上
序言
我们都知道,程序的数据一般都打到tcp的segement里,然后打到IP的packet,再到达以太网的frame(帧)
后发送到对端
:::color4
:::
tcp头格式
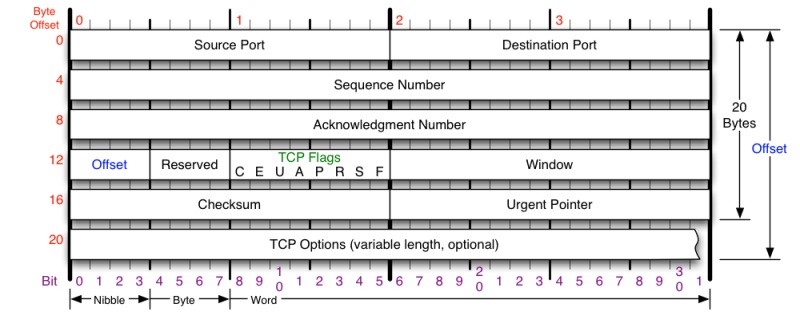
你需要注意这么几个事情
- tcp是没有IP地址的,那是IP层的事情
- tcp需要一个四元组来标明是一个连接(源端口,源IP,目标端口,目标IP)当然还需要一个协议
- 四个重要的东西
1.seq num:包的序号,用来解决乱序问题
2.ack num:用于确认收到,解决不丢包的问题
· 3.window 滑动窗口,用于解决流控
4.tcp flag 主要用来操控tcp的状态机的
tcp状态机
其实,网络上的传输是没有连接的,包括TCP也是一样的。而TCP所谓的“连接”,其实只不过是在通讯的双方维护一个“连接状态”,让它看上去好像有连接一样。所以,TCP的状态变换是非常重要的。
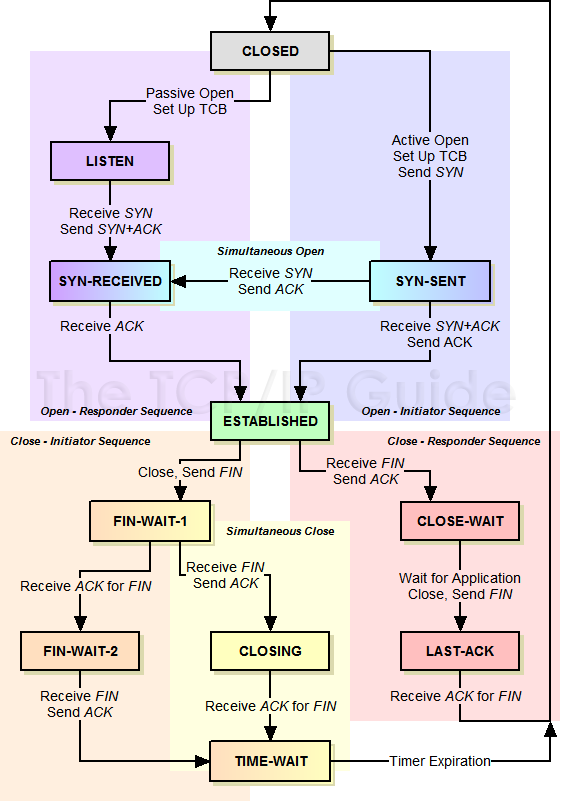

为什么建链接要3次握手?
syn即synchronize sequance number 同步序号么,后序传输数据都会基于这个序号,那么三次的话你来我往
的话才能知根知低
断链接需要4次挥手?
你仔细看其实只有两次,因为tcp是全双工通信,两条通道,所以,发送方和接收方都需要Fin和Ack
只不过,有一方是被动的,所以看上去就成了所谓的4次挥手。如果两边同时断连接,那就会就进入到
CLOSING状态,然后到达TIME_WAIT状态
- 单工通信(Simplex):只能单方向传输,比如电视广播,只能电视台发 → 用户收,用户不能回传。
- 半双工通信(Half Duplex):可以双向传输,但不能同时,要轮流,比如对讲机,“你说完我再说”。
- 全双工通信(Full Duplex):可以双向同时进行,比如电话、现代以太网。
多事
- 建立连接时超时了。Client发出syn后,Server接受到了,发给SYN-ACK后但这时候Client下线了怎么办?
