LWP
轻量级进程,即用户线程的运行载体,等价于内核线程
轻量级进程,即用户线程的运行载体,等价于内核线程
主流虚拟机如hotspot线程模型基本都是1:1,即一个用户线程对应着一个系统线程
一个 Java 线程是直接映射为一个操作系统原生线程的,中间没有额外的间接结构。HotSpot 虚拟机也不干涉线程的调度,这事全权交给底下的操作系统去做。
顶多就是设置一个线程优先级,操作系统来调度的时候给个建议。
但是何时挂起、唤醒、分配时间片、让那个处理器核心去执行等等这些关于线程生命周期、执行的东西都是操作系统干的。
ps:用户线程是指逻辑线程
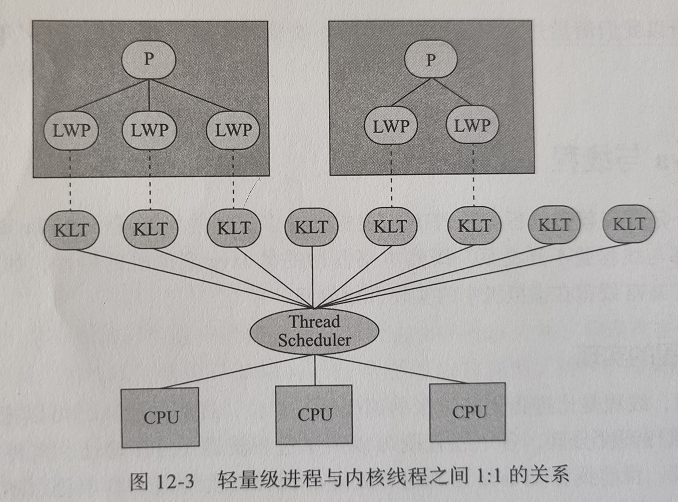

程序一般来说不会直接使用内核线程,而是使用内核线程的一种高级接口,即轻量级进程(LWP),轻
量级进程就是我们通常意义上说的线程。
为什么不直接使用内核线程:https://chatgpt.com/s/t_688a3269bab881919cc8b77012464e77
正因为有了内核线程的支持,每个轻量级进程成了独立的调度单元,即使某个轻量级进程阻塞了,也不会
影响到其他轻量级进程的
但他也有局限性,即他属于内核空间的东西,用户线程的创建,切换,销毁都需要用户态和内核态来回切
换,挺耗时的。其次就是那个内核空间有限,轻量级进程要消耗一定的内核资源(如内核线程的栈空 间),因此一个系统支持轻量级进程的数量是有限的
绑定线程是操作系统层面干的,即使Java能干,那也只是套层皮而已
使用某位大佬开发的一个库,本质是封装了Linux的taskset指令来要求os为我们的用户线程判定特定cpu
1 | <dependency> |
jna:JNA 是一个让你可以在 Java 中直接调用 C 系统函数 / 本地库的工具,不用写 JNI,使用简单灵活,
是 Java 调用底层的一把利器。
好处:
减少上下文切换和缓存失效率
谁在使用?
可用于netty

问题:线上由于两台服务器的问题造成一机关读条(进度条)功能客户端和服务端对不齐
