Kafka的生产数据的流程 ?ACK应答机制 ?
早期kafka集群是由zk来保证,我们公司也是,后面kafka更新了,不需要zk了
早期版本:Consumer靠zk来保存offset,而producer不与zk打交道
生产数据的流程
早期版本:
1. producer需要找到集群,并把那个数据放到某个分区中。而这个leader端口号和分区存在zk中,集群和zk一直处于连接状态,partition的leader端口号回由集群去拿出,然后producer会向集群拿到topic对应的partition以及partition的leader信息
2. <font style="color:rgb(85, 85, 85);background-color:rgb(253, 253, 253);">当Producer通过Sender从集群获取到partition和Leader信息,若</font>**<font style="color:rgb(85, 85, 85);background-color:rgb(253, 253, 253);">有指定partition则使用指定的partition</font>**<font style="color:rgb(85, 85, 85);background-color:rgb(253, 253, 253);">,若没有则使用分区算法对key做操作;当没有key则轮询partition;</font>
3. producer会先把数据存入DQ中,每一个partition一个DQ,就是一种消息聚合的方式,sender会轮询,队列满了或者到达一定的时间周期,就会发送给leader。
Producer给Leader发数据使用批处理,如果没有批处理每次发送都建立连接在进程间做交互,会使效率很低
4. leader将数据写入本地的log日志分段
5. 后续Consumer轮询从broker拉取消息,Kafka的ACK应答机制(producer,三种,0,1,2 );
三种ACK模式:
当取值为0,则不关心是否到达,尽最大努力交付,效率高,数据可能丢失;
取值为1(默认),Producer的发送数据,需要等待Leader的应答才能发生下一条,不关心Follower是否接收成功,性能稍慢,数据较安全,但当Leader突然宕机,则当Follower还未同步,数据会丢失;
取值为 -1(all) ,Producer发送数据,需要等待ISR内的所有副本(leader和所有Follower)都完成备份,最安全,性能差;需要等待follower一定时间后拉取数据,也就是这个”一定时间”是其效率的主要影响
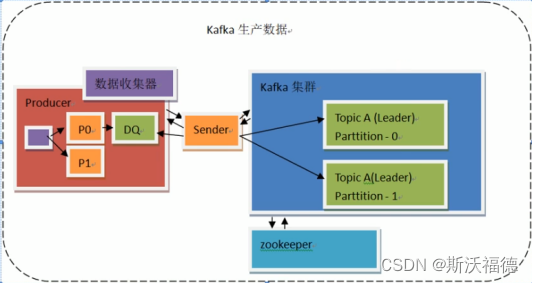详细流程
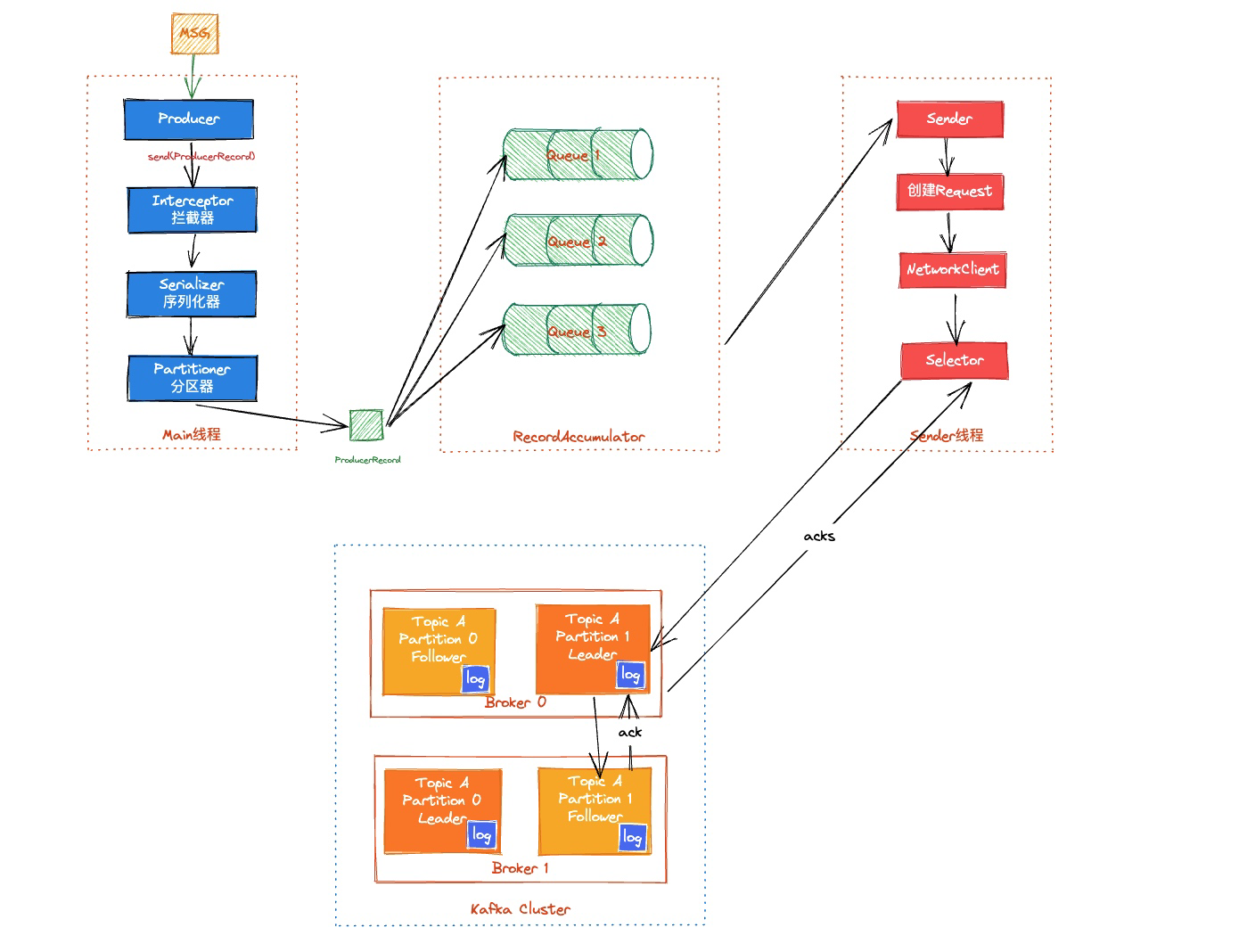
sender方法: