幂等性设计
幂等性:一次和多次请求某一个资源应该具有同样的副作用
为什么会有幂等性问题?上游重试导致的,下游得做好幂等
幂等分为请求幂等和业务幂等,业务幂等是人为定义的,这种东西没有讨论性
全局ID
ID由谁来分配是个问题?
分配中心?那么每一次交易都需要找那个中心系统来。 这样增加了程序的性能开销。还是上游?上游的话就可能出来重复ID,因为它一般是个集群,每台机器都承担相同的功能
还有就是我们需要一些不冲突的算法
UUID,是个字符串,占用空间大,索引的效率非常低,生成的 ID 太过于随机,完全不是人读的,而且
没有递增,如果要按前后顺序排序的话,基本不可能
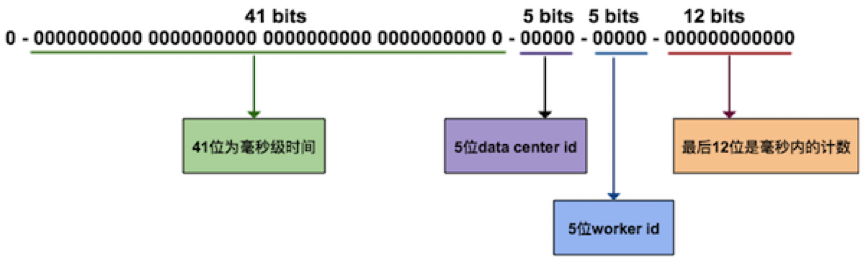
雪花算法的生成原理,生成的东西是一个 long类型的数
41bit 为毫秒数
5bit为数组中心ID(需用用户配置)
5bit为机器ID(需要用户配置)
12bits 作为毫秒内的序列号。一毫秒可以生成 4096 个序号。
1 | import cn.hutool.core.lang.Snowflake; |
幂等性处理流程
一锁二判三通过
or 通过mysql 的 insert,update,但其实归结到底它其实还是 一锁二判三通过,因为update会做上行锁
但我们希望我们有一个标准的方式来做这个事,所以,最好还是用一个 ID。
因为我们的幂等性服务也是分布式的,所以,需要这个存储也是共享的。这样每个服务就变成没有状态
的了。但是,这个存储就成了一个非常关键的依赖,其扩展性和可用性也成了非常关键的指标。
HTTP 的幂等性
幂等:get,head,delete,put(创建or更新,URL是一样,故为幂等)
不幂等:post
防止表单提交重复性做法
1.表单提交时提交一个Token,这个Token可以是前端生成好携带过来的,然后做下校验Token是否之前就存
在了。用于防止用户多次点击了表单提交按钮,而导致后端收到了多次请求,却不能分辨是否是重复的
提交。我觉得这应该是产品设计
2.前端按钮做好置灰
3.更稳妥的做法是,后端成功后向前端返回302状态码跳转,把用户的post请求变成get请求,把刚才post的
东西展示出来。如果是web的话,就把刚才的提交页面置为过期,防止回退,这种模式叫做PRG模式