Redis集群由多个节点组成,每个节点都是一个主从集群。整体结构如下:

在这种结构之下,现在就会有一个问题,当我存放一个键值对的时候,放哪个节点上?
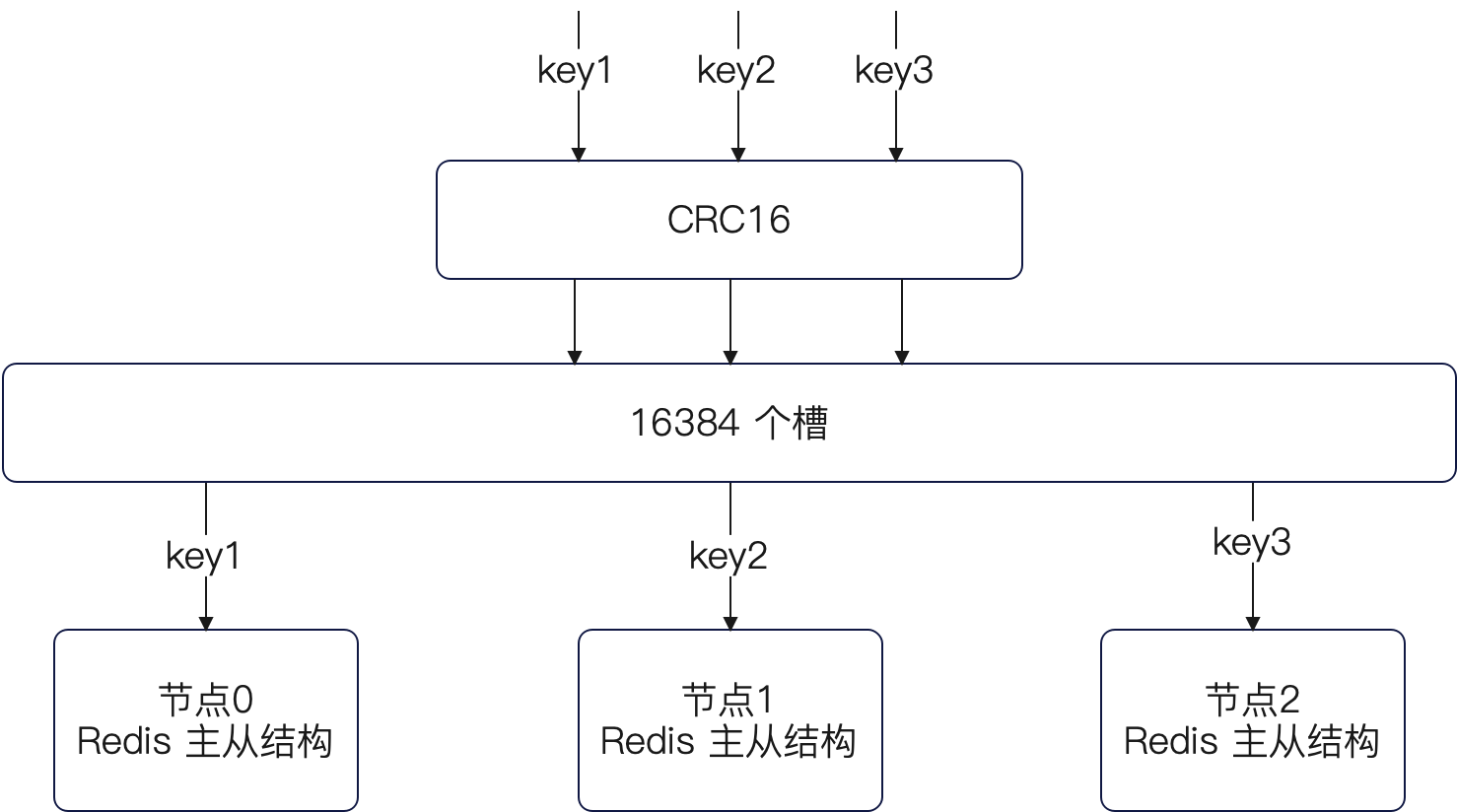
对此 Redis Cluster 用的是槽映射的解决方案。Redis Cluster 将所有的key 按照 CRC16 算法映射到16384个槽,这些槽会被分配到这些节点上。大多数情况下槽是均匀分配的,但是小部分情况并不会均匀分配。
整个结构如下图:
所以 Redis 的高可用就源自两方面:
- 如果节点内的主节点崩溃了,那么从节点经过主从选举就可以顶上;
- 如果某个节点全崩溃了,那么还有别的节点可以用。虽然会损失数据,但是不至于完全不可用;
对于sentinel和cluster应该选哪种,单机无瓶颈就选sentinel,单机有瓶颈就选cluster
Redis Cluster 是一个对等结构和主从结构的混合架构。Redis Cluster 由多个节点组成,这些节点之间地位是平等的,也就是说它们构成了一个对等结构。
但是从细节上来说,每一个节点都是一个主从集群,也就是说每一个节点都是类似于 Redis Sentinel 模式,并借此来保证高可用。
Redis Cluster 借鉴一致性哈希的思想,利用 CRC16 将 key 分散到 16384 个槽(哈希槽就相当于一致性哈希中的虚拟节点)上面,而后再次将这些槽分配给不同的节点。可以平均分,也可以不是平均分。
通过这种混合模式,Redis 能有效应对各种问题。
首先是从对等结构上来说,就算是某个节点彻底不可用,也不会影响到别的节点,整个集群还是能够提供有损服务的。
而从主从结构上来说,通过数据同步和主从选举,这样即便主节点崩溃了, 也能选举出来一个新的从节点顶上。
Redis Cluster 能够撑住极高的并发,并且能够提供极高的可用性,所以已经成了当下大规模分布式系统里面的核心组件。
二、pipeline 是什么
