Redis 数据结构:榜单问题之 zset 拆分解决方案
内容
这个案例本质上也是一个榜单案例,它和另外一个榜单案例比起来:Redis 数据结构:榜单问题之本地缓存 + zset + 定时任务方案
- 本案例强调的是 zset 存储大量的数据,实时性更好;
- zset 拆分是 Redis 大key 拆分解决思路的一个具体体现,从技术含量上来说要更高一些;
- 本案例要求 Redis 最好是一个 Cluster;
代码在这里:interview-cases/case21_30/case21 at main · meoying/interview-cases (github.com)
实现思路
整个实现思路很简单,假设我们分 key 之后的 key 形式是 my_biz:%d,假设我们只要榜单前 100:
- 使用 N 个 zset 来存储所有的榜单数据。在我们的代码的例子里面默认是使用 10 个 key;
- 根据业务主键除以分 key 的数量,得到 key 的后缀。例如说 id 为 3,那么它的数据在 my_biz:3 这个 key 对应的 zset 上;
- 定时任务每 1 分钟会从这 N 个 key 里面各取前 100,而后借助归并排序计算全局的前 100。用比喻来说,就好比有 10 个班,我每个班取前 100 名,而后排序再取前 100 名,这 100 名就是全级排名;
- 定时任务会把这 top100 的数据同步到各个节点的本地缓存中
- 查询前 100 会直接命中本地缓存。
如图:
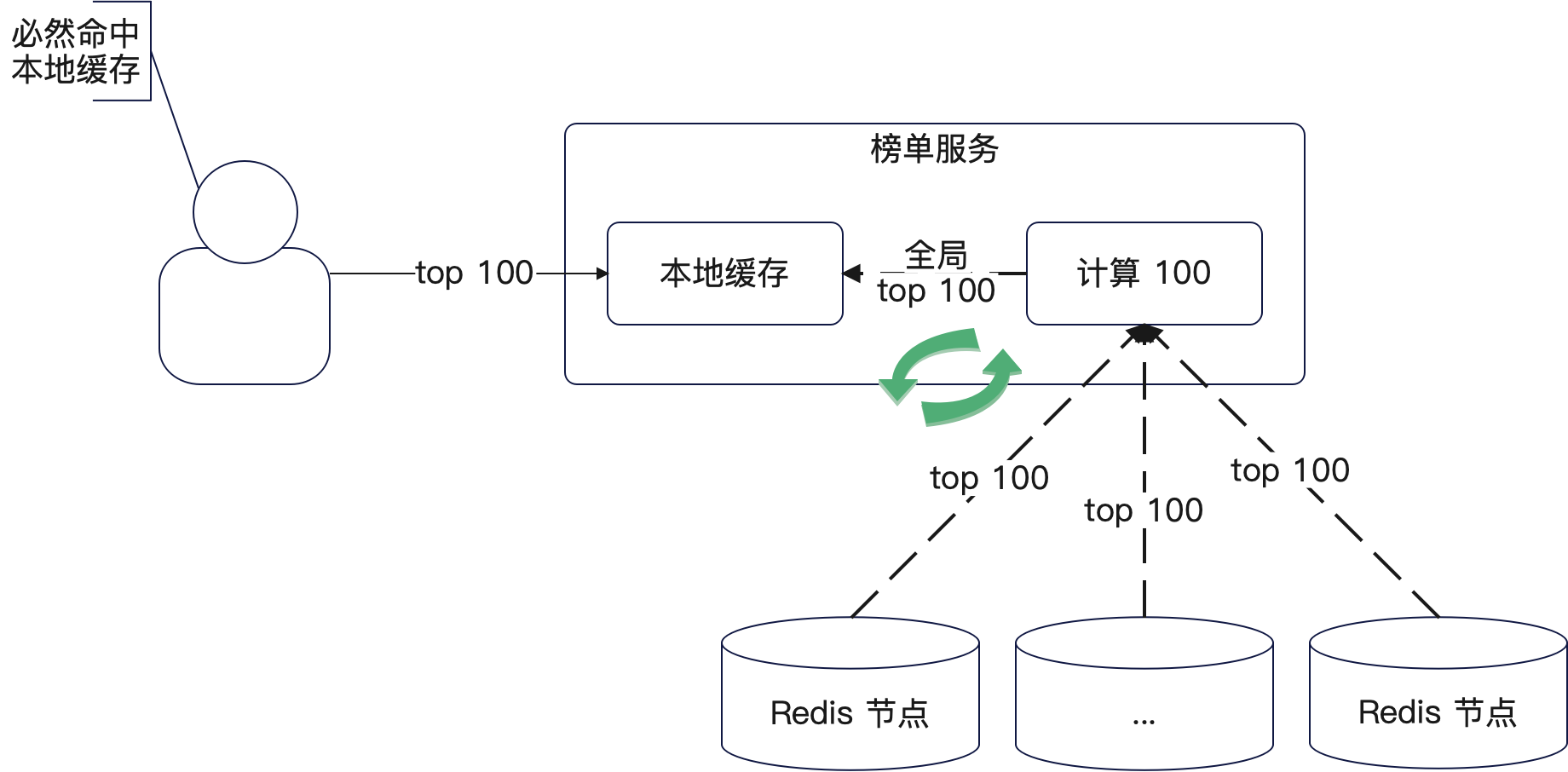
这里有一些细节要注意:
- 在更新的时候要注意顺序问题。举个例子来说,如果针对同一个数据,一个要更新热度为 100,一个要更新热度为 101,你要小心并发问题。最好就是在 ZADD 的命令里面再加上一个 GT 选项;
- zset 并不是真的要存储全部的数据,你可以只存储一部分,这个要业务来判定。比如说业务上说的是计算七天内的榜单数据,例如说只有七天内的文章才可以上榜,那么你的 zset 里面就只需要维护七天内的数据;
- 分 key 有很多种分发。在代码例子中用的是哈希来分 key,但是实际上你可以用日期来分。比如说每天一个 key,这样在只需要七天数据参与排行的情况下,可以等 key 自然过期。例如说设置 key 的过期时间是七天,那么七天之后这个 key 就不在了,你也不需要访问了;
