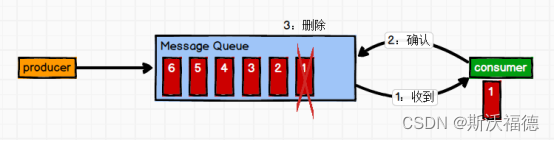
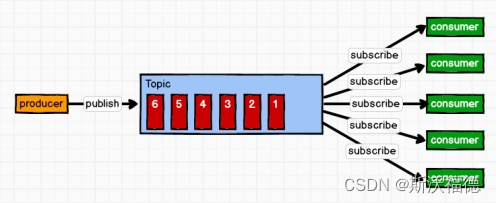
源码
1.单线程
2.aof 和 rdb
1.单线程
2.aof 和 rdb
为什么说他轻量级
:::color4
因为像原来的platform thread创建时,需要在栈空间上分配1mb的内存,1000个线程就需要1g栈空间
而虚拟线程则不用
:::
执行原理
:::color4
当我们创建并且运行虚拟线程时,jvm后台会帮助我们去创建一个platform thread pool,且pool size=Runtime.getAvailableCore
我们可以像创建普通Java对象一样创建虚拟线程,你可以把虚拟对象看做平台线程的普通版的。那他要如何执行呢,它会绑定到平台线程上。且一个平台线程只能绑定一个虚拟线程,当虚拟线程里的任务执行完时就会断开。
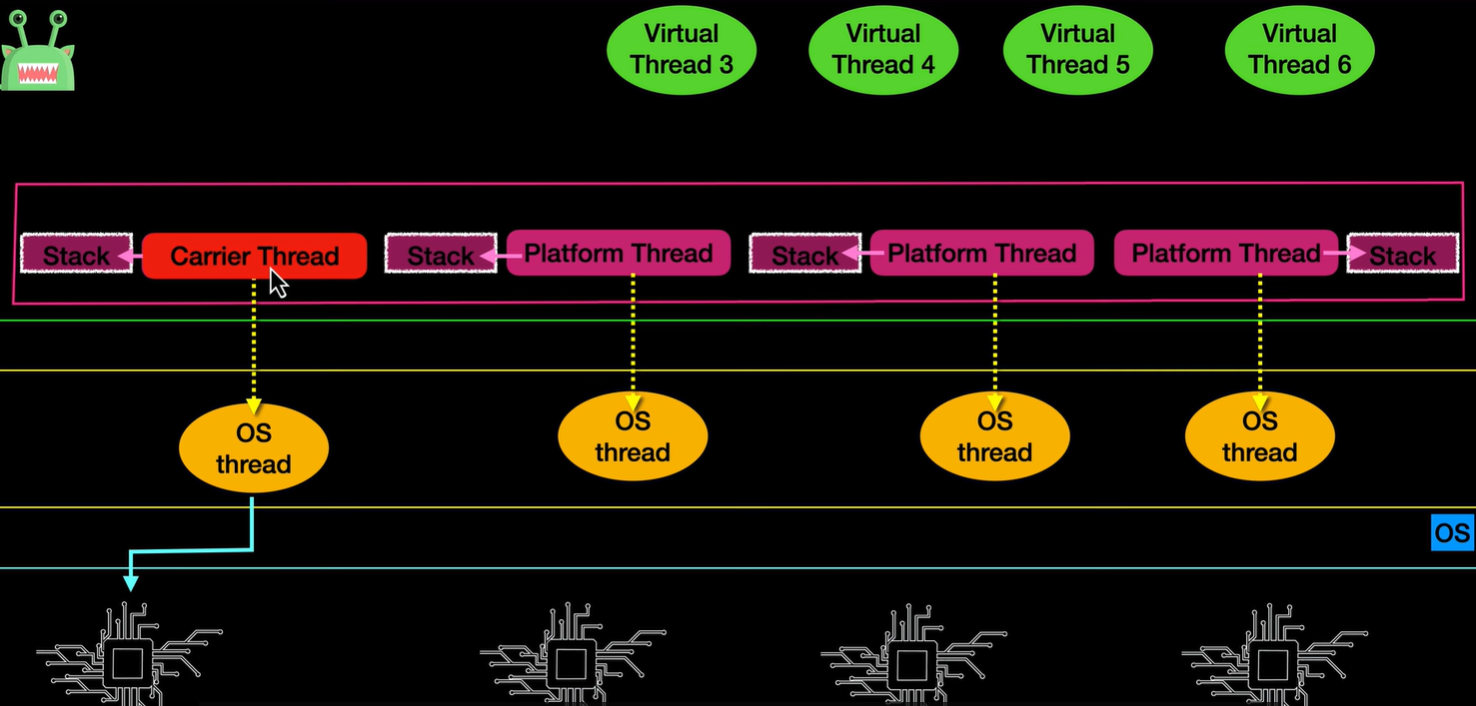
:::
适用场景:
:::color4
IO阻塞任务!!!!