原因:test时把Server时间调到了未来,然后调了回来
1 |
channel,eventLoopGroup,ByteBuf,Handler,pipline
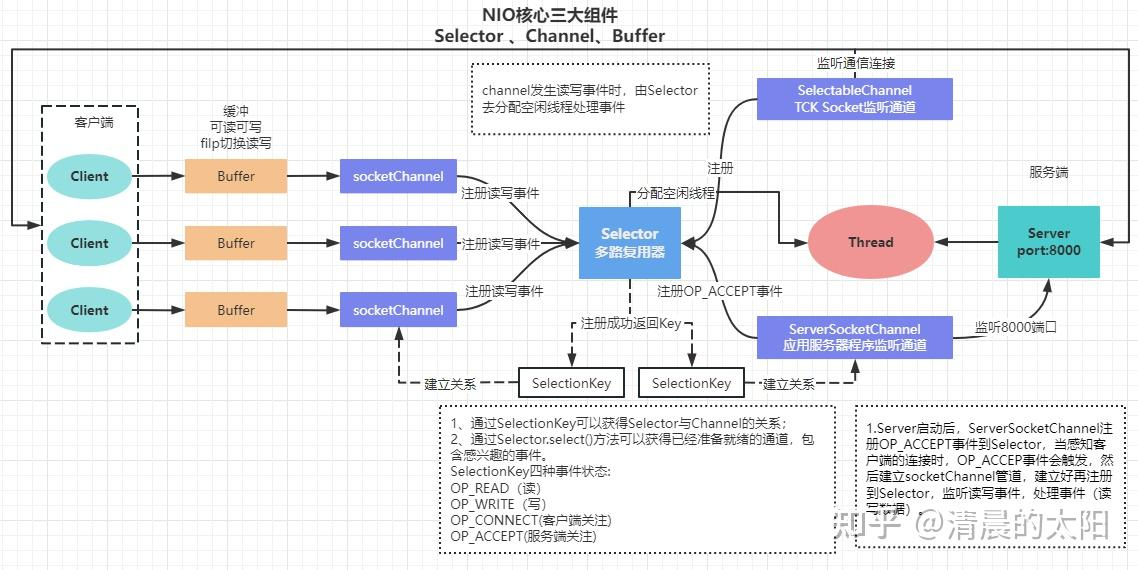
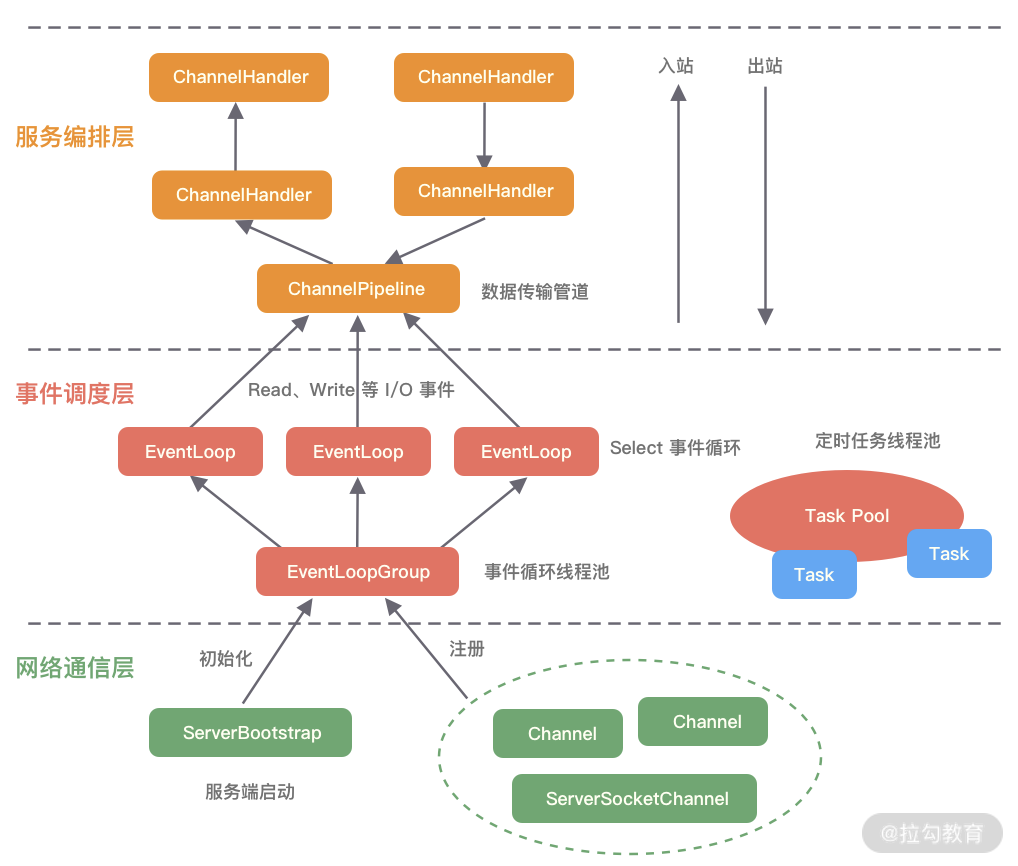
事件循环对象,本质就是单线程执行器
事件循环组(EventLoopGroup),channel一般会调用EventLoopGroup中的register来绑定其中一个channel,后面channel上的io事件都由此EventloopGroup来负责,也保证了io处理时的线程安全
NioEventLoop 底层基于NIO
DefaultEventLoop
作用
- <font style="color:rgb(31, 35, 40);">close() 可以用来关闭 channel</font>
- <font style="color:rgb(31, 35, 40);">closeFuture() 用来处理 channel 的关闭</font>
* <font style="color:rgb(31, 35, 40);">sync 方法作用是同步等待 channel 关闭</font>
* <font style="color:rgb(31, 35, 40);">而 addListener 方法是异步等待 channel 关闭</font>
- <font style="color:rgb(31, 35, 40);">pipeline() 方法添加处理器</font>
- <font style="color:rgb(31, 35, 40);">write() 方法将数据写入</font>
- <font style="color:rgb(31, 35, 40);">writeAndFlush() 方法将数据写入并刷出</font>
注意 connect,bind 方法是异步的,意味着不等连接建立,方法执行就返回了。因此
