Redis 数据结构:榜单问题之本地缓存 + zset + 定时任务方案
这个案例实际上还是相当高端的。但是这个高端不是说技术难度很高,而是说思路很清晰,属于花小钱办大事的典型解决方案。
一方面,你可以把这个当做你的项目难点;另外一方面来说,你也可以在谈及 Redis zset 的时候引用这个案例。当然了,如果要是面试官问你做过啥有挑战性的事情,也可以用这个回答。
总的来说,这个案例用在初中级岗位面试中,效果非常强,能帮你建立极大的竞争优势。你在复习的时候要多琢磨这个案例之中的细节。
内容
这个案例对应的是大数据、高性能、高并发榜单的解决方案。
代码在这里:interview-cases/case21_30/case21 at main · meoying/interview-cases (github.com)
实现思路
整个实现的要点:
- 定时任务计算全局的1000名,假设每个小时计算一次。那么即便有突发热点,那么最多一个小时就能看出来;
- 将1000名定时写入到 Redis,用 zset 实时维护。写入的时候删除原有的key然后将1000名写入。这一步是为了尽可能保证榜单数据准确。
- 再起一个定时任务,每一分钟将redis中的前100名(也就是1000中的前100,有可能不是全局的前100)同步到所有节点的本地缓存上,这一步是为了访问效率
- 从本地读取榜单数据
整个过程如下图:
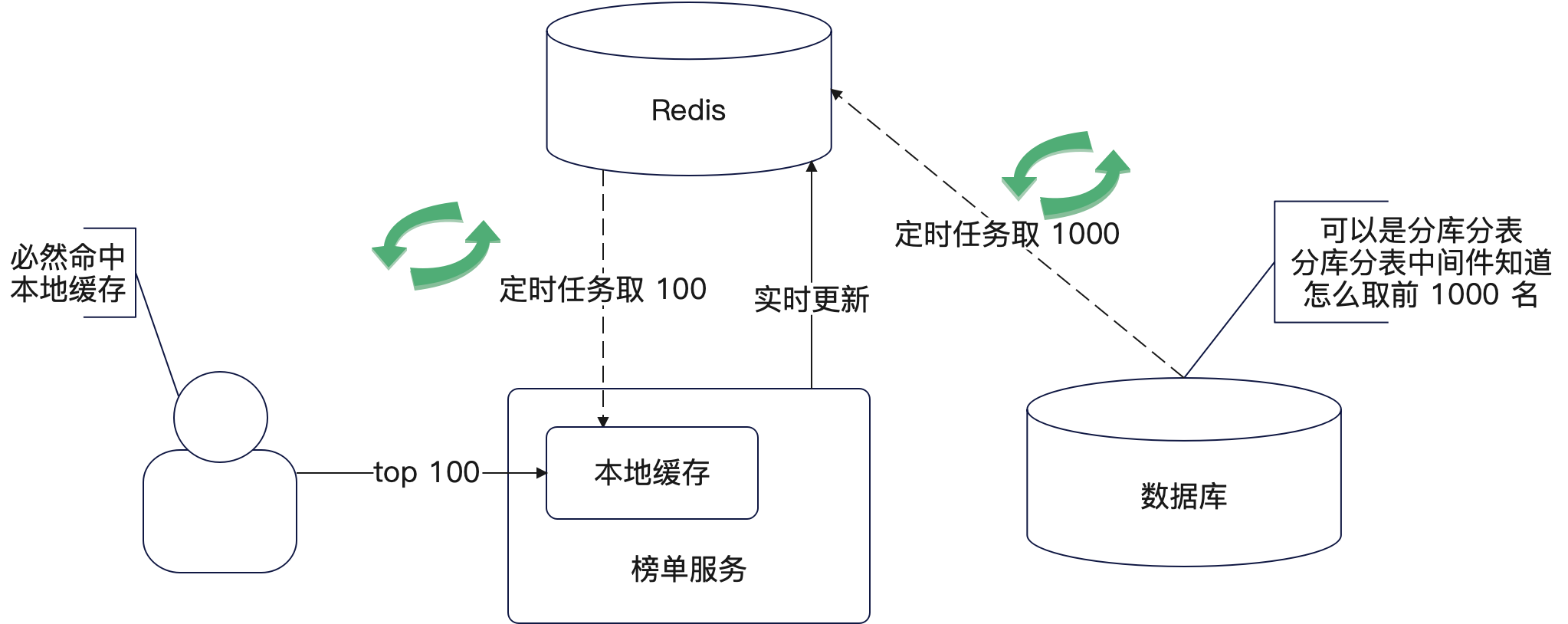
这里稍微解释一下这个案例的思路:
首先定时任务取前 1000 条,是基于这么一个假设:即这一小时内,top 100 绝大概率就是从这 1000 中选出来。如果你觉得 1000 这个太少,那么可以扩展到 10000。如果你打算进一步扩展到前 10w,那么就要考虑 Redis 分 key 了,不然会有大 key 问题。
那么会不会有例外呢?肯定会有的,比如说某个排名 1200 的热度激增,导致瞬间闯进去前 100,那么在下一次计算前 1000 的时候,它没有机会被发现。但是我们并不在意这点不精确。而且,这种不精准可以通过调低定时任务的间隔来改善。例如说改为每 10 分钟执行一次,就几乎不太可能能耐
其次则是 Redis 的 zset 主要就是为了能够尽可能精准维护这 top 100的。当然,这一步是可以去掉的,也就是只依赖定时任务每隔一段时间利用数据库的数据直接计算出来前 100。
这里还有一些细节要注意:
- 在使用 zset ZADD 命令的时候,必须要带上 XX。这样可以保证 zset 不会增加额外的元素
- 在更新的时候要注意顺序问题。举个例子来说,如果针对同一个数据,一个要更新热度为 100,一个要更新热度为 101,你要小心并发问题。最好就是在 ZADD 的命令里面再加上一个 GT 选项;
- 如果更新热度本身也是一个高并发,那么可以在更新接口之前插入一个 Kafka 操作,也就是将更新操作丢进去 Kafka 中,消费者从里面取出来再慢慢更新热度。而且消费者可以进一步叠加批量消费这种手段来优化更新性能;
.
