主从同步
知识准备
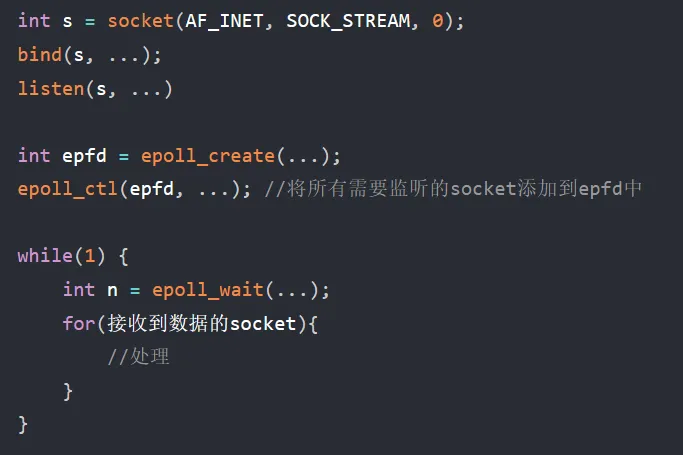
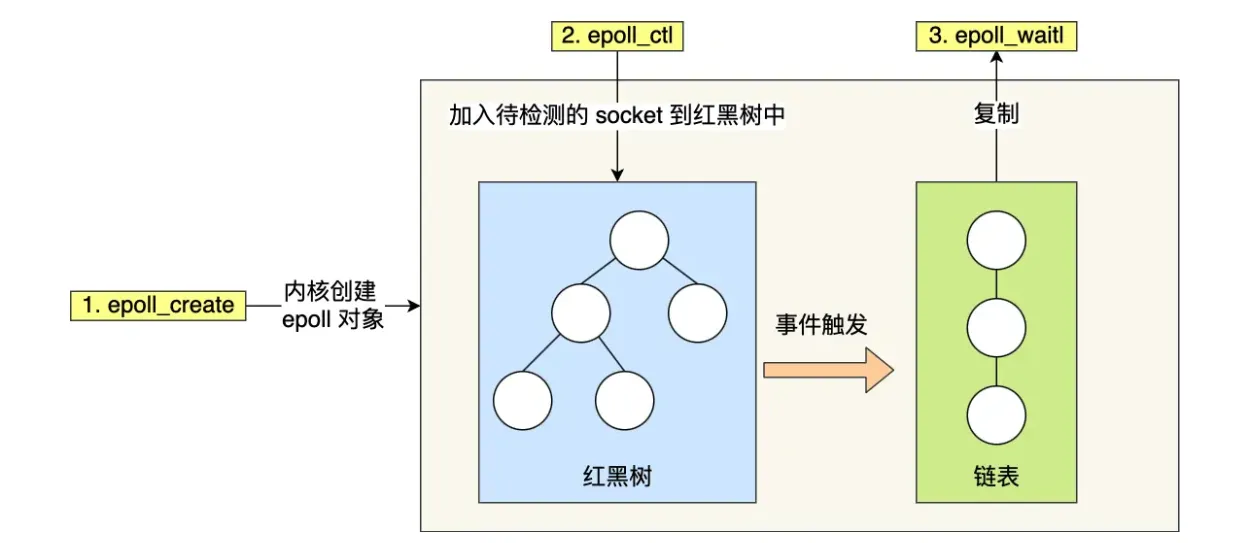
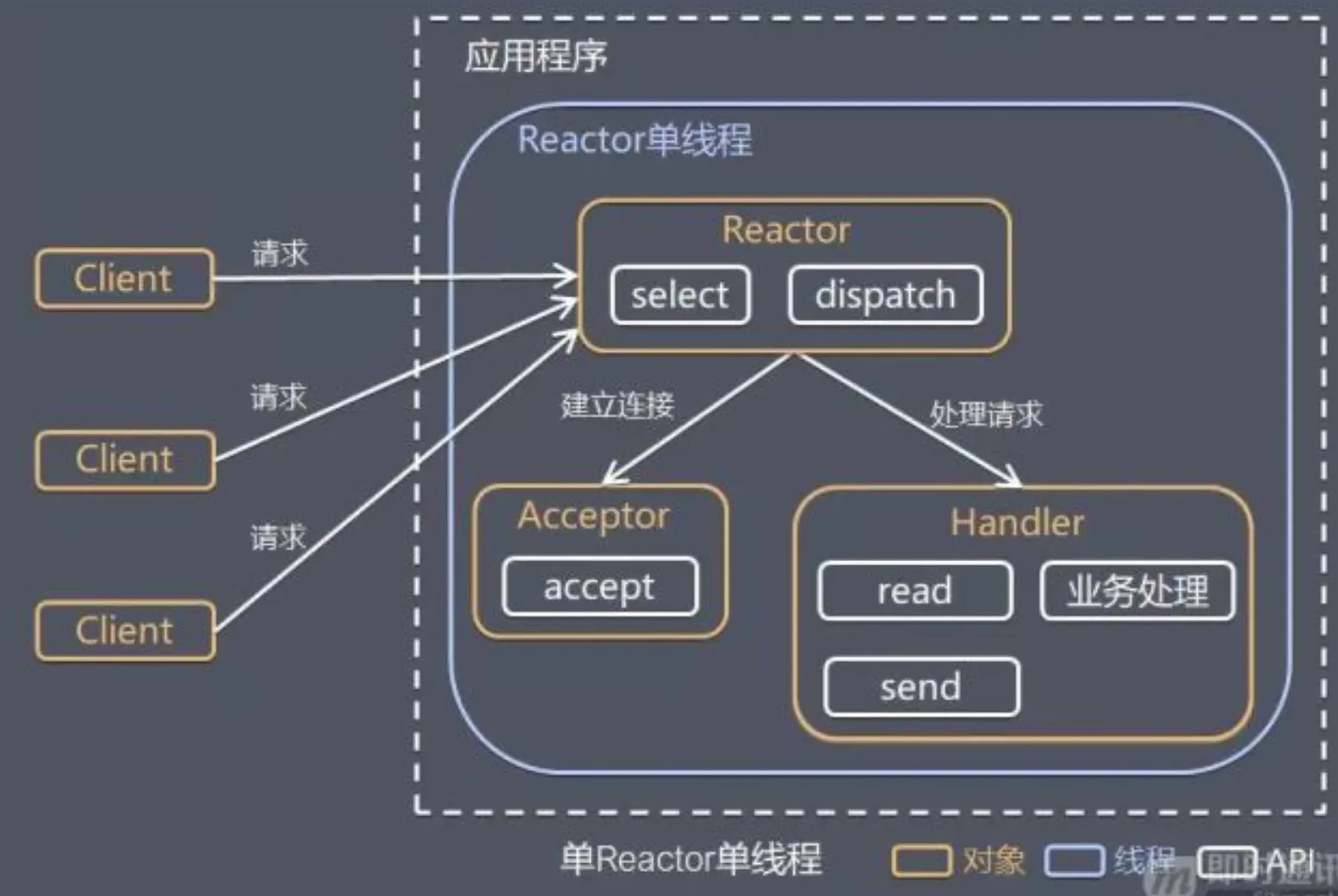
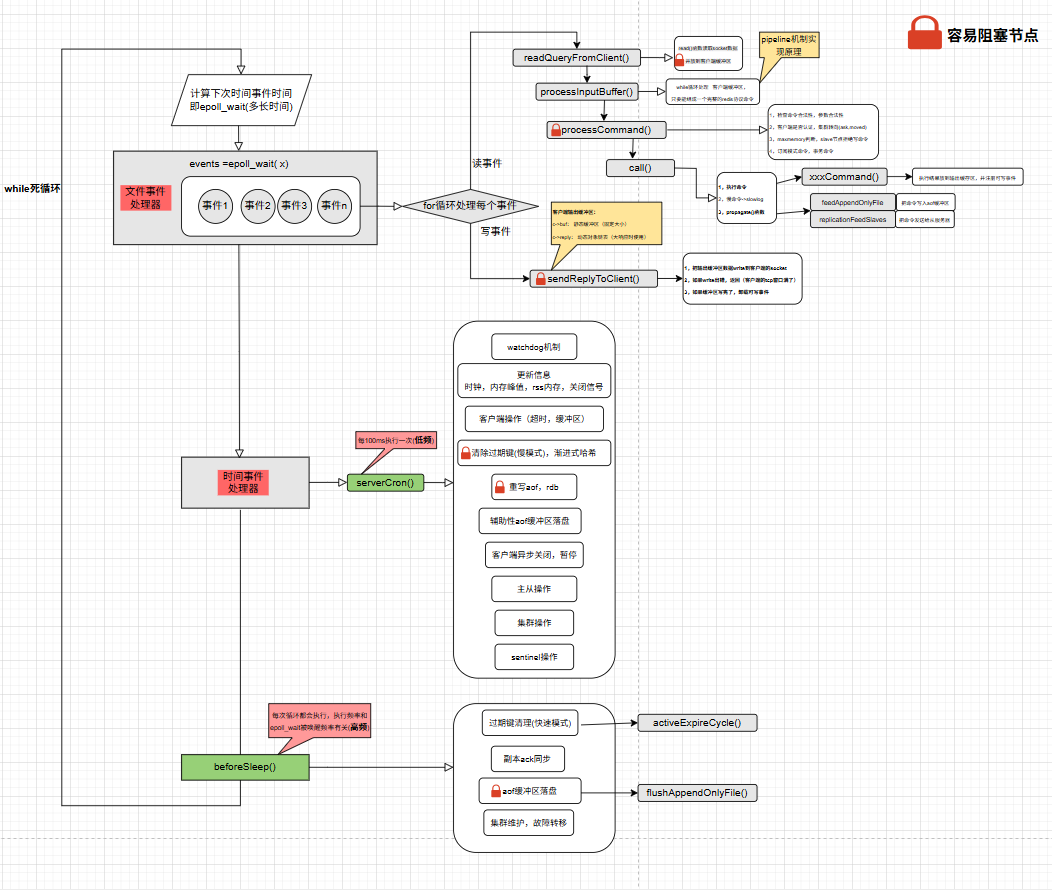
IO复用:
https://zhuanlan.zhihu.com/p/367591714
两种触发
水平触发:这次不处理,下次还是会触发
边缘触发:只触发一次
两种事件
可读事件:内核缓冲区有数据可读
可写事件:内核缓冲区还有空间即 对方tcp窗口还没满。在IO多路复用情况下,两个Socket啥事没干,可写事件是会一直触发的
Redis:
- 一般地客户端的可读事件会一直注册在那个epoll wait里的,没处理事件会持续触发,避免数据丢失
- 而写事件,只有在输出缓冲区有数据时注册,完成后立马注销
主从复制
命令执行以及架构
1 |
|
主从复制详细过程
场景说明
- 初次建立主从关系,必定是全量同步。(从节点会把本身旧的数据给删了)
