为什么用Kafka (使用消息队列的好处)?
异步解耦,削峰
还有就是风险转移
异步解耦,削峰
还有就是风险转移
send(msg,callback)
再callback进行处理失败的消息的持久化,然后开定时任务重试
保证msg到达 broker
本质其实就是记了再发,先记日志再发送
unclean.leader.election.enable = false,保证所有副本同步。
同时broker开启 同步刷盘,直接写入磁盘,而不是写入 page cache
开启手动ACK,拉取到本地的消息成功消费后,再提交ACK
设置 enable.auto.commit 为 false
kafka broker端,消息被消费后,不会立马被删除,而是定时删除,所以要保证Consumer消费成功手
动ACK
Kafka 的事务机制,就是让 Producer 往 多个分区 / 多个 Topic 写消息时,看起来像一个“数据库事务”:
这个事务是对外表现的事务
为了是实现跨会话跨partition的事务,这时候需要引入一个事务协调者,将PID(producer ID)与Transition关联起来。这样重启的时候,就不会重新分配新的PID,而是通过正在进行的TransitionId 获取原来的 PID。
还有就是,事务协调者会将事务状态写入一个 topic里,这样的话即使整个服务重启,事务的状态也会得到保存,从而得到延续
整个流程
1 | producer.beginTransaction(); |
这时候会先开启事务
如果producer全部写入,事务协调者就会往事务topic里写入一个maker消息
如果producer写一半宕机了,因为我们是会设置事务超时时间,且broker和producer之间会有心跳,如果
broker收不到producer的心跳包了,那么就会写入一个abort消息
Consumer的事务就比较弱, 无法保证commit的消息被准确地消费
producer的幂等性是指 消息发送到broker,只会在broker被持久化一次,不丢不重
kafka原生机制只能保证在同一个会话的同一个topic下的同一个partition下保证不重
PS:同一个会话是指
Producer 启动 → 和 Broker 建立连接 → 发送消息 → 关闭(或挂掉)。
如果这时候宕机后重启,是否无法保证新消息与旧消息的唯一性的
原理
:::color4
