自研nameServer
为什么要自研,市面上的不能直接拿来用吗?
你自研的有什么优点吗?你当时是怎么设计的?
heartBeat?
为什么要自研,市面上的不能直接拿来用吗?
你自研的有什么优点吗?你当时是怎么设计的?
heartBeat?
录制:生生的快速会议
日期:2025-06-16 20:44:17
录制文件:https://meeting.tencent.com/crm/2kedrqnY69
访问密码:CL27
转写:转写_生生的快速会议
日期:2025-06-16 21:03:09
转写文件:https://meeting.tencent.com/ctm/2qvEaQQObe
访问密码:8YEB
核心概念:topic,partition,replics(副本)
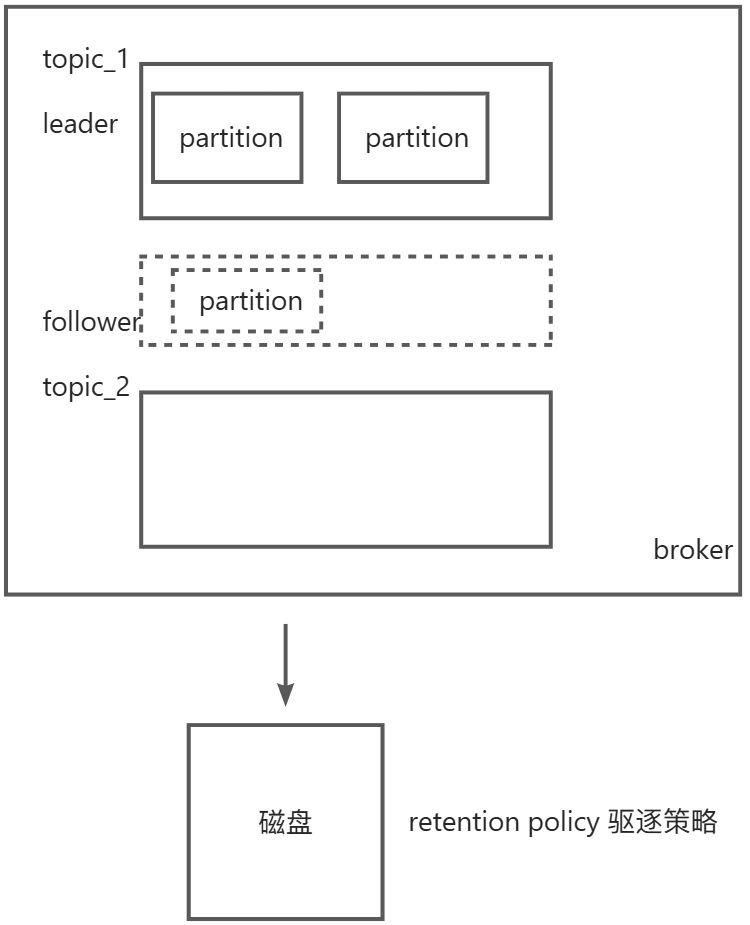
partition物理概念,topic逻辑概念
kafka快是指什么,是指高效传输海量数据的能力
基础:磁盘顺序IO 和 零拷贝
粘性分区 nextPartition
在途请求
request->response (同时请求)
topic 代表就一队列,为了提供一个topic queue的吞吐量,就对一个topic里的数据进行了分区(partition)
生产者和消费者实际上操作的是分区
一台Kafka服务器叫做Broker,Kafka集群就是多台Kafka服务器:
多个consumer组成一个group