- 全量同步完成后,主从节点进入命令传播阶段,此时主节点会将每个写命令同时发送给所有从节点
- 如果此时网络闪断导致主从连接断开,之后重新连接时,从节点会发送PSYNC命令携带之前保存的主节点runID 和 复制偏移量 (很像断线重连哦)
- 主节点检查runID 是否匹配,且复制偏移量是否还在复制积压缓冲区范围内
- 如果条件满足,主节点只需要发送缺失的那部分命令即可,这就是部分同步
初次主从同步
(从)执行slaveof ip host
1 | slaveofCommand() -> replicationSetMaster() |
(从)下一次事件循环 【建立tcp连接】
1 | serverCron() -> replicationCron() -> connectWithMaster() |
(从)再下一次事件循环 【发送ping】
1 | syncWithMaster(){ |
(主)两个事件,回pong,同步从节点信息给客户端
1 | readQueryFromClient() -> pingCommand() -> addReply() |
5,(从)主服务器写数据 触发可读事件 ( 触发注册了的syncWithMaster)
1 | //2.8之前,Redis从节点断线重连 智能全量重同步 |
6,(主)收到 sync命令,进行准备
两种:全同步装备rdb文件,部分重同步 同步命令
1 | "sync"/"psync" readQueryFromClient() -> syncCommand() |
rdb执行完后,为从客户端安装写事件
1 | serverCron() -> backgroundSaveDoneHandler() -> updateSlavesWaitingBgsave() |
发送rdb 文件
1 | sendBulkToSlave() //主 |
超时和典型问题
默认60s从节点不回复,视为超时
REPLCONF ACK:从节点每秒上报偏移量,主节点检测延迟
典型为题:
数据不一致场景:
网络延迟,解决:监控master和slave的offset
从节点执行key * 阻塞,解决:避免在从节点执行慢查询
全量复制风暴:
导致主节点压力大,解决:错峰同步,级联更新