那么这个连接就处于一个中间状态,没成功也没失败。收不到Client的ack一段时间后在Linux下,Server默认会采用一个重试措施,默认重试次数为5次,重试的间隔时间从1s开始每次都翻售,5次的重试时间间隔为1s, 2s, 4s, 8s, 16s,总共31s,而第5次后得等32秒才能停止等待,故总共是63s,这个时候tcp才会断开
- SYN Flood攻击。基于上述情况,就有人利用这种机制,恶意攻击你,发一个syn后,客户端下线,让你的syn连接的队列耗尽(syn队列就是存放那些半连接状态的连接的)。于是,Linux下给了一个叫tcp_syncookies的参数来应对这个事——当SYN队列满了后,TCP会通过源地址端口、目标地址端口和时间戳打造出一个特别的Sequence Number发回去(又叫cookie),如果是攻击者则不会有响应,如果是正常连接,则会把这个 SYN Cookie发回来,然后服务端可以通过cookie建连接(即使你不在SYN队列中)。请注意,请先千万别用tcp_syncookies来处理正常的大负载的连接的情况。因为,synccookies是妥协版的TCP协议,并不严谨。对于正常的请求,你应该调整三个TCP参数可供你选择,第一个是:tcp_synack_retries 可以用他来减少重试次数;第二个是:tcp_max_syn_backlog,可以增大SYN连接数;第三个是:tcp_abort_on_overflow 处理不过来干脆就直接拒绝连接了。
- 关于Inital Sequence Number。并不是所有syn 的起始值都是一样的。如果是的话,那就乱套了。那是跟一个假时钟绑定的,每四微妙++,直到2的32次方,然后归0。这样,一个ISN的周期大约是4.55个小时。因为,我们假设我们的TCP Segment在网络上的存活时间不会超过Maximum Segment Lifetime(缩写为MSL – Wikipedia语条),所以,只要MSL的值小于4.55小时,那么,我们就不会重用到ISN,也就不会出错
- 关于 MSL 和 TIME_WAIT。为什么关闭连接的时候要有Time_wait?而不是直接关闭?这主要是保证对端能接受到我这边发的ack,如果被动关闭的那方没有收到Ack,就会触发被动端重发Fin,一来一去正好2个MSL,2)以及有足够的时间让这个连接不会跟后面的连接混在一起(你要知道,有些自做主张的路由器会缓存IP数据包,如果连接被重用了,那么这些延迟收到的包就有可能会跟新连接混在一起)
- 关于TIME_WAIT数量太多。这在主要体现在有大量短连接请求下(比如http1/2)。timewait太多是会占据掉大部分资源的。但你去网上搜相关教程,太多都会去教你去调两参数 tcp_tw_reuse,tcp_tw_recycle。这两个参数默认都是关闭的,两个参数涉及到的机制都比较激进。
- 关于tcp_tw_reuse,tcp_tw_recycle,tcp_max_tw_buckets(对抗DDoS攻击的)参数

tcp_tw_resuse,tcp_tw_recycle因为这两个参数违反了TCP协议。
在 Linux 4.12 版本后被彻底移除

其实,TIME_WAIT表示的是你主动断连接,所以,这就是所谓的“不作死不会死”。试想,如果让对端断连接,那么这个破问题就是对方的了,呵呵。另外,如果你的服务器是于HTTP服务器,那么设置一个HTTP的KeepAlive有多重要(浏览器会重用一个TCP连接来处理多个HTTP请求),然后让客户端去断链接(你要小心,浏览器可能会非常贪婪,他们不到万不得已不会主动断连接)。


数据传输中的seq num

SeqNum的增加是和传输的字节数相关
上图中,三次握手后,来了两个Len:1440的包,而第二个包的SeqNum就成了1441。然后第一个ACK回的是
1441,表示第一个1440收到了。
tcp重传机制
tcp要保证包都到达接收方,就得有重传机制
接收端给发送端的Ack确认只会确认最后一个连续的包,即遵循累计确认原则
PS:ack = seq + 1
接收端收到了1 2 可以 回ack = 3
但接收端收到了1 2 4 这时候就不可以回 ack = 5。会再次发送 ack = 3
这时候发送端就知道得重传seq = 3的包
不这样的话,发送端就会以为之前的包都收到了
1. 累积确认是什么?