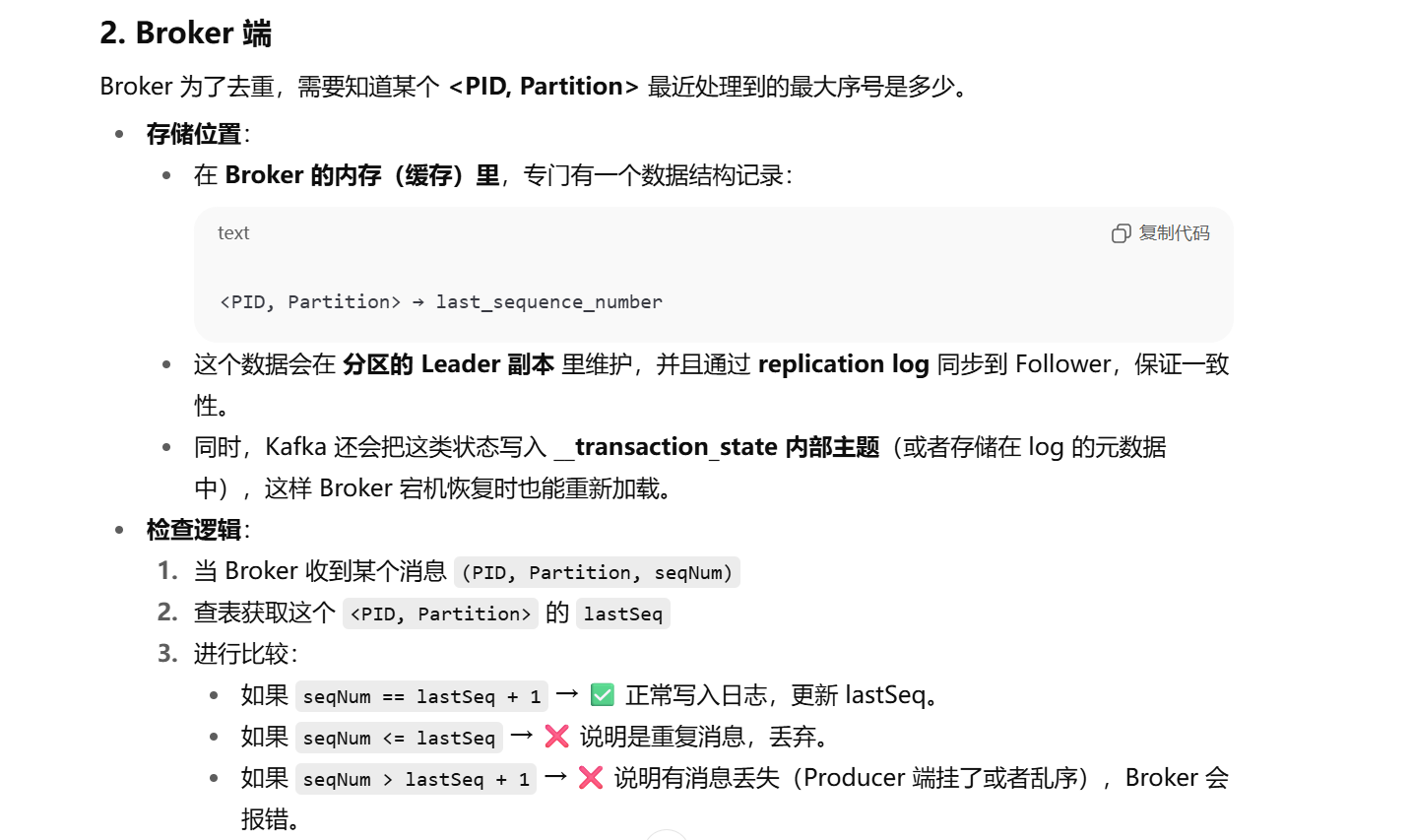
producer会在内存维护一个seqNum,broker端会针对一个producor维护一个 lastSeq
如果msg > seqNumseq,则判断不重
:::


agent:代理,指代表他人行事的人。前两年,AI工具的功能还局限于问答形式:我抛出一个问题,AI告诉我怎么做,我自己去做。 如今,AI工具的功能已经进化成为:我抛出一个问题,并提出要求,AI代替我去做。 这就切合了agent(代理)这个单词的含义,所以此类 能够代替用户完成任务的工具 就叫做AI agent。 由于这种工具比起早期开发的产品更加智能,于是agent又有了一种称呼:智能体

System prompt 系统提醒词,比如 假设你是我的女朋友
user prompt 即 query
是为了解决当上下文太长时,

使用工具时与ai大模型通信的协议
一般是一个json数组

与agent tools 通信的协议
** 同一个时刻**一个 partition 只能分配给一个 consumer ,但consumer可以同时负责多个partition。我们在实
际应用时,应该做到一个consumer尽量一个partition