为啥?阻塞时,虚拟线程会剥离平台线程,然后会生成堆栈快照。且它阻塞完重新被jvm bind到platform thread时会把原来的platform堆栈删掉,并且把之前剥离时产出的堆栈copy并加载到平台线程的堆栈,从而继续完成
最大的好处就是在IO任务避免浪费了cpu
:::
那如果一个虚拟线程阻塞后发现所有线程都被占用了,那会发生什么?
:::color4
就继续等待,就这么简单
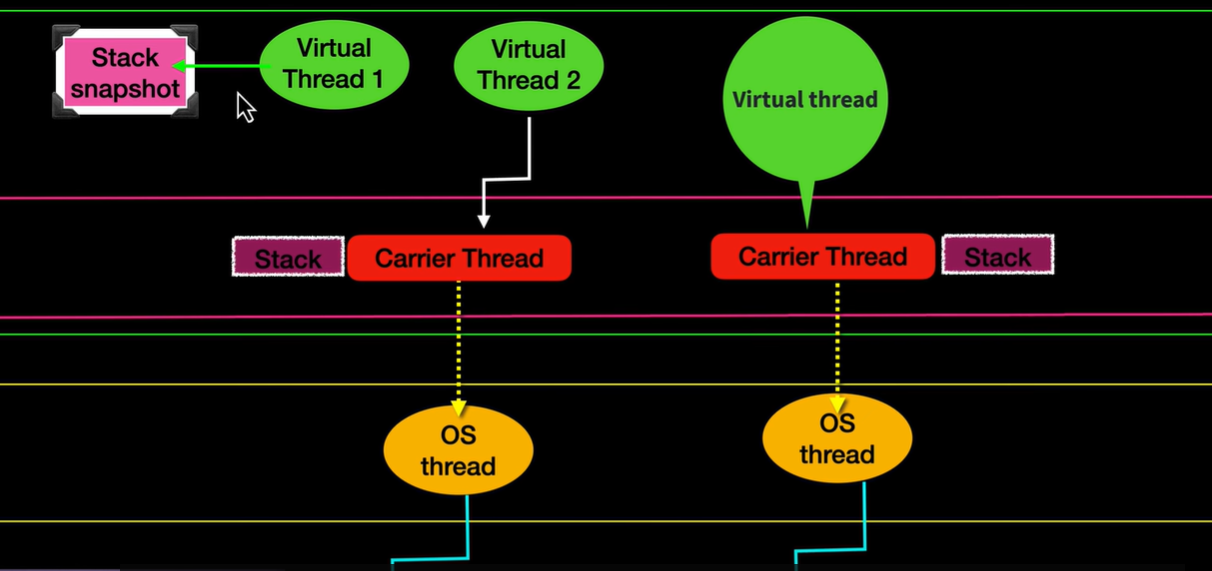
:::
意义
:::color4
1.内存占用小
2.虚拟线程的开销比较小,因为只有mouting or unmouting。但平台线程的parking就会继续上下文切换,这就涉及到用户->内核->用户
:::
:::success
在大多数现代 OS(比如 Linux)里,线程调度由内核完成,所以线程上下文切换通常伴随 用户态 ↔ 内核态 的切换。
上下文切换 (Context Switch) 指的是 CPU 从执行一个线程(或进程)切换到另一个线程(或进程)。
切换时需要保存和恢复很多内容,例如:
👉 换句话说,就是 CPU 不能“中途换人跑”,必须先把当前线程的“执行现场”保存好,再加载另一个线程的“执行现场”。
:::
JDK1.5开始,开始将工作单元和工作机制分离开来,工作单元就是Runnable和Callable这种,
而具体工作由Excutor具体提供
在hotspot vm的线程模型中,用户线程和内核线程是一对一的
Excutor可以分为两个部分,一个是架构一个是其包含的组件
Excutor的结构
1.任务:执行的任务需要实现的接口:Runnable(无返回值)和Callable(有返回值)
2.任务的执行:任务执行的core interface:Excutor接口,以及继承于这个接口的ExcutorService接口。
ExcutorService接口有两个非常重要的实现类,ThreadPoolExcutor和ScheduleThreadPoolExcutor
3.异步计算的结果:包括接口Future和实现接口Future的FutureTask类
Executor框架的成员:
- ThreadPoolExecutor
- ScheduledThreadPoolExecutor
- Future接口
- Runnable接口和Callable接口
Runnable、Callable、Future、RunnableFuture、FutureTask、CompletableFuture:

Runnable:只有一个void run()方法,Thread实现了这个接口,所以创建Thread的时候实现这个接口,然后thread.start()就能创建一个线程执行run(),或者往Thread构造方法中传入Runnable的一个实现类。
Callable:有返回值的call()方法
Future:接口,异步获取任务结果
RunnableFuture:接口,其实就相当于异步的Runnable
