AOF 和 RDB
Redis 3.0
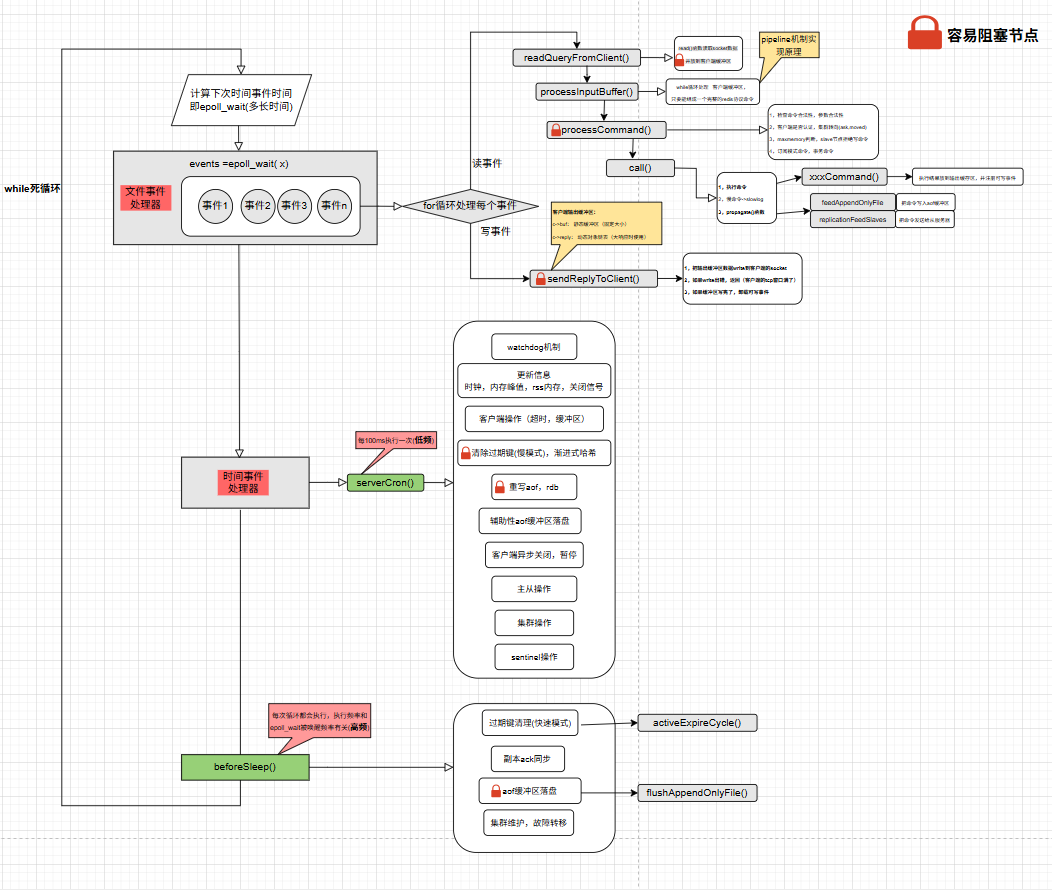
由上图可以看到,Redis从整体来看其实就是一个while死循环
1 | while(true){ |
aof和rdb调用关系
1 | // 客户端的命令 |
aof
aof包含刷盘和重写两大块
aof 流程及刷盘
每执行一个redis写命令,会存到aof缓冲区。然后在文件事件结束后,依赖** beforeSleep()** 函数执行写入动作。
写命令 -> aof 缓冲区 -> write数据 -> 刷盘策略
flushAppendOnlyFile() 函数被 beforeSleep() 函数高频调用,每次调用都会调用 write函数(主线程执行),然后根据策略刷盘。
aof_fsync 的含义,每次都会调用write函数,但是刷盘时机可以配置
always 模式,也可能丢失数据,而且高频的调用 aof_fsync 会导致redis吞吐量下降。
PS:为什么高频调用会导致Redis,因为always模式下flush是在主线程,而不是跟everysec一样是异步线程
everysec 模式下,数据丢失风险 不止1秒!若刷盘上次刷盘不及时,或者文件事件执行过长(高并发时,且有阻塞性的大key导致)
no 依赖操作系统刷盘
思考:如果设置的刷盘策略为每秒,为什么write数据还是在主线程,而刷盘在异步线程。为什么不把write也放到异步线程呢?