项目中给kafka的一个topic下划分了四个partition,但实际压测的时候发现数据倾斜严重,有时候数据全在一
个partition上。解决方案即send时 要指定 key,kafka会根据key + 某种算法如hash,去决定消息落在哪个
partition上
PS: 不指定 key,应该是对应的 hash 值,取模到对应的分区上。
在使用spring-integration-kafka做消费者的时候,发现CPU和内存占用量占用非常的大,后来又发现不管生产者发送了多少数据,Kafka的Topic中一直没有数据,这时候才知道spring-integration-kafka会将Topic中的数据全拉到本地,缓存起来,等待后续的处理。
解决方法:
[xml]
1 | <int:channel id="inputFromKafka"> |
kafka客户端在消费时会先拉一批数据到本地来,然后等这批数据消费完成后,会提交offset,然后partition
会被分配给别的从consumer。当时的情况是consumer消费能力不行,无法在规定时间内消费完成,自动提
交了offset,导致这批数据继续被别的消费者消费,从而导致重复消费
解决方案:
1.自动改手动
2.调参
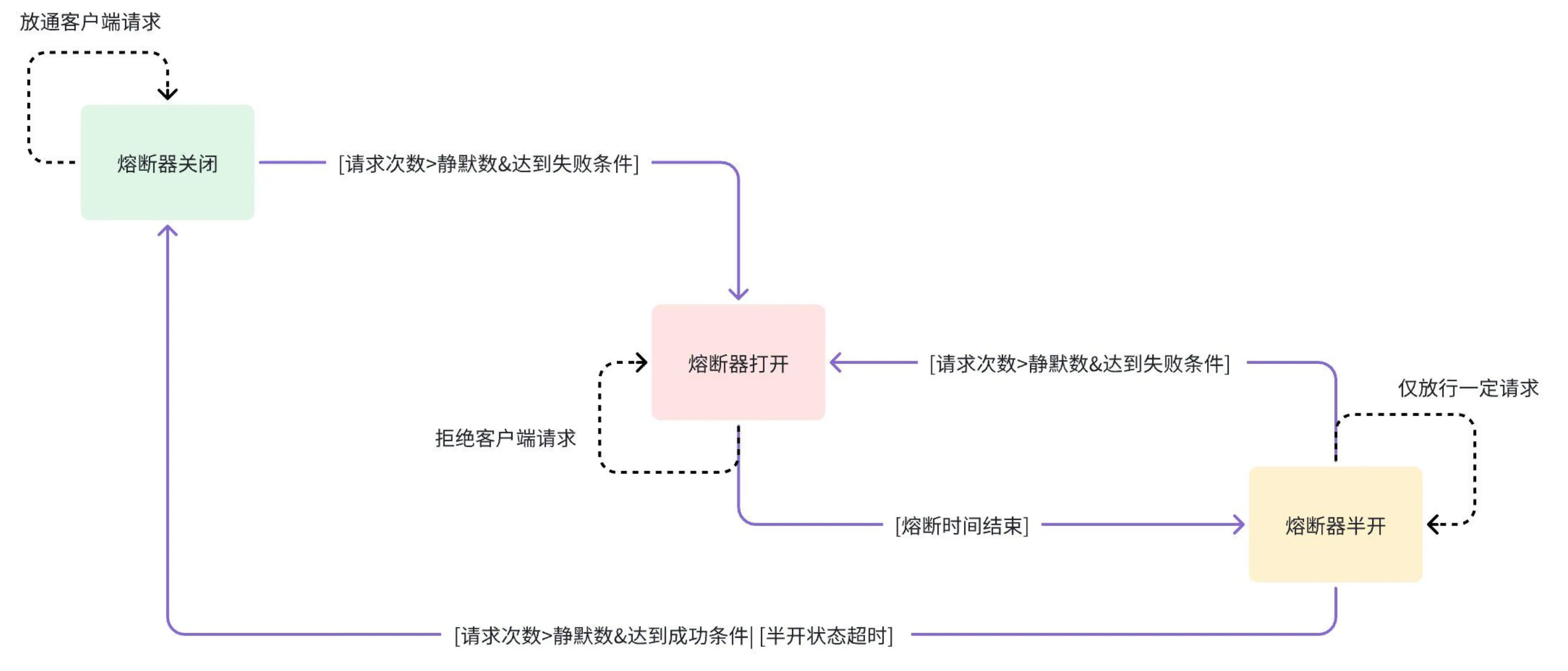
熔断功能,
三个状态,关闭 -> 开 -> 半开
a. 关闭状态:允许所有请求通过。
b. 打开状态:拒绝所有请求,直到熔断时间到期。
c. 半开状态:允许一定量的请求通过,用于评估上游服务是否恢复。
状态切换流程
错误率是基于 滑动窗口进行统计的
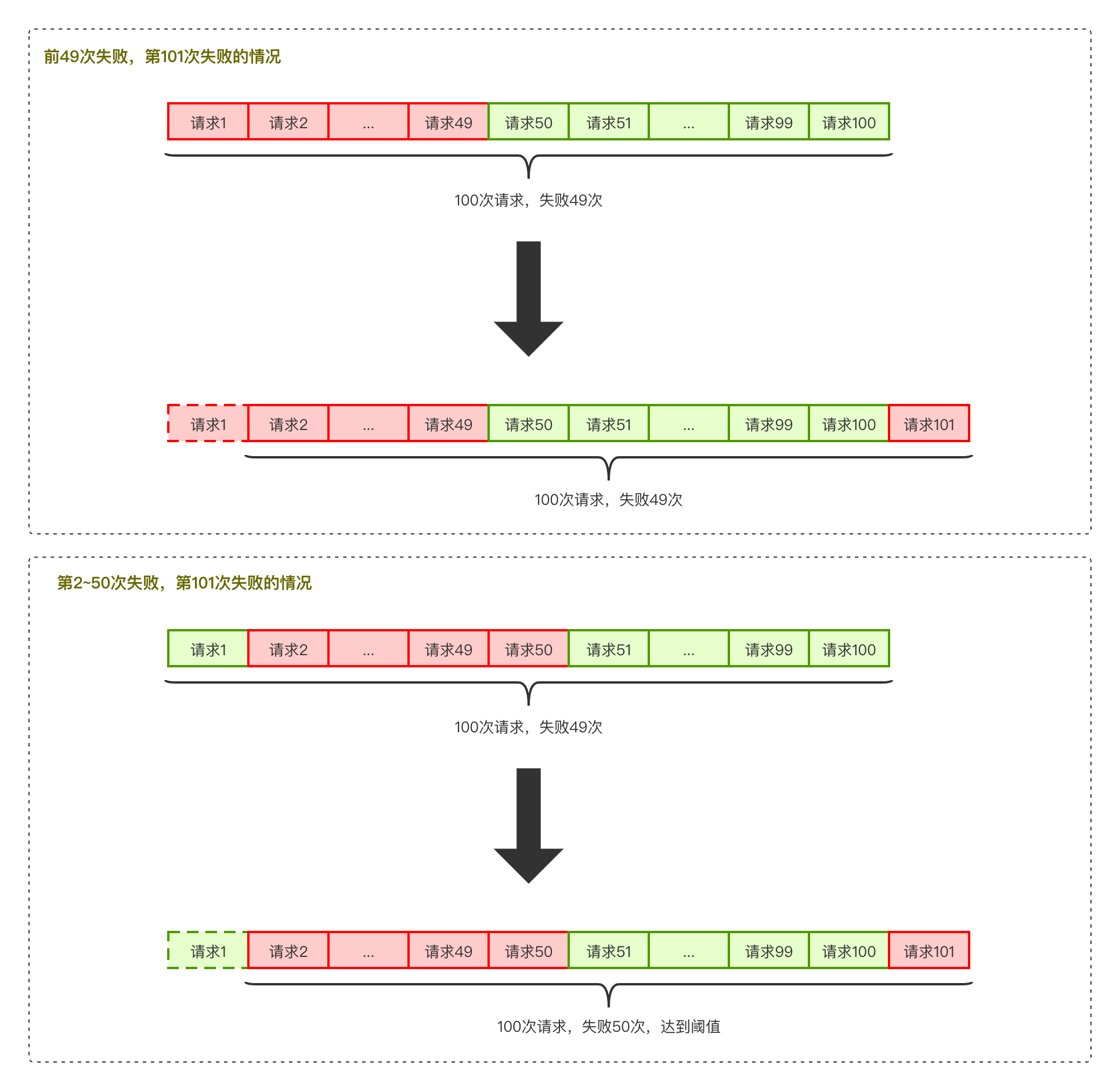
保护系统不会在过载的情况下出问题
限流的目的是通过对并发访问进行限速,相关的策略一般是,一旦达到限制的速率,那么就会触发相应
的限流行为
限流之后触发的行为有:
1.拒绝
2.降级
3.特权处理
4.延迟处理
5.弹性伸缩,这里如果流量过大,服务抗不住了,这时候就需要去加机器,需要一个自动化的发布、部署和
服务注册的运维系统
最简单粗暴的
但这种方式process得用 pull的方式,不然队列过长,没满,processor就先挂掉了
queue的配置是一个学问来着
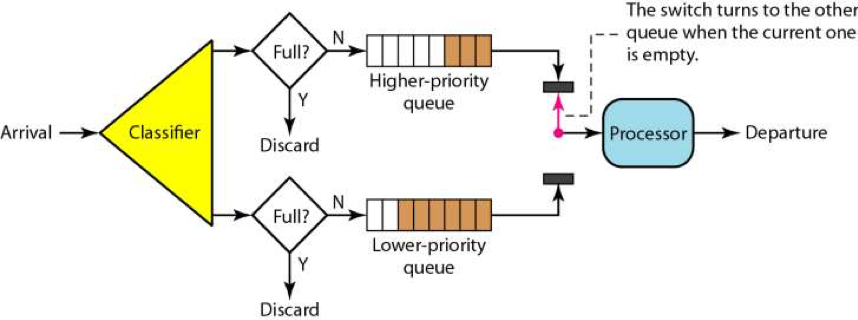