**FutureTask:RunnableFuture的实现类。内部其实内聚了一个Callable,即使你用第二个构造方法传入Runnable,也会包装成Callable!所以其实就相当于异步的Runnable和Callable(适配器模式),里面的run方法就是执行Callable的call()!其线程安全通过CAS保证 **
CompletableFuture:实现了Future接口,提供了许多更为强大的功能,使用:Java CompletableFuture
ScheduleThreadPoolExcutor
构造方法和普通线程池一样,或者使用Executors.newScheduledThreadPool(int coreSize)
核心方法:
延迟执行一次:schedule(Runnable command, long delay,TimeUnit unit)
固定频率执行:scheduleAtFixedRate(Runnable command, long initialDelay, long period, TimeUnit unit),首次在initialDelay后执行,之后每隔period时间执行一次。如果任务时间超过周期,会等待上次执行完毕
固定延迟执行:scheduleWithFixedDelay(Runnable command, long initialDelay, long period, TimeUnit unit),和上面类似,但每次计算是上次任务结束后开始计算延迟

1.运维问题
原生部署zk需要强制部署 zk,这使得kafka运维人员需要同时具备运维zk和kafka的能力
2.为了保证可用性
原生kafka与zk交互是依赖单个broker即Controller,如果旧broker故障了,会选举出一个
新的Controller节点。新的Controller继任成功,会从zk上拉取元数据同步初始化,同时通知其他broker更新
新的ActiveControllerID。且旧broker需要关闭监听、事件处理线程和定时任务。这个过程如果partition特别多,
那么就会导致整个过程非常漫长,且这个过程kafka是无法处理消息的,处于不可用状态
3.分区瓶颈
当分区数增加时,<font style="color:rgb(10, 191, 91);background-color:rgb(243, 245, 249);">Zookeeper</font>保存的元数据变多,<font style="color:rgb(10, 191, 91);background-color:rgb(243, 245, 249);">Zookeeper</font>集群压力变大,达到一定级别后,监听延迟增加,
给<font style="color:rgb(10, 191, 91);background-color:rgb(243, 245, 249);">Kafaka</font>的工作带来了影响。所以,<font style="color:rgb(10, 191, 91);background-color:rgb(243, 245, 249);">Kafka</font>单集群承载的分区数量是一个瓶颈。而这又恰恰是一些业务场景需要
