八股面经
计网
小红书日常二面
HTTP传输最小的一个字节,是多大的数据包?
:::info
“在 HTTP 层,理论上可以只发送 1 个字节的数据,例如一个非常小的响应体。
但是 HTTP 是基于 TCP 的,而 TCP 又基于 IP,所以在网络上传输时,会被封装成 TCP/IP 数据包。
- TCP 报文段最小有 20 字节 TCP 头 + 20 字节 IP 头,总共至少 40 字节。
- 如果是在以太网环境下,以太网帧最小长度是 64 字节,低于这个长度会自动填充。
所以即便 HTTP 只发送 1 个字节,网络层实际传输的最小数据包大约是 64 字节。
总结来说,HTTP 层最小可以 1 字节,但网络上实际传输受到协议栈和以太网最小帧限制。”
假设你在浏览器访问网站,发送了一个 HTTP GET 请求,只有 1 个字节的响应体(比如返回 “A”):
- HTTP 层:响应内容是 “A”,只有 1 字节
- TCP/IP 层:加上 TCP 头 20B + IP 头 20B → 40B
- 以太网层:以太网帧最小 64B,不够 64B → 自动填充
- 结果:即使 HTTP 只传 1 字节,实际在网线上传输的也是 64 字节的帧
所以“以太网帧”就是你电脑和路由器之间实际在网线里流动的数据单元。
:::
HTTPS的原理?和HTTP区别?
:::info
HTTPS 的原理,其实就是在应用层和传输层之间加了一层 TLS/SSL,用于对 HTTP 传输的数据进行加密。
它涉及几个关键点:
- 握手过程
- 首先客户端发起请求,同时发送一个随机数、支持的密码套件,以及椭圆曲线相关参数(基点等)。
- 客户端本地生成一个临时私钥,并计算出对应的公钥发送给服务端。
- 服务端响应
- 服务端收到请求后,生成一个随机数,选择密码套件,也生成一个临时私钥。
- 每次请求都会生成新的临时私钥,以保证前向安全性(即每次会话的密钥都是唯一的,不使用固定私钥)。
- 密钥协商
- 双方通过椭圆曲线的基点、各自的私钥以及对方发送的公钥,计算出本次会话的对称加密密钥。
- 这个密钥之后用于加密 HTTP 传输的数据。
- 握手确认
- 第一次握手:客户端发起请求
- 第二次握手:服务端返回公钥和选择的密码套件
- 第三次握手:客户端确认并生成会话密钥
- 第四次握手(可选):服务端确认信息完整
- 通过这几次握手,双方最终确认一个安全的会话密钥,用于本次 HTTPS 会话
HTTP 与 HTTPS 的区别
- HTTP:TCP 三次握手后即可直接发送请求,传输的是明文数据。
- HTTPS:除了 TCP 三次握手,还要经过 TLS 握手(大约 3~4 次),建立安全的加密会话,所以传输速度略慢,但安全性高。
:::
传输是对称加密还是非对称加密?
:::info
生成密钥后的通信就是 对称加密了
生成密钥前就是 使用的是非对称加密。对称用的密钥就是
:::
淘天暑期
网络里面交换机和路由器区别?
常见网络协议?
介绍下HTTP?
操作系统
美团暑期二面
操作系统里的LRU算法?
:::info
面试官你是想问我们在那个页面置换里面的那个吗。
其实是说,在我们因为我们的操作系统它的内存是有限的么,它就是说如果我们内存到了一定的紧张程度的话,它就是需要我们通过一个算法把这个用不到的页面置换出去,操作系统底层用的是LRU算法,但它可以选择不同算法,但是不同的内核版本,它应该有不同的一个实现然后它就是说把最久没使用的页面给淘汰出去。
这个的话,它其实是可能会有一个问题,就是说我们如果一次性加载了多个页面进来后,它可能会把以前的一个老页面给顶出去,它可能会有就是其实我们所谓的一个缓存污染这么一个问题,所以说,操作系统它底层对我们这个LRU是进行了一个改进的就是说,它通过我们一个其实跟mysql的Bufferpool算法有点类似,就是分old 和 yong区分,然后他们大概是3,7分。然后它淘汰的时候,它也是优先投入小的区域,然后直到你这个小数据被访问,它才会放到我们的一个old区,就是避免一次性读取大量数据,然后把一些老的反而真正常用数据给顶掉。所以说,我觉得这是他对LRU改进最大的一个地方,也是比较核心的一个点么
:::
a.LRU的思想是什么?
:::info
它就是出于一种局部性原理,就操作系统他其实有这么一个概念,一种是时间局部性,比如说你在一定时间内访问了某个数据,未来的一段时间内,你对这个数据的访问频率可能会更大,然后还有一个就是空间局部性,就是说你访问了所谓的一个数据,然后接下来,你访问这个数据的概率也是比较大的。所以说,它就是说优先淘汰掉我们以前比较久远的一个数据吧,我觉得是这样子淘汰的一个思想嗯。
:::
用Java常见数据结构如何设计一个LRU?操作时间复杂度?线程安全性?