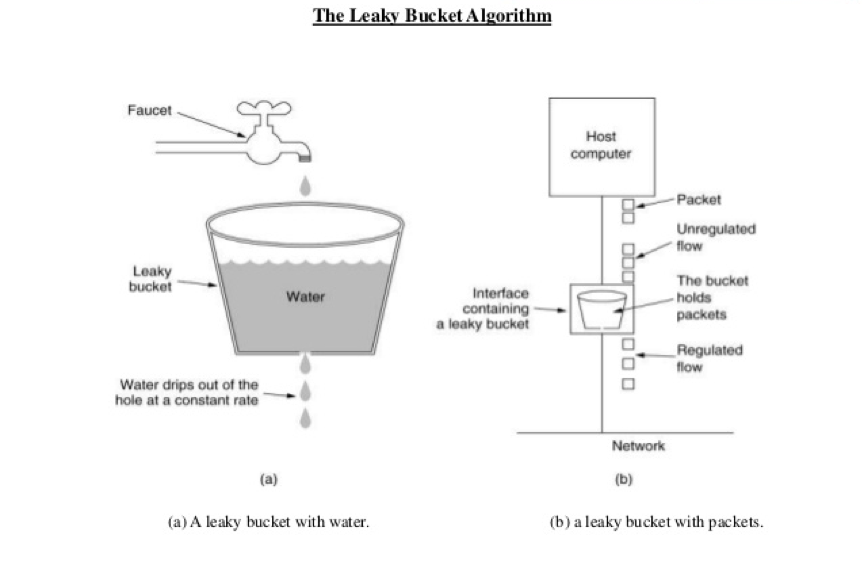
水溢出了就触发限流,这种算法下 处理请求是非常平滑的
实现一般都是通过一个队列来实现,请求多了,队列开始积压请求,超过长度就拒绝请求。
像tcp的流量控制就是这么来的,当请求过多时,会有一个sync backlog队列来缓冲请求,滑动
窗口其实也是
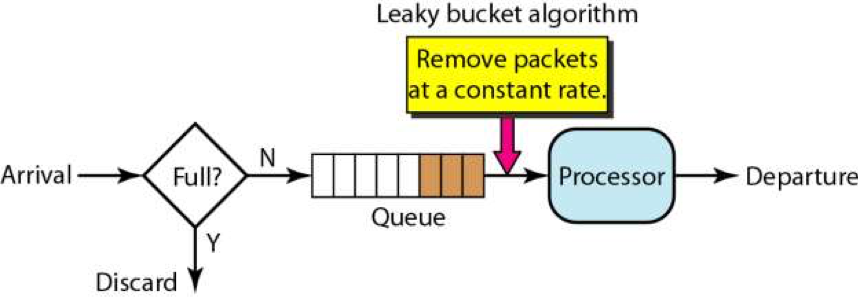
代码:
1 |
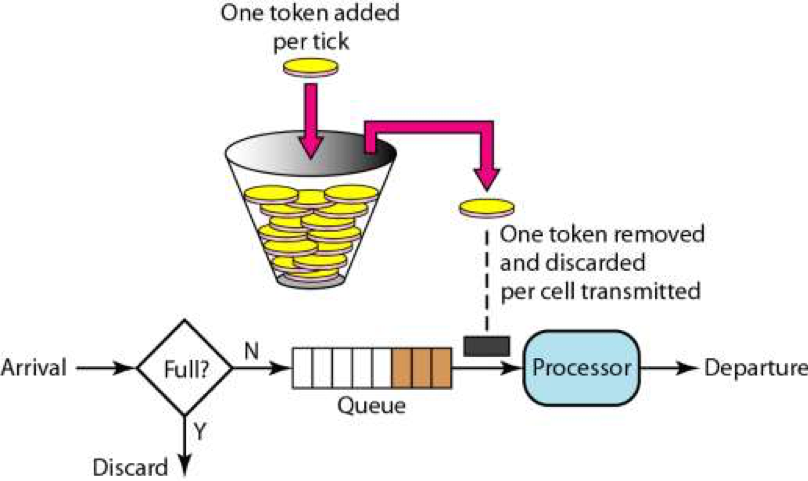
这个算法相当于有个中间人,我们请求要过得去,得去这个中间人拿Token。然后会在一个桶内按照一定的
速率放入一些 token。这种设计可以在流量少时攒钱,流量大时快速处理
如果 Processor 是瓶颈(慢的业务逻辑处理器),算法对总吞吐量影响不大,因为 Processor 才是限
制。
如果 Processor 很快(像 Nginx),算法就决定了请求转发节奏:漏斗稳、令牌桶能爆发。
代码:
1 |
以上算法有个不好的点,就是得去设置一个上限值,这个一般都是我们通过压测得到
