哈希表
无重复字符的最长子串[🔥990][中]
题目:就是给一个str,然后让你找到无重复字符的最长子串
思路:
- 整体就是滑动窗口
- map来存储子串的字符状态
- r++ ,map不断更新,map.put() while(map.get(xx) > 1){ l++; map.put()去把map里的之前状态消掉 } res不断更新
两数之和[🔥285][易]
题目:给你一个数组,一个target。然后让你去从数组中找到能组成target的元素
思路:
- 数组 先存一遍 cache set
- 遍历一遍数组,然后 cache.contains(target - curV) 如果为true ,就更新
二叉树的中序遍历非递归
题目:用非递归的形式输出二叉树的中序遍历
1 |
最小覆盖子串[🔥114]
题目:给你一个字符串 s 、一个字符串 t 。返回 s 中涵盖 t 所有字符的最小子串。如果 s 中不存在涵盖 t 所有字符的子串,则返回空字符串 "" 。
输入:s = “ADOBECODEBANC”, t = “ABC”
输出:”BANC”
解释:最小覆盖子串 “BANC” 包含来自字符串 t 的 ‘A’、’B’ 和 ‘C’。
思路:
- 整体还是滑动窗口
- 维护一个map,map为t的映射表(k:字符,v:字符出现个数)。一个cnt,cnt初始化为 t的字符个数,表示还剩多少个字符可构成 t
- r++直到找到了t的第一个元素,ifxxx>0,cnt–,map[c] –
- while(cnt==0) 开始更新结果,且把最左边的东西弹出去
1 | class Solution { |
时间复杂度:O N(s.length)+M(t.length)
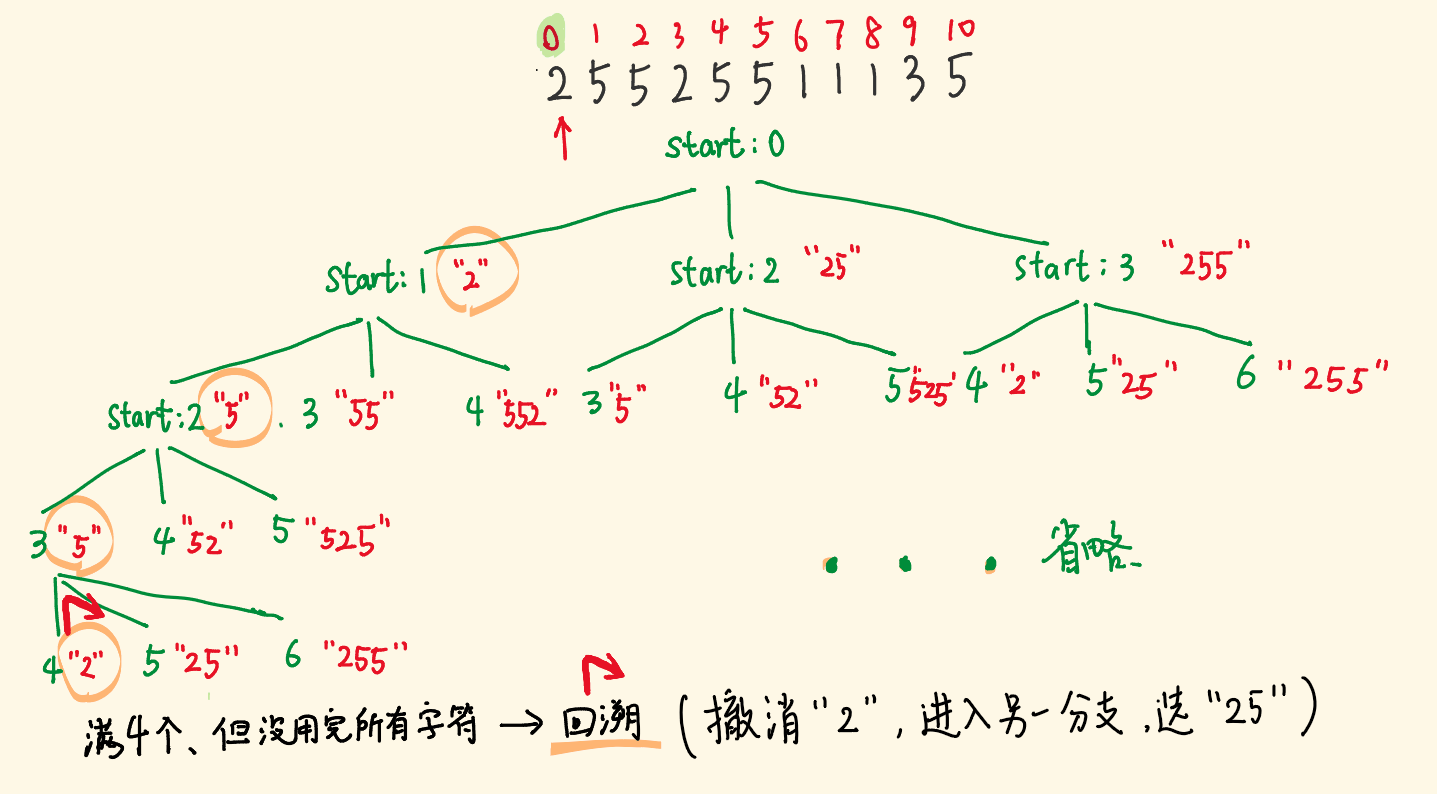
找到字符串中所有字母异位词[🔥15][中]
题目:就是给你一个source,一个target,然后找出source字符串里面的包含target所有字符的字符子串
思路:
- 整体就是滑动窗口
- 然后初始化一个 26个字母的数组 [0 1 2 ……. ]
- 长度<target.length()就跳过
- 啥时候更新结果:当上面那个数组等于 target的数组模式时就更新
1 | class Solution { |
评论
评论
最热 | 最新