的。
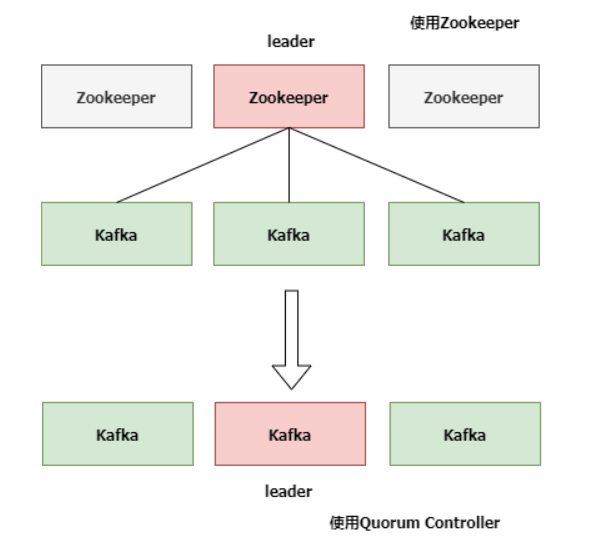
<font style="color:rgb(10, 191, 91);background-color:rgb(243, 245, 249);">KIP-500</font>用<font style="color:rgb(10, 191, 91);background-color:rgb(243, 245, 249);">Quorum Controller</font>代替之前的<font style="color:rgb(10, 191, 91);background-color:rgb(243, 245, 249);">Controller</font>,<font style="color:rgb(10, 191, 91);background-color:rgb(243, 245, 249);">Quorum</font>中每个<font style="color:rgb(10, 191, 91);background-color:rgb(243, 245, 249);">Controller</font>节点都会保存所有
元数据,通过<font style="color:rgb(10, 191, 91);background-color:rgb(243, 245, 249);">KRaft</font>协议保证副本的一致性。这样即使<font style="color:rgb(10, 191, 91);background-color:rgb(243, 245, 249);">Quorum Controller</font>节点出故障了,新的<font style="color:rgb(10, 191, 91);background-color:rgb(243, 245, 249);">Controlle</font>
<font style="color:rgb(10, 191, 91);background-color:rgb(243, 245, 249);">r</font>迁移也会非常快。
即由单个Controller变成了多个Controller,即由独裁变为了议会制
升级kafka后,官方说轻松支持百万partition
早期kafka集群是由zk来保证,我们公司也是,后面kafka更新了,不需要zk了
早期版本:Consumer靠zk来保存offset,而producer不与zk打交道
早期版本:
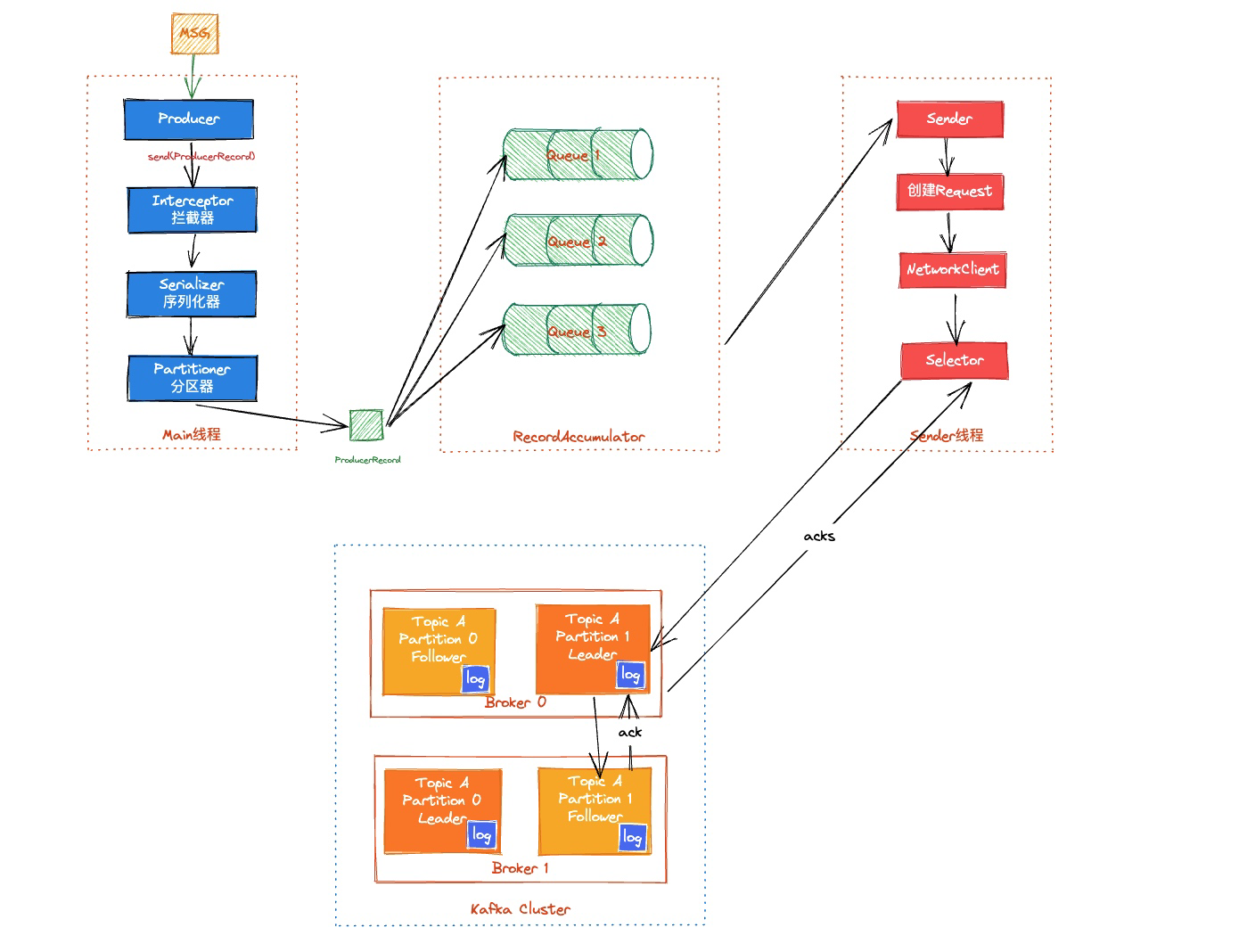
1. producer需要找到集群,并把那个数据放到某个分区中。而这个leader端口号和分区存在zk中,集群和zk一直处于连接状态,partition的leader端口号回由集群去拿出,然后producer会向集群拿到topic对应的partition以及partition的leader信息