虽然我们网关可以做到接口级别的限流,但为每一个api去配置,管理起来其实是很麻烦的
而且,现在的服务都是能自动化伸缩的,不同大小的集群的性能也不一样,所以,在自动化伸缩的情况下,我们要动态地调整限流的阈值,这点太难做到了。
那有没有一种能自动根据系统情况进行限流的算法呢
:::color4
这种方式,不再设定一个特定的流控值,而是能够动态地感知系统的压力来自动化地限流
这方面设计的典范是 TCP 协议的拥塞控制的算法。
它的是通过RTT 来探测网络的延时和性能,从而确定滑动窗口的大小,我们完全可以参考它的设计
结合计网中学到tcp的一些知识,当时一开始想到就是
:::
基于错误率,且采样基数要大
限流目的:
向用户承弱SLA,高并发下保证可用性
保护服务不崩
在多租户的模式下,保证重要的租户仍然可用
节约成本,我们不会为了一个不常见的尖峰来把我们的系统扩容到最大的尺寸

网关TODO:
0.手动开关
1.head上加上标识,让后端知道发生了限流,后端可以根据这个标识决定是否做降级
2.对于监控,监控应该立马感知到,运维能持续跟进
3.网关性能必须好
第一阶段:
只是单机,如果后端网关节点是动态变化的,就不符合需求
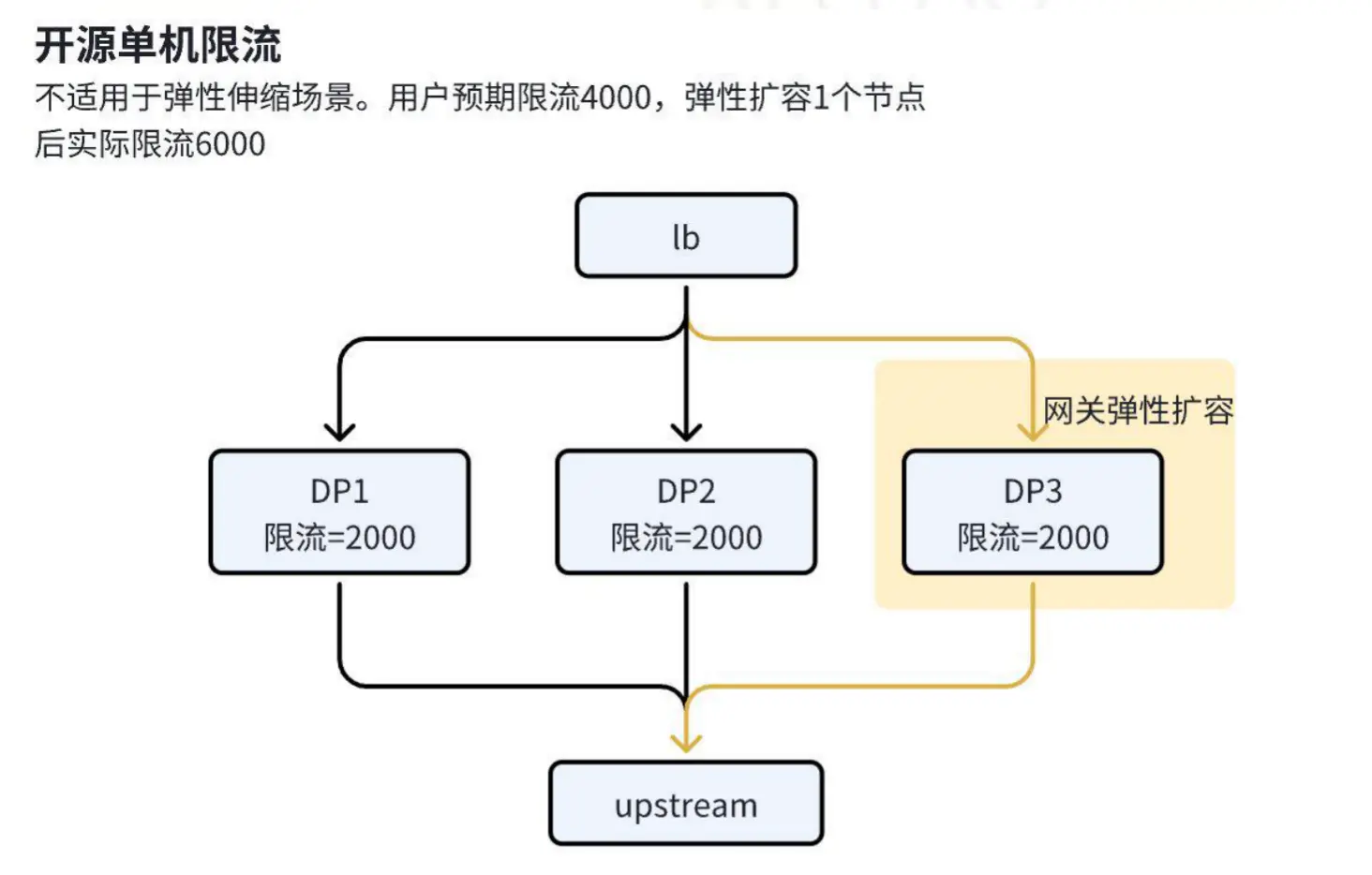
