变化的字段独立出去变成一张表,主表为固定不变的字段
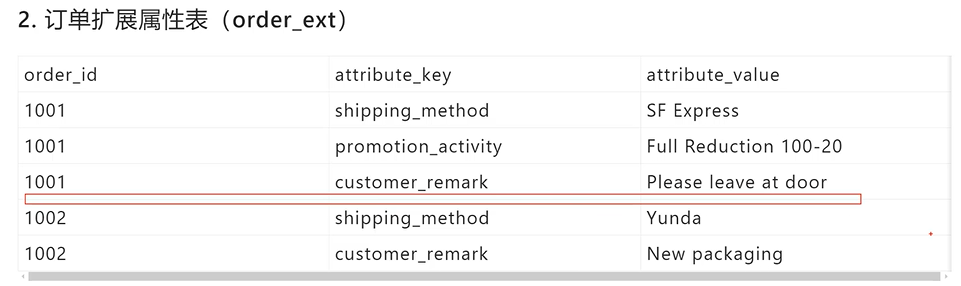
但ext表的数据增长量会比较大,针对这个情况可做分表(按id键分)
查询的话,基于ES进行全文查询,插入DB后同步到es,这个过程可以异步的(mq,flinkCDC监听binlog)等
方式进行处理