pipeline 是客户端的一种 批量发送命令 的方式:
它允许客户端一次性把多个命令发到 Redis 服务器,然后 Redis 一次性返回结果。
减少了网络往返(RTT),因此性能更高。
✅ 在单机 Redis 下,pipeline 可以极大提高性能。
❌ 但在 Redis Cluster 下,有一个问题:
但是 Redis Cluster 并不是毫无缺点,最大的问题就是难以处理跨槽的问题。
这最典型的例子就是 pipeline。例如说在 pipeline 里面要处理分散在不同槽上的多个 key,那么pipeline 就会返回错误,这需要客户端进行处理。而有些语言的 Redis 客户端其实没有那么智能。
从我个人使用经验上来说,在使用 Redis Cluster 的时候,就要避免跨槽的问题。即便使用 Redis pipeline,如果跨槽其实意义就不大了,毕竟我用 pipeline 就是为了高性能,即便我的客户端能帮我处理跨槽的问题,但是性能还是损耗极大。
所以我即便要操作跨槽的 key,也更加倾向于自己将 key 分组,落到同一个节点上的 key 作为一组,而后分批操作。这样分组之后,用 pipeline 也就没有跨槽的问题了。
Redis Cluster 这种对等集群和主从集群的混合模式,在别的中间件里面也能看到类似的设计,甚至于可以说现代的大规模分布式软件的高可用都是通过这种设计来保证的。
举个例子来说,Kafka 的一个 Topic 有多个分区,这些分区之间地位是平等的,所以可以看做是对等结构。而每一个分区本身也是一个主从结构,也有数据复制和主从选举。所以Kafka 就算一个分区出问题,或者逻辑分区的主分区出现问题,依旧能够正常对外提供服务。
再举个例子来说,MySQL 的分库分表也可以看做是这种形态。一个逻辑表被分库分表之后,每一个物理表地位都是平等的,也就是可以看做是对等结构。而每一个物理表都是存储在 MySQL 主从集群上的,那么也就是说物理表本身也有主表和从表。通过这种混合模式可以保证极高的可用性。