2. <font style="color:rgb(85, 85, 85);background-color:rgb(253, 253, 253);">当Producer通过Sender从集群获取到partition和Leader信息,若</font>**<font style="color:rgb(85, 85, 85);background-color:rgb(253, 253, 253);">有指定partition则使用指定的partition</font>**<font style="color:rgb(85, 85, 85);background-color:rgb(253, 253, 253);">,若没有则使用分区算法对key做操作;当没有key则轮询partition;</font>
3. producer会先把数据存入DQ中,每一个partition一个DQ,就是一种消息聚合的方式,sender会轮询,队列满了或者到达一定的时间周期,就会发送给leader。
Producer给Leader发数据使用批处理,如果没有批处理每次发送都建立连接在进程间做交互,会使效率很低
4. leader将数据写入本地的log日志分段
5. 后续Consumer轮询从broker拉取消息,Kafka的ACK应答机制(producer,三种,0,1,2 );
三种ACK模式:
当取值为0,则不关心是否到达,尽最大努力交付,效率高,数据可能丢失;
取值为1(默认),Producer的发送数据,需要等待Leader的应答才能发生下一条,不关心Follower是否接收成功,性能稍慢,数据较安全,但当Leader突然宕机,则当Follower还未同步,数据会丢失;
取值为 -1(all) ,Producer发送数据,需要等待ISR内的所有副本(leader和所有Follower)都完成备份,最安全,性能差;需要等待follower一定时间后拉取数据,也就是这个”一定时间”是其效率的主要影响
sender方法:
1.producer会将数据push到broker上,每条消息会被追加到topic下的一个partition里的log文件里的末
尾,保证分区有序性,且会顺序写入磁盘
2.为了不让log文件过大,kafka还采用了分区分段存储,即log体积达到了某个阈值,就会生成新的log文件,
后面来的消息会追加到新的文件里
3.文件结构
一个topic里有多个partition,partition内有多个segement,一个segement包括三个文件index,log, timeIndex
partition就是一个文件夹,属于物理概念。命名规则为 topic + 分区号 如 first-1
而segement也是个逻辑概念
index,log文件命名为 segement里第一条消息的offset
首先kafka是分布式集群,吞吐量大。天生分布式,随便加机器
这里的零拷贝是对于应用层而言
我们要将磁盘的数据发送到远端的服务器去,一般的应用做法是
0.调用系统函数read,切换为内核态
1.先将数据从磁盘拷贝到page cache