项目描述: 自研分布式任务调度框架,作为企业级任务调度中心,用于管理和控制大规模定时任务的创建、调度和执行。基于gRPC+Netty搭建高性能通信核心,使用自研消息队列实现全异步任务处理。实现高效的任务调度、负载均衡、服务发现以及容错保护等多种功能,确保系统在高并发下的稳定性和可扩展性。
我负责的部分:
• 针对服务注册与发现实现自研NameServer,基于Distro协议实现AP一致性,支持动态服务发现和负载均衡
• 针对任务处理构建异步消息队列架构,实现任务创建、参数变更、状态同步等功能的异步处理。
• 实现多种负载均衡策略,如最小调度次数策略、动态分组拆分,支持Worker节点动态上下线和智能分配。
• 实现框架弹性扩展,支持应用级别锁隔离、任务重试机制、多级延时队列、死信队列等容错功能。
• 实现了高精度任务调度,基于时间轮算法实现毫秒级定时任务调度,支持CRON表达式和动态参数调整。
• 基于gRPC+Protobuf设计可扩展通信协议,支持用户自定义任务处理器、调度策略、负载均衡算法等扩展功能
快速验证文件是否已存在于服务器上的技术
系统未改动之前是通过 tail -f opt.log来实时滚动地查看日志文件
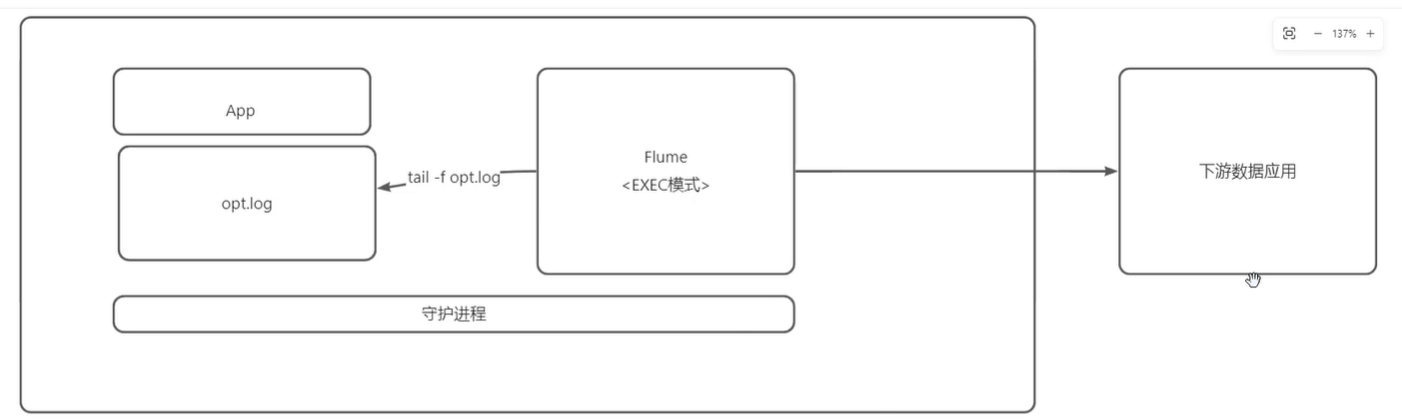
ps:exec模式是指在收集时通过不断执行 tail -f opt.log模式
但系统经过了一个同事的调优后,发现不生效了
之前的日志都是统一写入一个文件里,但想着随着业务的增长,日志文件体量肯定很大,就想着能不能优化成日滚动的模式