puffan
2021-06-23
滑动窗口O(n)
3
暂无回复
回复

一天到晚只会刷算法的疯狂javaer
2023-08-16
我直接一个滑动窗口滑滑滑
2
暂无回复
回复

Li
2022-08-19
华子实习手撕
2
暂无回复
回复

伟
2022-02-28
滑动窗口算法, 跟字符串排列思路一样
1
暂无回复
回复

Thirt33n
2024-07-09
字节三面
0
暂无回复
回复

用户OTCHR
2023-02-02
滑动窗口
0
暂无回复
回复

小号备战校招
2022-11-06
字节一面,跟567一样
0
暂无回复
回复
思路1:
- 给出前缀和
- 转化为两数之和 即求 i(前缀和)-k的元素是否存在
思路2:
- 就是map方式的前缀和
思路3:
- 动态规划
1 | class Solution { |
最长重复子数组[🔥64]
题目:给两个整数数组 nums1 和 nums2 ,返回 两个数组中 公共的 、长度最长的子数组的长度 。
思路:
- 滑动
复制带随机指针的链表[🔥58]
题目:拷贝特殊链表节点
思路:
- 普通链表初始化
- 初始化两个MAP
- 一个记录旧链表里 节点与index的关系
- 一个记录新链表里 index与节点的关系
- 由于新旧节点 index是一样的
- 故 旧链表可以通过node.random拿到该random.index
- 再通过index拿到新链表的node
1 | /* |
前 K 个高频元素[35]
思路:hashmap统计+优先级队列维护前k个高频元素
无法单单用TreeMap排序,因为 TreeMap 只能按 key 排序,不能用value
优先级队列:
PriorityQueue
- map统计 次数
- 构造最小堆,且维护数量为k个,大于就驱逐最小的
- 然后到最后剩下的就是前k个高频元素了
Q:为什么不用最大堆?
A:最大堆,堆顶最大元素,你怎么驱逐堆低元素?
1 | class Solution { |
两个数组的交集[24]
思路:查重就用Set 或者Map!!!!!!!!!!
contains
1 | class Solution { |
retainAll的用法:求两个集合的交集,会把非交集的元素remove掉
1 | HashSet<Integer> objects = new HashSet<>(); |
面试官会先问:两个数组求交集,怎么求?以及说一下时间复杂度(不允许使用编程语言自带的交集功能)。答完之后再问:如果两个数组都是非递减的,又应该怎么求?时间复杂度多少?(本人亲身经历)
三数之和[436]
思路:
- 排序 + 三指针(i [l , r])+ Set(自动去重)
- 排序 + 三指针 + 手动去重(剪枝)
1 |
1 |
|
四数之和[21]
二数之和:哈希
三数之和:排序 + 双指针 + 剪枝
四数之和:排序 + 双指针 + 剪枝
思路:
1 |
O(1) 时间插入、删除和获取随机元素[18]
思路:hashMap+数组
Map:k为值,v为index,这样就可以containsKey了,杜绝重复insert
数组就是用来存放元素的
并且维护一个index
1 | class RandomizedSet { |
前K个高频单词[18]
题目:
给定一个单词列表 words 和一个整数 k ,返回前 k 个出现次数最多的单词。
返回的答案应该按单词出现频率由高到低排序。如果不同的单词有相同出现频率, 按字典顺序 排序。
看题啊尼玛的
思路:
- hashmap统计
- 最小堆维护前k个高频单词
1 | class Solution { |

167. 招式拆解 I[17]
有效的字母异位词[17]
1 | class Solution { |