channelFuture 对象中不能【立刻】获得到正确的 Channel 对象
两种方法:线程sync()阻塞等待建立好,addListener() 添加回调方法
多个Handler组成一个pipeline
是对字节数据的封装
创建
1 | ByteBuf buffer = ByteBufAllocator.DEFAULT.buffer(10);//默认使用 池化基于直接内存的 ByteBuf |
堆内存和直接内存
堆内存:多一次拷贝,需要从os 本地内存拷贝到Java的堆内存
磁盘-》os
os-》Java heap内存
数据需要 两次拷贝,效率较低
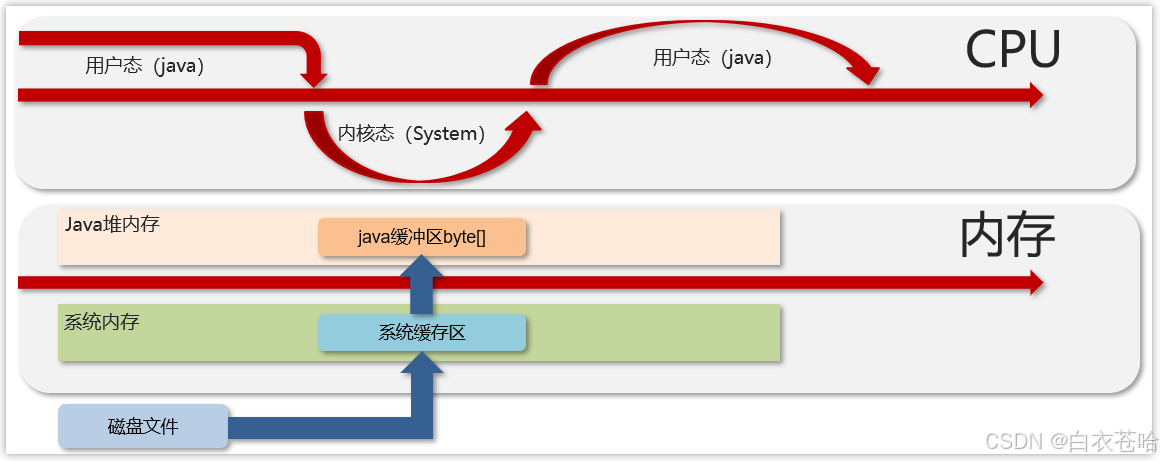
直接内存:零拷贝技术,只需要一次拷贝
池化的最大意义在于可以重用 ByteBuf,优点有

writeByte,writeInt….
扩容规则
未超过512,下一个则是超过它的第一个16的整数倍
如果超过521,下一个则是超过它的第一个2的n次方数
readByte()
markReaderIndex() 标志
resetReaderIndex() 重置
读写数据的双向通道
通过引入一个selector实现一个线程同时监控多个channel
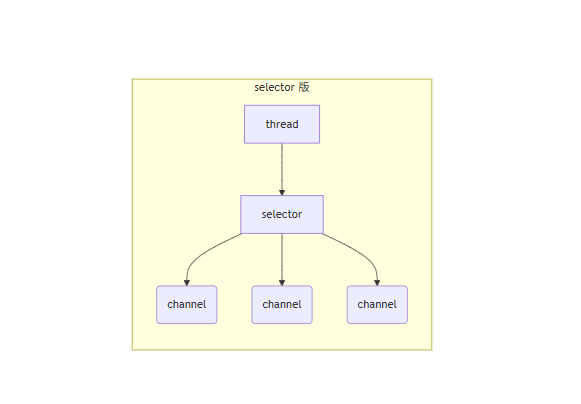
适合连接数特别多,但流量低的场景
使用
往buffer写入数据,channel.read()
从buffer读取数据,buffer.get()
切换写读模式,filp
清空
结构
ByteBuffer 有以下重要属性
* <font style="color:rgb(31, 35, 40);">capacity</font>
* <font style="color:rgb(31, 35, 40);">position</font>
* <font style="color:rgb(31, 35, 40);">limit

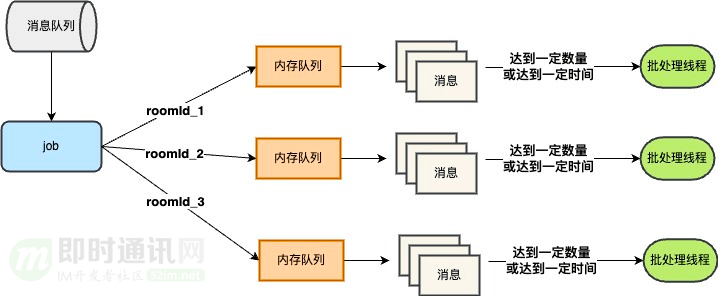 根据消息数量或者时间
根据消息数量或者时间