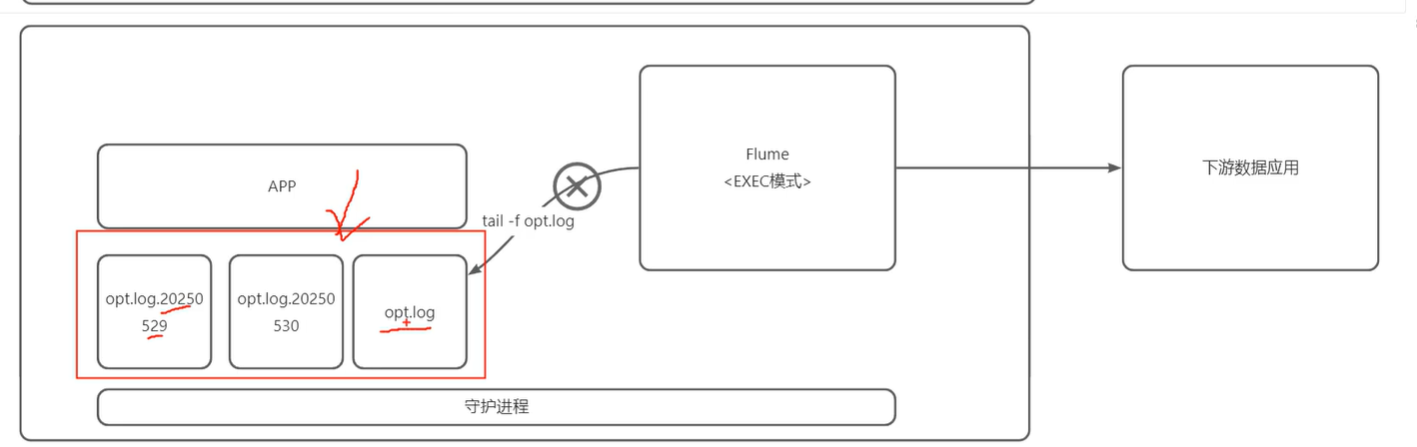
日滚动:


但每天到凌晨时发现就会tail -f opt.log命令会失效
我们是以为只要文件的文件名相同 命令还是可以生效的,没想到tail -f要求的是你的文件描述符相同才会生效

怎么解决
1.使用 tail -F app.log 会检测到文件被替换(即使 inode 改变)并自动重新打开新的 app.log
2.使用Flume taildir 读日志,它会保存文件读出的偏移量
双方都可以主动关闭连接,调用 close()
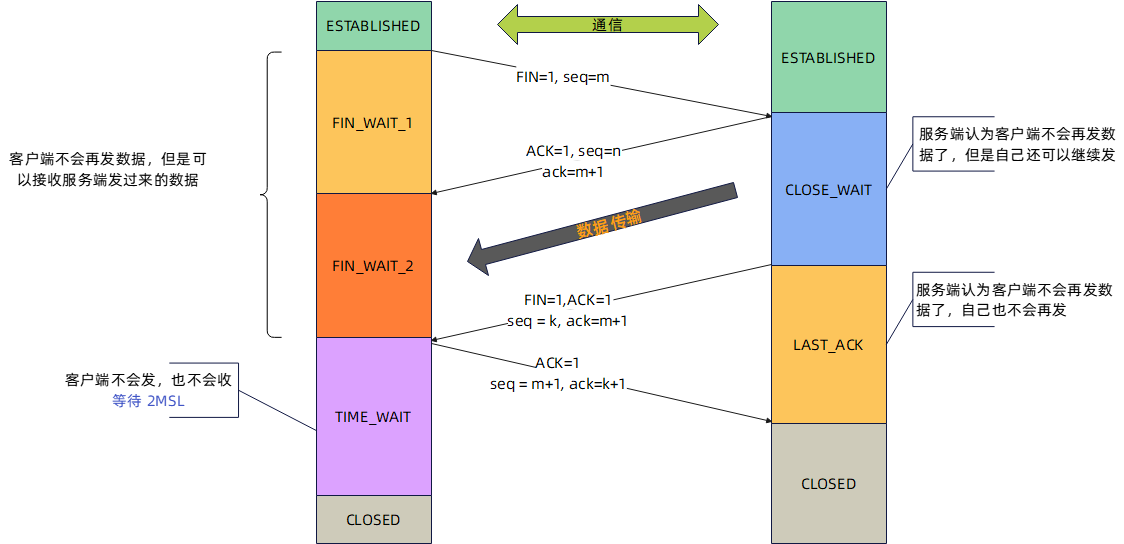
为什么需要四次挥手
服务端发送ACK后,需要等数据全部传输完再发送FIN,所以需要四次挥手的。但是在没有数据发送 且 开启了TCP延迟确认机制下(默认情况下),服务端的ACK和FIN是可以合并的,也就是只需要三次挥手的
TCP延迟确认机制:
为什么要有TIME_WAIT?
主动发起关闭请求的一方,才会有TIME_WAIT状态
需要这个状态的原因:
- 防止历史中的数据,被后面相同四元组的连接误收,这个时间足以让数据在网络中丢失,再出现的数据包一定是新建立连接产生的
- 保证 被动关闭的一方,能被正确地关闭。等待足够的时间以确保最后的ack能让接收方接受到,从而帮助其正常优雅地关闭,即让客户端尽量把数据发完
为什么TIME_WAIT等待的时间是2MSL?