:::color4
1.write是轻量级的,就是将用户态的数据拷贝到page cache,而flush需要等到IO事件结束,耗时长,更适合异步化
2.write的时候涉及 aof_buf,如果是异步的话,在多线程情况下,就需要引入锁机制
:::
重写aof流程
为什么
手动
自动重写aof时机
:::color4
此时没有进行rdb和重写aof(判断是否存在子进程)
aof当前体积 > 最小重写阈值
配置了自动重写百分比,且现在的体积 较于上次aof体积 增长率 大于 配置的值
:::
aof重写逻辑流程
:::color4
- fork 一个子进程 ,记录fork子进程时间,关闭字典rehash
子进程:
1.关闭网络连接
2.创建临时文件名 tempfile = temp-rewriteaof-bg-%d.aof**** ,这里就是相当于在内存里创建了一个字符串
3.创建临时文件temp-rewriteaof-%d.aof
4.遍历所有db,写入键值对以及过期信息
5.temp-rewriteaof-%d aof 原子改名为 temp-rewriteaof-bg-%d.aof
6.unlink temp0-rewriteaof-%d.aof
//unlink:删除文件名 file1.txt。 将 inode 的链接计数器减 1,变为 1。
7.向父进程发送退出信号
- 在n个循环后子进程执行完毕,打开temp-rewrite-bg-%d aof
- 遍历aof重写缓冲区,数据追加到 temp-rewrite-bg-%d.aof
- 打开appendonl.aof,temp-rewrite-bg-%d.aof 改名为 appendonly.aof
- 更新Server aof_filename 等于tmpfile的 fd引用,并刷盘
- 异步关闭旧的aof文件fd
:::
伪代码:
if(xxx = fork() == 0){
}
else{
//关闭网络连接
}
整个过程中会有三个文件
appendonly.aof
temp-rewrite-bg-%d aof
temp-rewrite-%d aof
Redis异步线程
rewriteAppendOnlyFileBackground() -> bioCreateBackgroundJob()
redis3.0 使用异步线程的地方:
1,异步刷盘( fsync)
2,重写aof时,异步关闭文件
| 版本 | 关键异步任务 | 技术实现 | 演进意义 |
|---|---|---|---|
| Redis 3.0 | AOF持久化(fsync) | bioCreateBackgroundJob创建后台线程 | 首次引入多线程,解决fsync阻塞主线程问题 |
| Redis 4.0 | 大Key异步删除、数据库清空(UNLINK/FLUSHDB ASYNC) | 独立BIO线程池(3个线程:关闭文件、AOF刷盘、惰性删除) | 主线程与耗时操作解耦,提升稳定性 |
| Redis 6.0 | 网络I/O读写、协议解析 | I/O线程组(可配置数量) | 网络吞吐提升300%,单节点性能突破20W QPS |
| Redis 7.0 | RDB生成、AOF重写、集群任务分发 | 动态线程池(负载自适应) | 优化后台任务并行性,减少尾延迟65% |
| Redis 7.4+ | 哈希字段过期、向量数据处理(AI优化) | 字段级异步过期线程 |
rdb流程
自动处理的默认配置
save xx xx
save xx xx
save xx xx
只要满足了以上一个就触发
1,记录开始的时间,fork子进程
子进程:
1,关闭网络fd
2,创建临时文件 temp-%d.rdb
3,遍历16个db的所有数据,写入到临时文件,刷盘并关闭fd
4,把临时文件重命名为dump.rdb
5,向父进程发送信号
2,计算fork所花时间,记录子进程id,关闭自动rehash
3,在n个循环后,收到子进程信号,更新一些信息
4,处理正在等待 BGSAVE 完成的那些 slave
cow 和 fork
cow内存计算逻辑
1个g,fork子进程之后 子进程和父进程同一块物理内存,总内存还是一个g,父进程还会写
1g内存
–> fork 子进程后,因为共享
还是1g内存
–> 父进程修改一遍 全部内存后 父进程持有1g内存
–> 子进程修改一遍 全部内存后 子进程持有1g内存
1 + 1 + 1=3?
但好像不是

共享内存都很小了
fork的内存计算问题
fork阻塞问题
主进程fork子进程本身也是有延迟的。父进程fork 超过5g内存,会有一定延迟,超过200ms
fork性能问题堪忧
很好奇一点,fork对开源redis可以说是阿喀琉斯之踵了,我看antirez在twitter上也说尽可能的利用sharding来规避这个问题。
从技术上真的没办法解决fork的影响吗?
2020-12-24
其实解决fork影响是os内核要做的,甚至os内核认为这点影响是理所当然,在它看来未必要做啥优化。
而使用者是应该认识到并避免它的。Redis之所以无法避免,还是因为它本身是个缓存,又想做持久化。
2020-12-24