“接收端给发送端的 Ack 确认只会确认**最后一个连续的包”这句话解释了累积确认的精髓。**
*在 TCP 中,接收端发回的 ACK 报文(确认号)不是用来确认单个数据包,而是用来告诉发送端:“我收到了到这个序号为止的所有数据,你下次可以从这个序号开始发了。”*
- 例子:
- 发送端发送了数据包 1、2、3、4、5。
- 接收端收到了 1 和 2。
- 接收端会发送一个 ACK 报文,其确认号为 3。这表明它成功收到了序号 1 和 2 的数据,并期望收到序号为 3 的数据。
2. “收到了 4(注意此时 3 没收到),此时的 TCP 会怎么办?”
这是一个非常好的问题,它展示了 TCP 的乱序处理能力。
- 接收端行为:
- 收到数据包 1 和 2 后,它会发送 ACK 3。
- 接着收到了数据包 4。因为它没有收到 3,所以 4 是一个乱序的数据包。
- 此时,接收端不能发送 ACK 5(因为 3 没收到,确认不连续),它会**再次发送 ACK 3。**
- 发送端行为:
- 发送端一开始发送了 1、2、3、4、5。
- 它收到了接收端发来的 ACK 3。这表示 1 和 2 已经到达,它可以继续发送更多数据了。
- 但是,发送端很快又收到了**重复的 ACK 3。当它收到多个(通常是 3 个)重复的 ACK 报文时,它就知道序号为 3 的数据包很可能丢失了。**
- 这时,TCP 会触发快速重传(Fast Retransmit)机制,立即重新发送数据包 3,而不需要等到超时后才重传。
超时重传机制
一种是如果发送方死等不回来 ack = 3。那么这时候就会触发超时重传,一旦接收方收到seq3,就会回ack=4
那么发送方就知道3和4都收到了
但是这种方式也有比较严重的问题,因为你要死等3,那么4,5的状态其实是不得知的。这时候tcp可能就会悲观
地认为它们都需要重传
对此有两种选择
1.只重传Timeout的包,即 3
2.重传timeout后的所有包,即 3 4 5
两种说好不好,第一种节省带宽,但费时,第二种可能会做无用工,两者都在等Timeout。PS:这个timeout
是tcp动态计算出来的
快速重传机制
为了解决timeout的问题,tcp就引入了一种快速重传算法,不以时间驱动,而是以数据驱动
也就是说如果包没有连续到达的话,就ack那个最后有可能丢失的包。如果发送发接受到了三次相同的ack,