第二阶段
我们可以引入一个第三方比如 配置中心ETCD,NACOS,来管理我们的限流总量
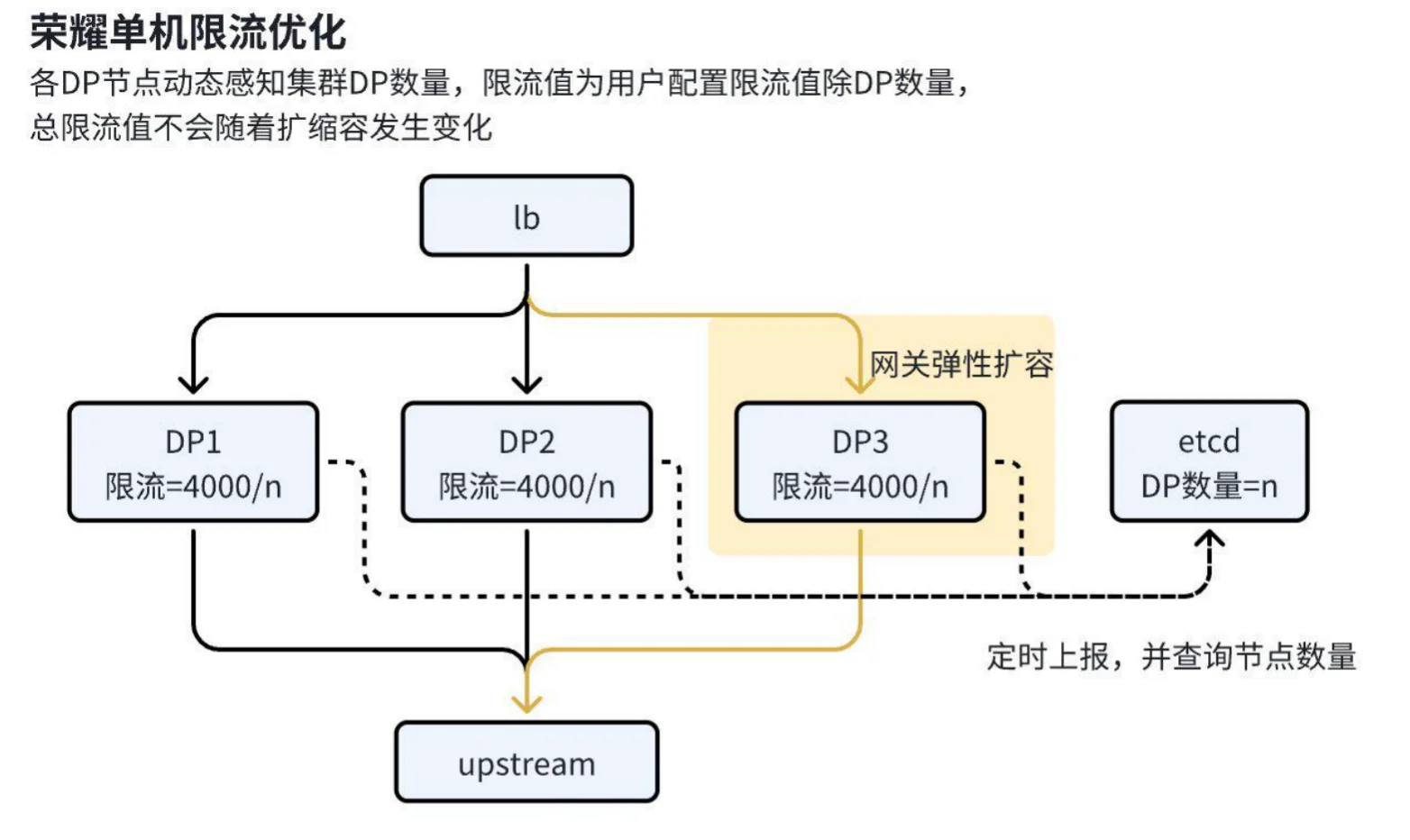
性能优化:
第三阶段
APISIX 在荣耀海量业务下的网关实践 | Apache APISIX® – Cloud-Native API Gateway and AI Gateway
在应用开源分布式限流方案时,我们遇到了以下关键问题:
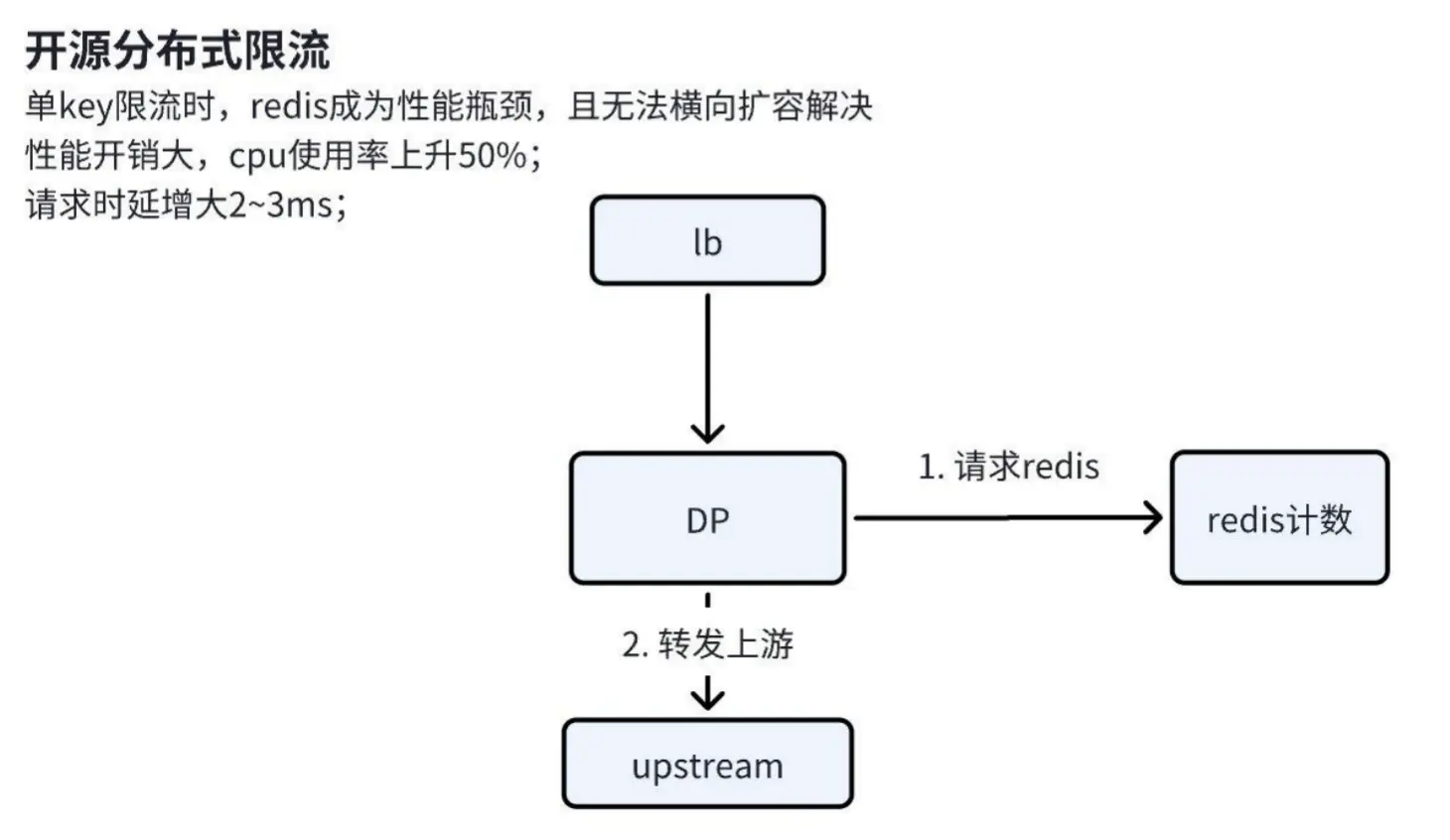
Click to Preview
优化方案
为解决上述问题,我们设计了以下优化方案:
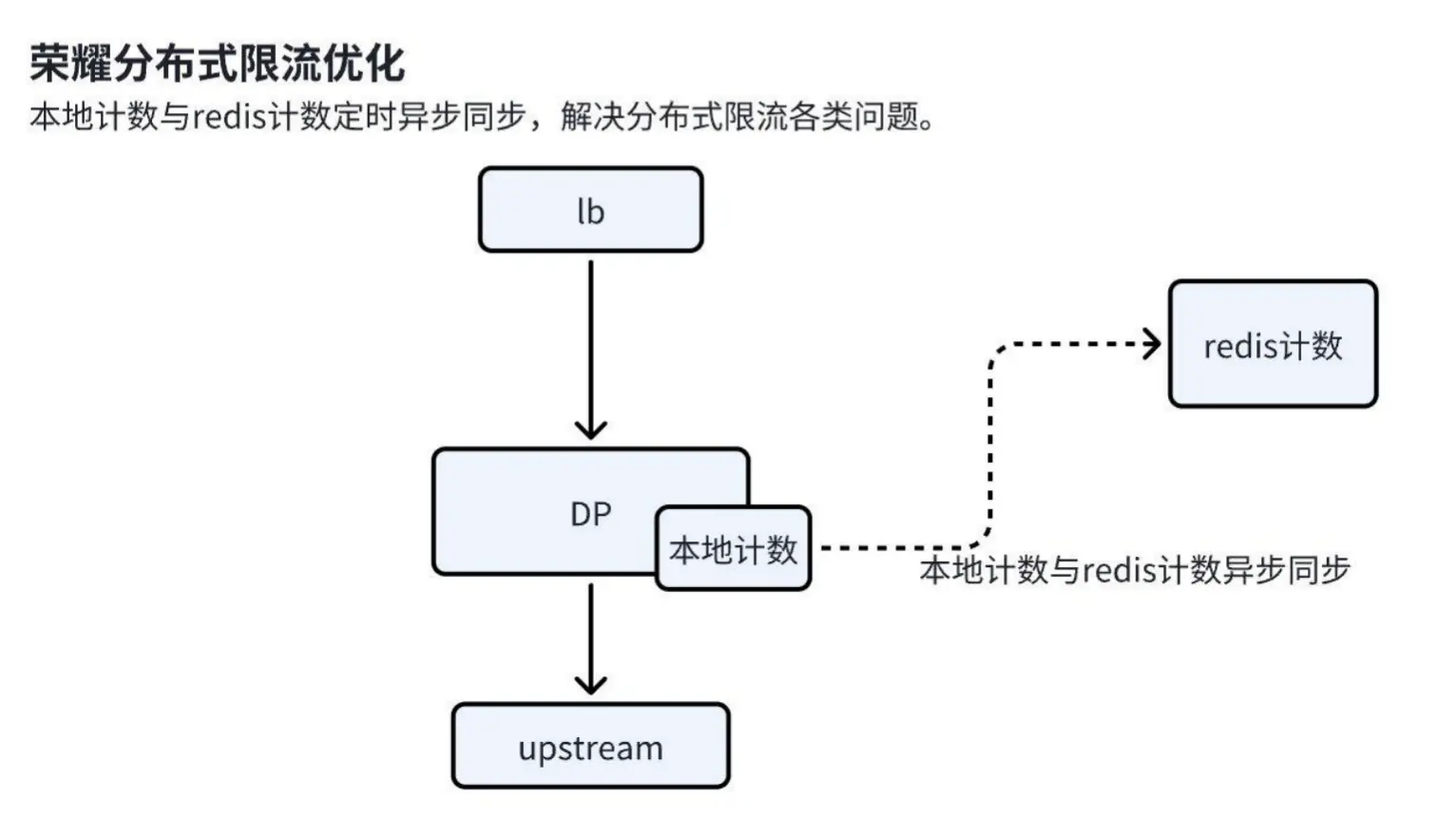
Click to Preview
a. 本地计数机制:请求到达时,首先在本地计数缓存中扣除一个计数。只要计数未降至 0,请求即被放通。
b. 异步同步机制:本地计数通过异步方式定期与 Redis 同步,统计两次同步期间的请求量,并在 Redis 中扣除相应的计数。同步完成后,Redis 的计数覆盖本地缓存,确保分布式限流的一致性。
适用场景