:::info
额如果用现成的话,我就会直接用jdk collection里自带的一个LInkedHashMap,其实说白了底层就是用HashMap+双向链表这样子。要详细说一下,然后Map就是作为我们的一个Key查询,因为我们缓存的根本目的还是希望通过一个key来实现O1复杂的查询么。所以说,我们肯定是得通过一个Map来进行一个
存储我们的缓存数据,然后LRU,比较好的数据结构就是双向链表么,它的目的就是说把访问的数据放到我们的一个头部么,然后把尾部的数据,就是我们不经常访问的数据,然后一旦我们的数据size大于我们的limit,就把这个尾部的数据delete掉么
Map<String,Node>
Node1 <=> Node2
插入的话是Map插一次,然后插到头结点,都是O1。
查找的话一个就是从Map里面查,容纳后就是从双向链表里找到节点,然后把它,因为它只涉及到指针的移动,所以也是O1
线程安全这一块的话,我觉得得看你怎么实现吧,如果你要简单粗暴的话,就是一把synchronized或者对象锁直接对增删改查进行加锁,这时候就是只允许一个线程进行增删改查。它这样就肯定是线程安全的么,但就是锁的粒度太大了,我们可以尝试把它放小,比如读写锁,只有写操作才加锁,读的话就没报要加锁了,但就是后面的链表指针的移动这些我觉得还是得加了。就具体看我们要怎么实现
:::
线程池
美团暑期二面
h.IO耗时长,吞吐上不来,cpu又吃不满,如何优化吞吐量?
7.Go和Java最大的区别?
a.协程和线程区别?
b.JDK也有类似协程的东西,你知道吗?8.如何理解“全异步链路”的?(网关介绍里的)a.做过这个事,那为什么不用异步解决刚刚说的优化吞吐的事?
场景
字节暑期
ZSet做排行榜,需要展示前1000人的榜单,1001-1500展示实际排名,1500以后展示1000+,如何处理 Bigkey?
mysql
13.自己举例一个SQL,说说MySQL是如何查数据的?
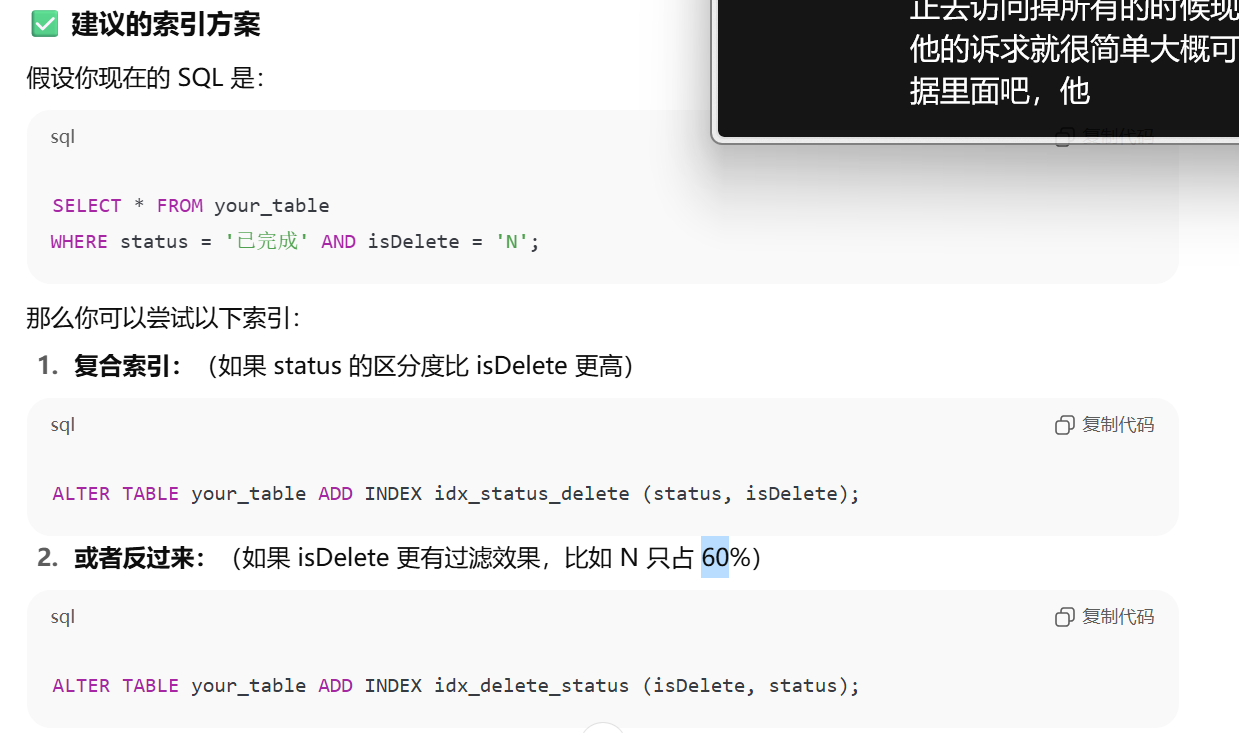
14.表中有status和isDelete字段,where status=’已完成and isDelete =’N’超时,但数据量不大,只有一两百万条,可能是什么原因?如何解决?
:::info
举个例子,在数据库索引信息里有一个字段,比如叫 Cardinality,意思就是这个索引列里面有多少个不同的值,也就是索引的区分度。
一般来说,这个值越接近表里的总行数,说明每一行的数据都不一样,区分度就越高,索引效果就越好。
但如果某个字段是状态字段,比如只有 success 和 fail 两种值,各占一半,那不管你怎么建索引,这个索引的区分度都很低,因为查询 status='success' 仍然会匹配表里 50% 的数据。
这种情况下数据库优化器可能会觉得“既然要扫一半,我干脆直接全表扫描就好了”,所以这个索引就不一定会被真正用上。
解决方案:
“虽然表只有一两百万条数据,但 status 和 isDelete 是低区分度字段,优化器认为即使用索引过滤也要扫描大部分行,所以退化为全表扫描导致超时。解决方式是建立联合索引提升选择性或者使用覆盖索引,必要时强制优化器使用索引。”
解决方案:分页出来的数据order by limit + 内存里根据主键查询 数据 过滤出想要的数据
:::