Kafka为什么读写效率高(高吞吐) ?
首先kafka是分布式集群,吞吐量大。天生分布式,随便加机器
零拷贝
这里的零拷贝是对于应用层而言
我们要将磁盘的数据发送到远端的服务器去,一般的应用做法是
0.调用系统函数read,切换为内核态
1.先将数据从磁盘拷贝到page cache
2.然后切换到**用户态,**将数据拷贝到应用层
3.切换为内核态,调用write,将数据写入page cache
4.最后将page cache 拷贝到网卡 缓冲区
5.切换为用户态,继续程序的运行
这其中需要经过四次拷贝,四次用户内核态切换
而对于sendFile的零拷贝
**数据不需要再拷贝到应用层,而是由内核态全程负责,让数据从磁盘拷贝到内核缓存,然后直接发给NIC **
网卡缓冲区,且用户态内核态也只需要切换两次
PS:DMA
顺序写磁盘
page cache预热
写page cache
分段日志
Leader将文件切分为多个segement,好处就是让 IO更快
Topic→partition→segment
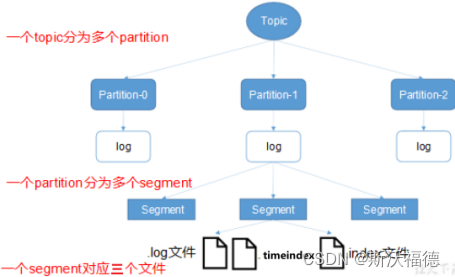
index、log以当前segement的第一条消息的offset命名,以便可以快速查找
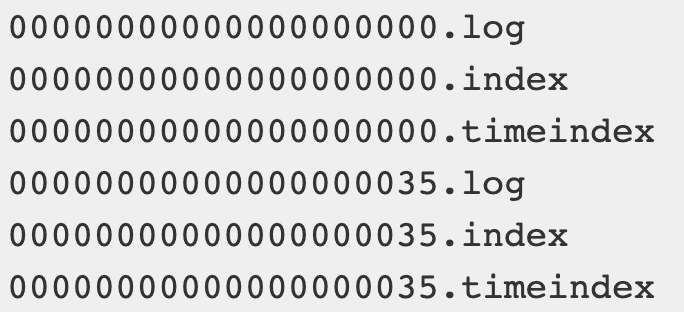
log里面存的是消息,而index里存的是offset和其对应的 物理偏移

Kafka消息(存储)格式及索引组织方式 - 杭州.Mark - 博客园
双端队列与批处理
在producer这边,每一个partition在其producer都会对应着一个DQ
1.producer发送数据时都会往这个DQ里存消息
2.DQ满了或者一定的时间周期到了,producer就会拿出里面的消息,send到broker的Leader里。这即满足了
partition里消息的有序性,还提高了效率性
但消息聚合会降低一定的实时性
而Consumer这边也是一样,先拉取一批数据到本地的DQ里,然后消费
压缩:给的字符串,会被压缩成byte数组,压缩后数据小,传输快