架构
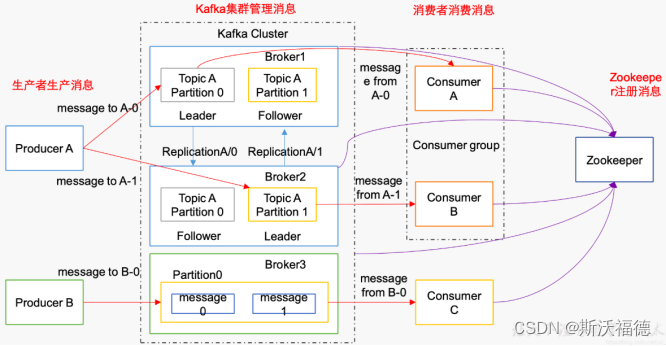
Kafka集群的目的是保存消息,Producers往Brokers里面的指定Topic中写消息,Consumers从Brokers里面拉去指定Topic的消息,生产者把数据以K、V的方式传给集群;
首先Kafka需要多台机器组成一个Kafka集群才能承载负荷,每一台服务器是一个Broker,
数据有多种进行分类 → 一个Broker中有Topic主题
为了提高负载 → 一个Topic有多个partition分区,一个partition可以放在多个不同的Broker上,而数据放在不同的partition当中(取模的方式),可以让不同的消费者来消费,提高消费速率
为了防止数据丢失 → 每个分区下有多个副本,即Leader和Follower,Leader做io处理,Follower只作备份,多个分区进行“交叉备份”,Follower从Leader中实时同步数据,当Leader挂掉后,Follower会代替Leader。
以【消费者组】为单位进行读取数据,其中一个消费者读取一个partition分区,所以一般partition分区数量=消费者组中的Consumer消费者数量,以保证分区内数据有序;
Zookeeper:kafka集群依赖zookeeper来保存集群的的元信息,来保证系统的可用性。
Kafka -> Broker -> Topic -> partition -> Replication(Leader、Follower) ->Consumer
1)Producer :消息生产者,就是向 kafka broker中的Topic主题发消息的客户端;
2)Consumer :消息消费者,向 kafka broker中的Topic中 取消息的客户端;
3)Consumer Group (CG):消费者组,由多个 consumer 组成。消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费;消费者组之间互不影响。 所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
4)Broker :一台 kafka 服务器就是一个 broker。一个集群由多个 broker 组成。 一个 broker可以容纳多个topic。
5)Topic :可以理解为一个队列,生产者和消费者面向的都是一个 topic;topic逻辑上的概念,partition是物理上的概念;
6)Partition:为了实现扩展性,一个非常大的 topic 可以分布到多个broker(即服务器)上,一个 topic 可以分为多个 partition,每个 partition 是一个有序的队列;partition中的每条消息都会被分配一个有序的id(offset)
7)Replica:副本,为保证集群中的某个节点发生故障时,该节点上的 partition 数据不丢失,
且kafka 仍然能够继续工作,kafka 提供了副本机制,一个 topic 的每个分区都有若干个副本,一个 leader 和若干个 follower。
8)leader:每个分区多个副本的“主”,生产者发送数据的对象,以及消费者消费数据的对象都是 leader。
9)follower:每个分区多个副本中的“从”,实时从 leader 中同步数据,保持和 leader 数据的同步。leader 发生故障时,某个 follower 会成为新的 follower。
10)Offset:偏移量, kafka的存储文件都是按照offset.kafka来命名,用offset做名字的好处是方便查找。例如你想找位于2049的位置,只要找到2048.kafka的文件即可。
当然the first offset就是00000000000.kafka。