MSL:最大段生存期 ( MSL) 是指 TCP段在互联网络中可以存在的时间。1981 被定义为 2分钟。
最新的内核已经被优化为3.5s
为什么TCP4次挥手时等待为2MSL? - Gypsophila N的回答 - 知乎
https://www.zhihu.com/question/67013338/answer/1032098712
这个我觉得一个主要原因就是要保证此次TCP连接的所有报文都能在网络中消失,也就是避免前后两个使用相
同四元组的前一个TCP连接的报文干扰到后一个连接。
假设主动关闭方为A,被动关闭方为B
A发送ack后,这个ack最坏情况下MSL后到达B,此时B因为没收到ack,会根据ROT机制重传FIN,那么这个
FIN最坏会在1 MSL后消失。因此从A发送ack后,A就需要等待TimeWait 即 2MSL,来保证A发送的最后一个
ack和B发送的最后一个FIN可以在网络中消息
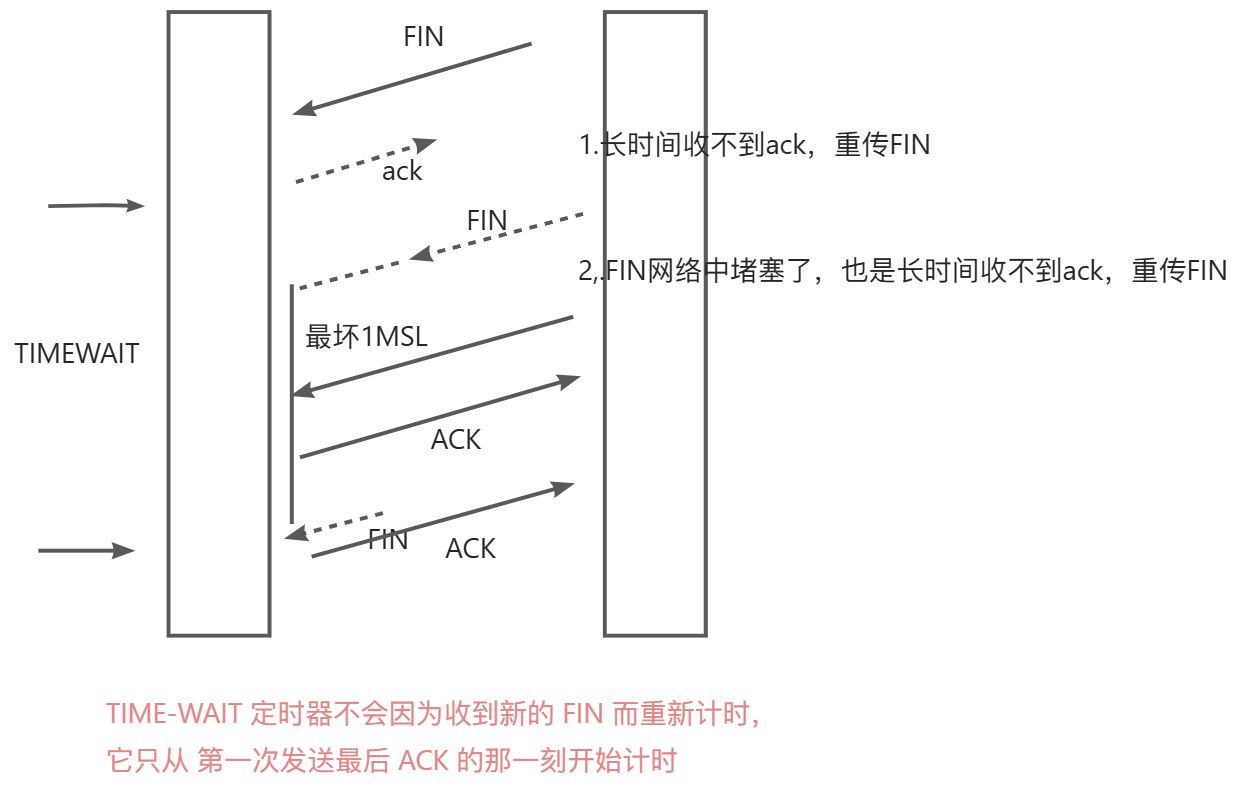
还有一点我看网上说还有就是保证被动关闭方能够接受到自己FIN的ack,我觉得这点是不对的。
假如现在 A 收到 FIN 之后,为了实现目标 1,即保证 B 能够收到自己的 ACK 报文。那么 A 完美的等待时间不是 2MSL,而应该是从 B 发送第一个 FIN 报文开始计时到它最后一次重传 FIN 报文这段时长加上 MSL。但这个计算方式过于保守,只有在所有的 ACK 报文都丢失的情况下才需要这么长的时间;另外,第一个目标虽然重要,但并不十分关键,因为既然已经到了关闭连接的最后一步,说明在这个 TCP 连接上的所有用户数据已经完成可靠传输,所以要不要完美的关闭这个连接其实已经不是那么关键了。因此,(我猜)RFC 标准的制定者才决定以网络丢包不太严重为前提条件,然后根据第二个目标来计算 TIME_WAIT 状态应该持续的时长。
TIME_WAIT过多会怎样?
1.占用系统资源,像fd,cpu,内存等等
2.占用端口资源,端口资源也是有限的,一般可以开启的端口为 32768~61000,当然我们可以设置
TIME_WAIT过多怎么办?