就重传这个包。快速重传的好处就是 不用等待超时
比如:如果发送方发出了1,2,3,4,5份数据,第一份先到送了,于是就ack回2,结果2因为某些原因没收到,3到达了,于是还是ack回2,后面的4和5都到了,但是还是ack回2,因为2还是没有收到,于是发送端收到了三个ack=2的确认,知道了2还没有到,于是就马上重转2。然后,接收端收到了2,此时因为3,4,5都收到了,于是ack回6。示意图如下:
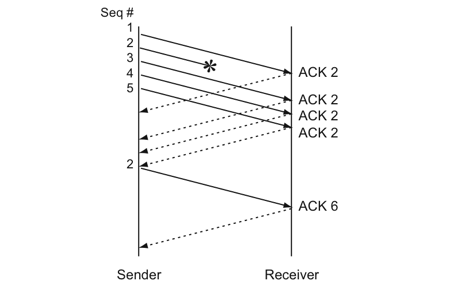
Fast Retransmit只解决了一个问题,就是timeout的问题,它依然面临一个艰难的选择,就是,是重传之前的一个还是重传所有的问题。对于上面的示例来说,是重传#2呢还是重传#2,#3,#4,#5呢?因为发送端并不清楚这连续的3个ack(2)是谁传回来的?也许发送端发了20份数据,是#6,#10,#20传来的呢。这样,发送端很有可能要重传从2到20的这堆数据(这就是某些TCP的实际的实现)。可见,这是一把双刃剑。
还是有弊端,就是发送发不清楚,后两次是谁发的,如果丢的不止一个包呢。
SACK机制
还有更好的方式,SACK
Selective Acknowledgment
这个需要再tcp头里添加一个字段,用来记录 收到的不连续包块
比如发送端只收到了 1 2 4 5 7 8 10

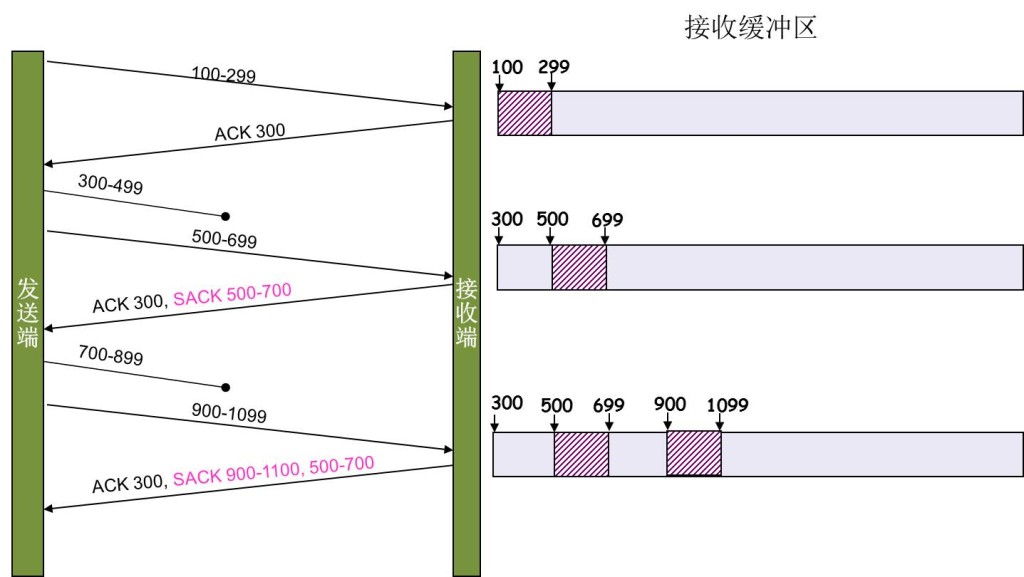
这样的话,发送端就知道哪些没到,哪些到了,那么这样就可以准确地重传那些没到了
当然这个协议需要两边都支持,在 Linux下,可以通过tcp_sack参数打开这个功能(Linux 2.4后默认打开)。
当这还是有问题,即接收方有权把已经报给发送端SACK里的数据给丢了,比如内存不够用了
所以,发送方也不能完全依赖SACK,还是要依赖ACK,并维护Time-Out,如果后续的ACK没有增长,那么还是要把SACK的东西重传,另外,接收端这边永远不能把SACK的包标记为Ack。
而且维护SACK是会耗发送发资源的,如果一个攻击者发送给发送方很多这种SACK,让发送方重发一堆东西
Duplicate SACK – 重复收到数据的问题
其主要使用了SACK来告诉发送方有哪些数据被重复接收了