2.然后切换到**用户态,**将数据拷贝到应用层
3.切换为内核态,调用write,将数据写入page cache
4.最后将page cache 拷贝到网卡 缓冲区
5.切换为用户态,继续程序的运行
这其中需要经过四次拷贝,四次用户内核态切换
而对于sendFile的零拷贝
**数据不需要再拷贝到应用层,而是由内核态全程负责,让数据从磁盘拷贝到内核缓存,然后直接发给NIC **
网卡缓冲区,且用户态内核态也只需要切换两次
PS:DMA
Leader将文件切分为多个segement,好处就是让 IO更快
Topic→partition→segment
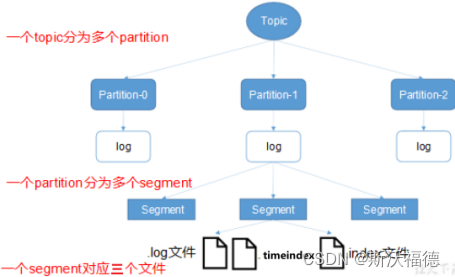
index、log以当前segement的第一条消息的offset命名,以便可以快速查找
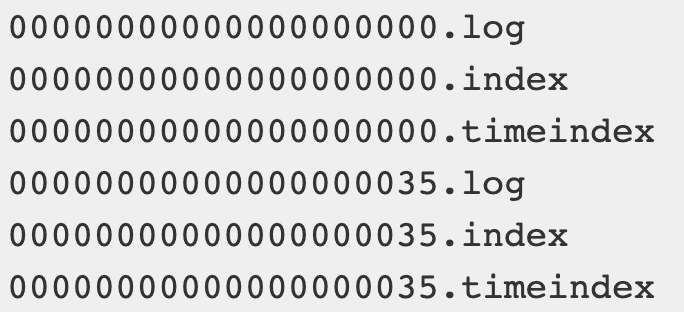
log里面存的是消息,而index里存的是offset和其对应的 物理偏移

Kafka消息(存储)格式及索引组织方式 - 杭州.Mark - 博客园
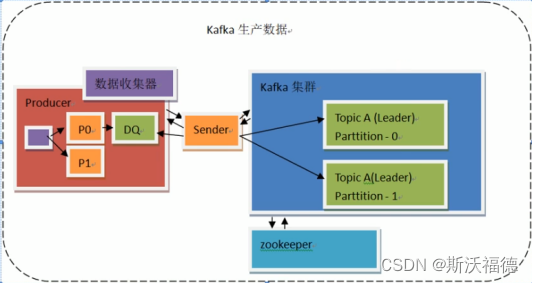
在producer这边,每一个partition在其producer都会对应着一个DQ
1.producer发送数据时都会往这个DQ里存消息
2.DQ满了或者一定的时间周期到了,producer就会拿出里面的消息,send到broker的Leader里。这即满足了
partition里消息的有序性,还提高了效率性
但消息聚合会降低一定的实时性
而Consumer这边也是一样,先拉取一批数据到本地的DQ里,然后消费
压缩:给的字符串,会被压缩成byte数组,压缩后数据小,传输快
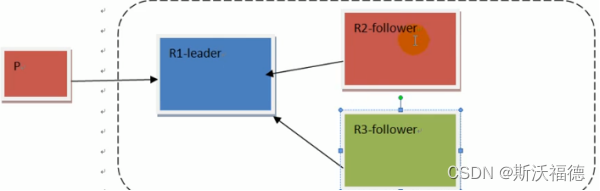
提供可靠性支持,每个partition都会其replication。broker会从这些里面选举其Leader和follower。
Leader和follower其实都是副本
producer和Consumer只会和 Leader交互
Leader会将数据同步到follower,如果Leader主动push数据,这时候会让Leader负载过大,故这时候
应该让follower主动定时去pull数据
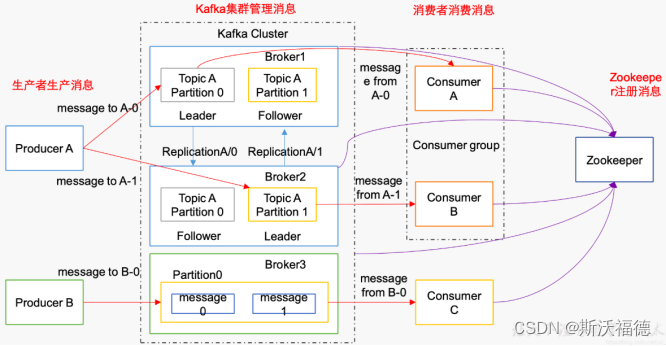
Kafka集群的目的是保存消息,Producers往Brokers里面的指定Topic中写消息,Consumers从Brokers里面拉去指定Topic的消息,生产者把数据以K、V的方式传给集群;
首先Kafka需要多台机器组成一个Kafka集群才能承载负荷,每一台服务器是一个Broker,
数据有多种进行分类 → 一个Broker中有Topic主题
为了提高负载 → 一个Topic有多个partition分区,一个partition可以放在多个不同的Broker上,而数据放在不同的partition当中(取模的方式),可以让不同的消费者来消费,提高消费速率