处于TIME-WAIT状态的TCP连接过多主要会导致三个问题。
第一个问题是资源占用过多的问题,包括端口号占用,内存占用等。
第二个问题是性能下降,包括系统负担加重,响应时间变长等。
第三个问题是连接问题,包括创建新连接可能失败,连接传输不稳定等。
而解决思路也有很多。
第一种思路是尽可能使用长连接和连接池,避免连接频繁创建和关闭。
第二种思路是调整 TIME_WAIT 的参数。
第三种思路是优化操作系统,例如说增大端口号范围,增大内存或者优化内存使用,以便可以支持更多的 TCP 连接。
但在实际场景中,我们一般都是利用谁主动关闭谁才有TIME_WAIT状态这个特性来避免,不让服务端主动关闭,而是浏览器或者客户端
服务端大量出现TIME_WAIT?
说明服务端主动断开了连接,只有主动关闭方才存在这个状态
一般有以下情况,属于正常的情况
1.HTTP短连接,即一个HTTP为一个TCP连接,不存在复用的情况
2.HTTP长连接超时
3.HTTP长连接的数量达到上限
双方同时断开连接?
如何判断是主动断开的连接,调用了close()函数
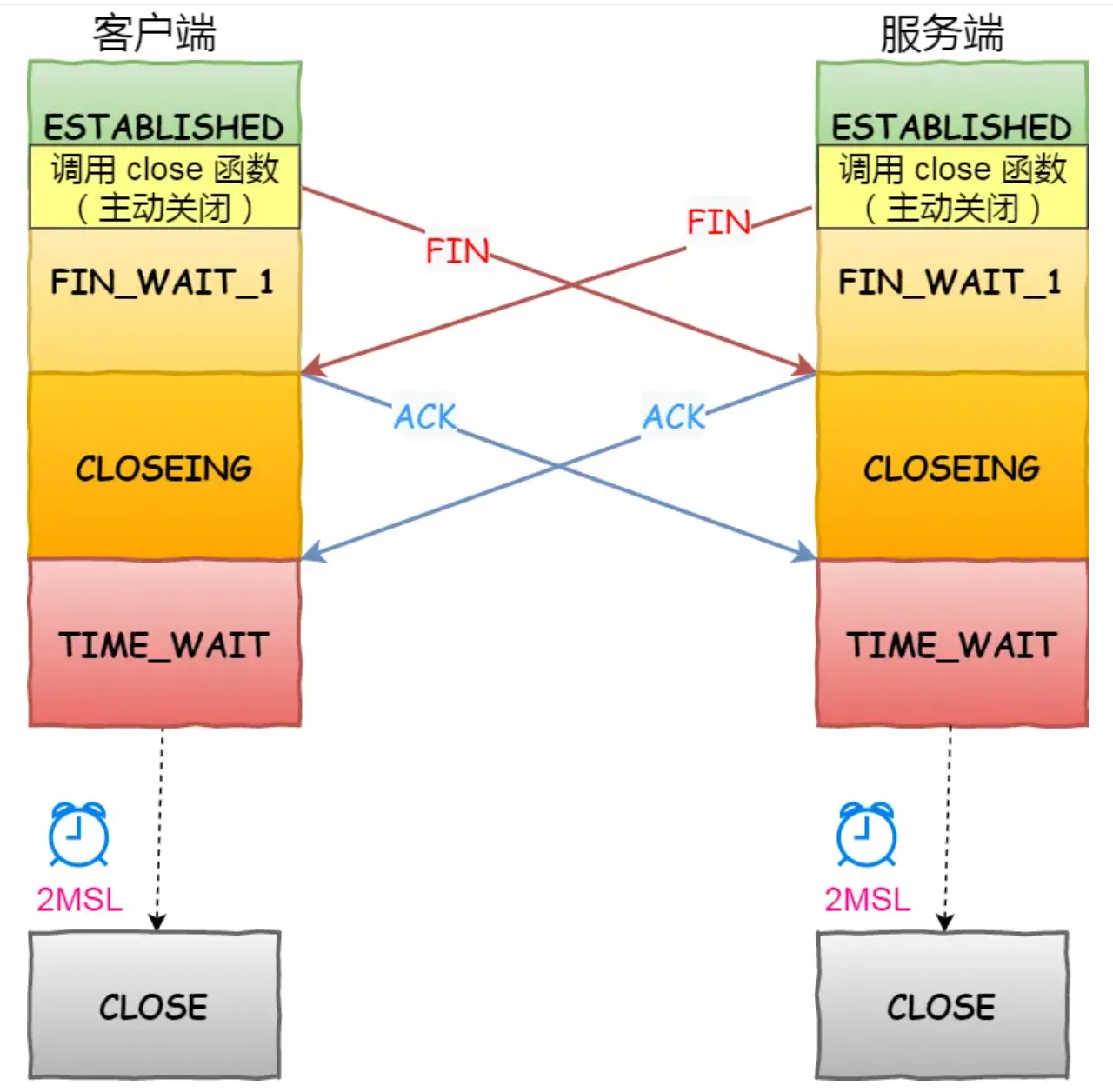
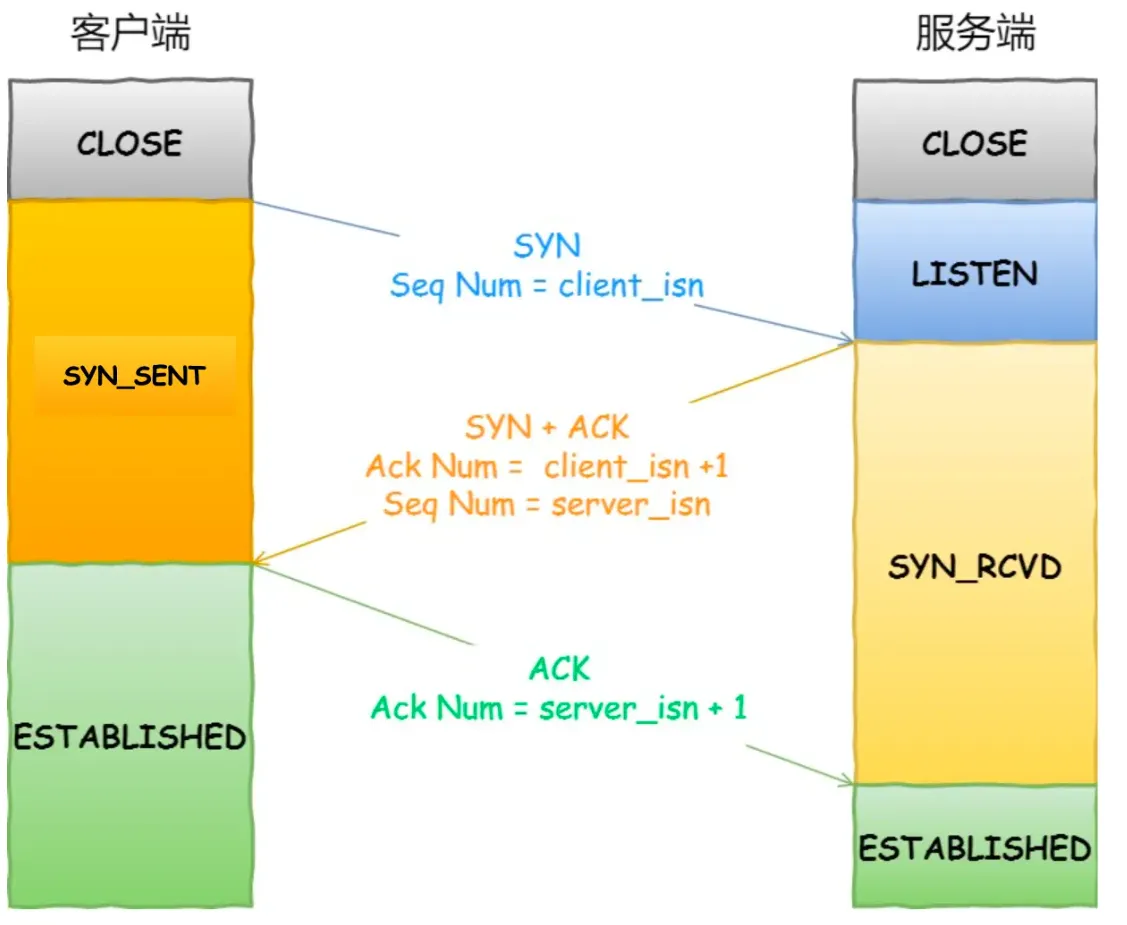