适用场景
通常来说,你在简历里写擅长设计高性能,高可用的缓存方案或者设计过高性能高可用的榜单方案, 就可以用这个案例作为证据。遇到这些问题你就可以用这个案例来回答:
- 你的项目有什么难点?
- 你做过什么令人印象深刻的事情?
- 你觉得你做得最好的点是什么?
如果面试官问到了有关缓存、Redis、Redis zset 这些问题,你也可以使用这个案例
- 你有设计过缓存方案吗?这个方案总的来说还是很强的
- 你用过 zset 吗?
而榜单问题本身就是一个面试热点,所以这个问题也能显著帮到你,换句话来说,只要面试官问你怎么解决排行榜之类的问题,你就可以用这个案例。
可以参考以下话术来使用这个案例,这个案例是站在一个演进的角度来阐述的:
我设计过一个解决大数据、高可用、高性能的榜单方案。一开始我们业务的数据量不是很大,所以直接用了最简单的 Redis zset 来计算榜单。
后面随着业务的发展,计算这个榜单的数据越来越多,并发量越来越高,并且还引入了分库分表。这个时候,一个 zset 里面要放几百万个数据,存储这个 zset 的 Redis 并发极高,压力极大。并且 zset 中元素数量太多,导致更新的时候越来越慢。
发现这个问题之后,我就综合业务实际情况,设计了一个新的榜单解决方案。
首先每个小时计算一下全局前1000名数据写入到 Redis 中,用 zset 保存好。这 1000 个是覆盖式更新,也就是原本的 1000 会被删除,而后假如新的 1000 元素。
其次,如果收到新的更新请求,就使用 ZADD XX 来更新数据,并且确保 zset 内始终只有 1000 个元素。
最后,我再使用定时任务,每分钟计算一次 top100,同步到各个节点的本地缓存上。本地缓存本身是永不过期的,这样即便整个机制崩坏,但是还可以从本地缓存中读取到榜单数据,最多就是本地缓存中的榜单数据迟迟没有更新而已。
当然,两个定时任务的间隔都是可以调整的,前 1000 名这个也是可以调整的,可以根据业务需要来调整。
在这种改造之下,先是解决了 zset 引发的大 key 问题和热点问题,其次是大幅度提高了榜单查询的性能。当然缺点就是榜单的实时性下降了,但是这都是可以接受的。
模拟面试题
你提到要将前 100 同步到所有节点的本地缓存上,怎么做?
你可以参考这个问题:怎么同时更新所有节点上的本地缓存?
我在这里用的方案是定时刷新。也就是每个整分钟(例如说 00:01:00, 00:02:00)每个节点都会查询 Redis,获得最新的 top100 的数据。因为几乎是同时查询 top100,所以大家获得的 top 100 数据都是一样的。
为什么你从数据库中只计算前 1000,而不是 2000 或者 3000?
这实际上就是一个经验值。也就是说根据我的观察,我发现在一段时间内,前 100 名大概率出自前 1000 名,很少有例外,所以选 1000 就够了。当然选 2000,3000 其实问题也不大。
严格来说,只要使用 Redis zset 的时候没有大 key 问题,那么这个数字是可以尽可能大的。但是从业务上来说犯不着,因为排名靠后的那些数据,很难说短时间就变到前 100 了。
为什么你从数据库中取前 1000 是间隔一小时?间隔 30 分钟行不行?
1 小时也是一个经验值。从理论上来说,只要间隔时间大于计算前 1000 的时间就可以了。
而间隔一小时可以保证不会频繁计算,也可以保证榜单的实时性处在一种比较好的状态。