为了防止数据丢失 → 每个分区下有多个副本,即Leader和Follower,Leader做io处理,Follower只作备份,多个分区进行“交叉备份”,Follower从Leader中实时同步数据,当Leader挂掉后,Follower会代替Leader。
以【消费者组】为单位进行读取数据,其中一个消费者读取一个partition分区,所以一般partition分区数量=消费者组中的Consumer消费者数量,以保证分区内数据有序;
Zookeeper:kafka集群依赖zookeeper来保存集群的的元信息,来保证系统的可用性。
Kafka -> Broker -> Topic -> partition -> Replication(Leader、Follower) ->Consumer
1)Producer :消息生产者,就是向 kafka broker中的Topic主题发消息的客户端;
2)Consumer :消息消费者,向 kafka broker中的Topic中 取消息的客户端;
3)Consumer Group (CG):消费者组,由多个 consumer 组成。消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费;消费者组之间互不影响。 所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
4)Broker :一台 kafka 服务器就是一个 broker。一个集群由多个 broker 组成。 一个 broker可以容纳多个topic。
5)Topic :可以理解为一个队列,生产者和消费者面向的都是一个 topic;topic逻辑上的概念,partition是物理上的概念;
6)Partition:为了实现扩展性,一个非常大的 topic 可以分布到多个broker(即服务器)上,一个 topic 可以分为多个 partition,每个 partition 是一个有序的队列;partition中的每条消息都会被分配一个有序的id(offset)
7)Replica:副本,为保证集群中的某个节点发生故障时,该节点上的 partition 数据不丢失,
且kafka 仍然能够继续工作,kafka 提供了副本机制,一个 topic 的每个分区都有若干个副本,一个 leader 和若干个 follower。
8)leader:每个分区多个副本的“主”,生产者发送数据的对象,以及消费者消费数据的对象都是 leader。
9)follower:每个分区多个副本中的“从”,实时从 leader 中同步数据,保持和 leader 数据的同步。leader 发生故障时,某个 follower 会成为新的 follower。
10)Offset:偏移量, kafka的存储文件都是按照offset.kafka来命名,用offset做名字的好处是方便查找。例如你想找位于2049的位置,只要找到2048.kafka的文件即可。
当然the first offset就是00000000000.kafka。