TCP通过三次握手建立连接,随后的数据通信通过该连接进行:
装逼:一个是讨论三次握手机制意味着 TCP 创建连接非常麻烦,所以需要池化技术;另外一个是讨论为啥恰好是三次握手,而不是两次握手,也不是四次握手
TCP三次握手是指建立一个可靠的TCP连接的过程。它的主要目的是让通信双方(客户端和服务器)确认彼此的接收和发送能力,并协商一些关键参数,确保数据传输的可靠性。
最开始,服务端要启动之后,要监听某个端口。
当客户端准备连接服务端的时候,发送 SYN 报文,并且带上自己的初始化序列号(ISN),而后进入 SYN-SENT 状态。这是第一次握手。
服务端收到 SYN 报文之后,会响应一个 SYN-ACK 报文,并且带上自己的初始化序列号(ISN),而后进入 SYN-RECV 状态。这是第二次握手。
当客户端收到 SYN-ACK 报文之后,发送一个 ACK 报文,客户端进入 ESTABLISHED 状态。当服务端收到了 ACK 报文之后,进入了 ESTABLISHED 状态。这是第三次握手。
完成这三次握手之后,客户端和服务端就可以互相发送数据了。
简述
SYN,SYN-ACK,ACK
重点
三次握手的状态变迁
引导
TCP状态;
池化?