- 从理论上来说,这 10 个 key 应该在经过 CRC16 计算和槽映射之后,应该均匀分散在 Redis Cluster 不同集群上;
- 当新的业务节点上线的时候,再次计算一下全局前 100,而后这个新节点才能对外提供服务;
从性能角度来说,最主要的就是直接命中了本地缓存。
从高可用的角度来说,即便整个 Redis 集群全崩了,也可以靠着本地缓存撑住。
适用场景
通常来说,你在简历里写擅长设计高性能,高可用的缓存方案或者设计过高性能高可用的榜单方案, 就可以用这个案例作为证据。遇到这些问题你就可以用这个案例来回答:
- 你的项目有什么难点?
- 你做过什么令人印象深刻的事情?
- 你觉得你做得最好的点是什么?
如果面试官问到了有关缓存、Redis、Redis zset 这些问题,你也可以使用这个案例
- 你有设计过缓存方案吗?这个方案总的来说还是很强的
- 你用过 zset 吗?
而榜单问题本身就是一个面试热点,所以这个问题也能显著帮到你,换句话来说,只要面试官问你怎么解决排行榜之类的问题,你就可以用这个案例。
可以参考以下话术来使用这个案例,这个案例是站在一个演进的角度来阐述的:
我设计过一个解决大数据、高可用、高性能的榜单方案。一开始我们业务的数据量不是很大,所以直接用了最简单的 Redis zset 来计算榜单。
后面随着业务的发展,计算这个榜单的数据越来越多,并发量越来越高。这个时候,一个 zset 里面要放几百万个数据,存储这个 zset 的 Redis 并发极高,压力极大。并且 zset 中元素数量太多,导致更新的时候越来越慢。
发现这个问题之后,我就综合业务实际情况,设计了一个新的榜单解决方案 —— 拆分 key 的方案。
首先,我根据数据量,将原本单一的 key 拆分成了 10 个key,比如说 my_biz:0, my_biz:1 这种。
其次,key 的后缀是业务 ID 除以 10 的余数,在更新热度可以只更新对应的 key。
第三,启动一个定时任务,这个定时任务会定期从所有的 key 里面各取前 100 名,而后用归并排序计算出来全局的前 100 名。
第四,定时任务还会把计算的结果同步到所有的节点的本地缓存上。
最终业务查询榜单的时候,就直接命中本地缓存,性能极好。
模拟面试题
为什么你这里定时任务间隔是 1 分钟?
这其实是一个经验值,主要是根据产品要求来确定的。如果产品说这个榜单三分钟刷新一次,那么设置为 3 分钟都可以。如果要是产品说实时查询,就不能用定时任务了,只能直接查询 zset。在这种情况下,需要考虑扩大 Redis 集群,不然撑不住高并发。