从这个过程上也可以看到,三次握手这个过程虽然可靠性很强,但是性能很差。一方面三次握手过程增加了连接建立的延迟,尤其是在网络状况不佳的情况下;另外一方面是每次建立连接都需要消耗系统资源(如文件描述符、内存等)。
所以在当下来说,基本上使用 TCP 的时候都会使用池化技术,规避 TCP 连接频繁创建和销毁的
风险。
为什么是三次握手?
当然,我们也可以从一个更加本质的角度去理解三次握手的过程。对于 TCP 连接来说,初始化的时候有两个关键的点:确认网络是连通,同步初始化序列号,即 ISN。
TCP 是一个全双工通信的协议,这就意味着服务端要确认客户端的 ISN,客户端也要确认服务端的 ISN。因此从设计上来说是四个步骤:客户端发送 SYN 和 ISN,服务端确认,服务端发送 SYN 和 ISN,客户端确认。只不过这逻辑上的第二和第三个步骤,可以合并为一个步骤,也就是服务端在确认的时候,也顺手把自己的 ISN 返回去了。
这是三次握手设计的根源。从这个角度出发,就很容易理解为什么不能是两次握手,因为两次握手只是建立了客户端到服务端的单向通信,而服务端没有收到客户端的 ACK,它并不能确定客户端能否正确处理自己发过去数据,因此服务端到客户端这一个方向上的通信并没有建立。
简述
两次握手,客户端到服务端单向通信;三次握手,客户端到服务端双向通信;
重点
为什么一定是三次握手;
第三次握手时可以发送数据吗?
可以,这个就用到了TCP Fast Open机制,即第三次握手的时候可以将数据和ack一起携带过来
当然,这要客户端和服务端都支持 TFO 机制。
排除这种机制之后,也就是如果客户端发送第三次握手,而是直接发送数据,也就是报文里面不带 ACK 标记位。这种情况下,服务端会丢弃报文,并且返回 RST 报文,关闭连接。
TCP 协议是明确要求一定要完成三次握手才能正常通信的。
简述
ACK带数据,TFO;霸王硬上弓,直接丢弃;
重点
TFO机制;没有完成握手就发送数据,会发生什么;
引导
TFO;
为什么不是四次握手?
因为三次握手已经可以确认双方的发送接收能力正常,双方都知道彼此已经准备好,而且也可以完成对双方初始序号值得确认,也就无需再第四次握手了。
这个问题要从 TCP 的全双工通信角度开始说,全双工通信也就是意味着要做到客户端能把数据发到服务端,服务端也能把数据发到客户端。
因此理论上来说,不考虑什么优化的话,就是四次握手。也就是客户端发到服务端,服务端确认,这是两次。服务端发到客户端,客户端确认,也是两次。
而后就会发现,其中服务端确认和服务端发送到客户端的两次可以合并为一次,节省一次。因此最终的成果就是三次握手就够了。
SYN 洪水攻击
- 建立连接时超时了。Client发出syn后,Server接受到了,发给SYN-ACK后但这时候Client下线了怎么办?
那么这个连接就处于一个中间状态,没成功也没失败。收不到Client的ack一段时间后在Linux下,Server默认会采用一个重试措施,默认重试次数为5次,重试的间隔时间从1s开始每次都翻售,5次的重试时间间隔为1s, 2s, 4s, 8s, 16s,总共31s,而第5次后得等32秒才能停止等待,故总共是63s,这个时候tcp才会断开
- SYN Flood攻击。基于上述情况,就有人利用这种机制,恶意攻击你,发一个syn后,客户端下线,让你的syn连接的队列耗尽(syn队列就是存放那些半连接状态的连接的)。于是,Linux下给了一个叫**tcp_syncookies**的参数来应对这个事——当SYN队列满了后,TCP会通过源地址端口、目标地址端口和时间戳打造出一个特别的Sequence Number发回去(又叫cookie),如果是攻击者则不会有响应,如果是正常连接,则会把这个 SYN Cookie发回来,然后**服务端可以通过cookie建连接(即使你不在SYN队列中)**。
- 请注意,请先千万别用tcp_syncookies来处理正常的大负载的连接的情况。因为,synccookies是**妥协版的TCP协议**,并不严谨。对于正常的请求,你应该调整三个TCP参数可供你选择,第一个是:**tcp_synack_retries** 可以用他来**减少重试次数**;第二个是:**tcp_max_syn_backlog**,可以**增大SYN连接数**;第三个是:**tcp_abort_on_overflow** **处理不过来干脆就直接拒绝连接了**。
SYN 洪泛攻击是一种 DDoS 攻击,攻击者发送大量的 SYN 包,但是并不响应服务端返回来的 SYN-
ACK包
这样造成的后果是服务端需要消耗资源维护这些半开连接,并且因为没有收到客户端的 ACK 包,所以会不断重试,进一步加重了资源消耗。
SYN 洪泛攻击抵御起来,有多种手段。
最重要的手段就是 SYN Cookie 技术,也就是服务端在收到SYN包时,不立即分配资源,而是生成一个“cookie”作为初始序列号返回给客户端。客户端在回复ACK包时,必须包含这个“cookie”,服务器验证通过后才分配资源。
还有一些治标不治本的手段,例如说增大 TCP 连接队列大小、调整 TCP/IP 协议栈参数、延缓 TCB 分配等。
当然,我个人推荐的是不要自己去搞 DDoS 防范,直接购买成熟的服务性价比最高。
简述
SYN Cookie 比较好,其余治标不治本
引导
SYN Cookie技术
最后一次握手服务端一直收不到来自客户端的ACK,会怎么样
一句话就能说清楚,服务端会重试,直到重试超出最大次数,给客户端发RST报文后,则会关闭连接。
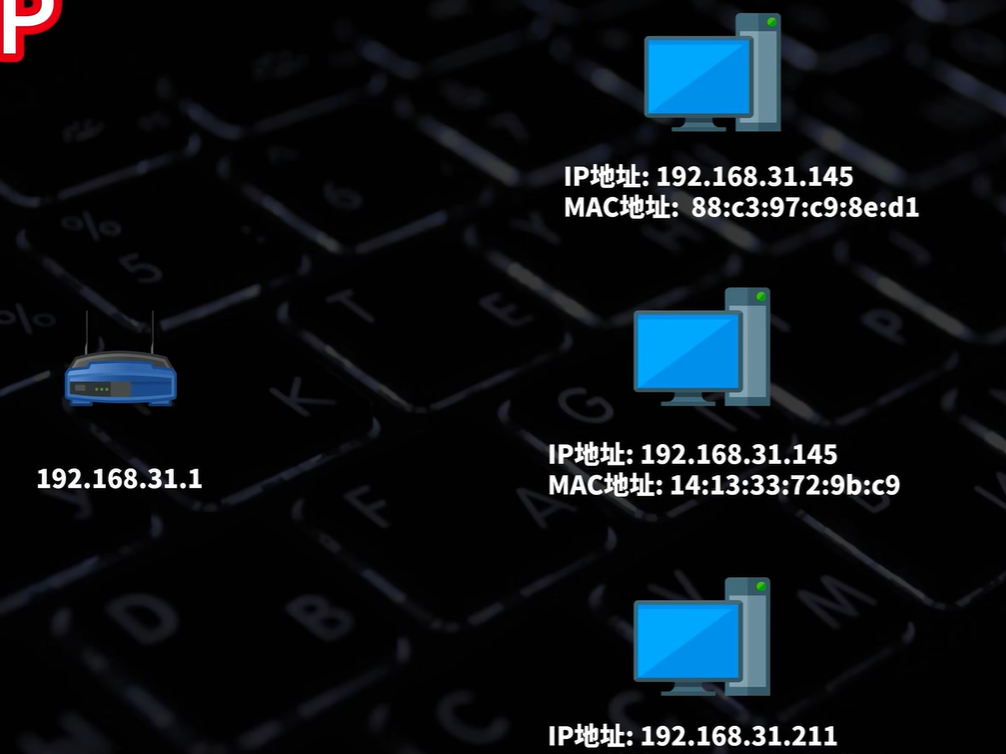
局域网中设备之间交换IP和MAC地址关系的协议
局域网的某个设备想知道某个IP地址对应的设备是谁,它就会在局域网里广播一个ARP请求,询问它是谁。然
后目标设备就会把自身的IP地址和MAC地址返回回去,原设备接受到后可以把地址存储到ARP缓存表里,方
便后续使用