kafka为什么这么快
说他快,一般是说能高效地移动大数据,类似于管道,即高高吞吐量
两个点
1.顺序磁盘IO
写的是磁盘,kafka是不会写内存的。
kafka的每个partition其实就是一个文件,而topic其实是一个文件夹的名字,写数据都会写到每个partition的末尾
但这种方式有个缺点,就是没法删数据,kafka的所有数据都会保留下来,每个consumer对于同一个topic都会有一个offset去记录当前consumer读到了哪里
而这个offset是客户端SDK保存的,broker无感知
kafka提供了两种删除策略,一种是根据时间,一种是根据partition文件大小
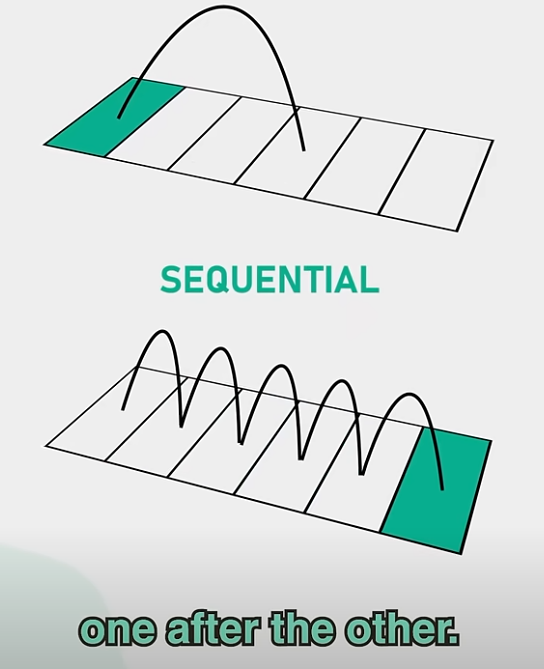
2.零拷贝技术
常规拷贝
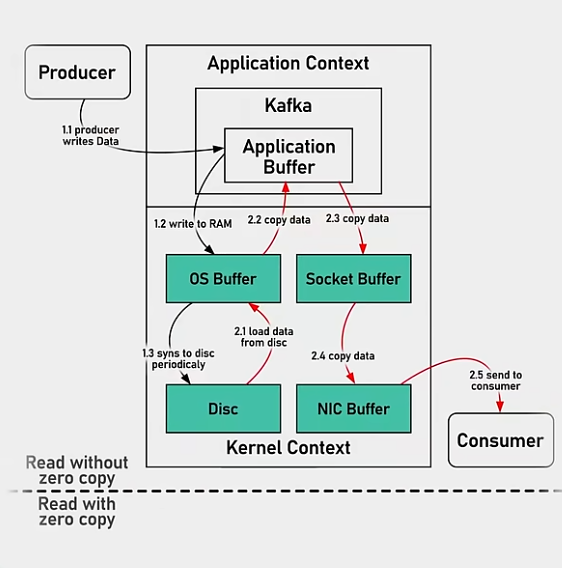
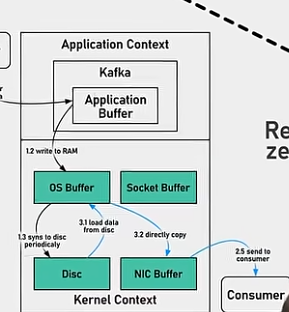
零拷贝,通过send file命令直接告诉cpu直接从os buffer里拷贝数据
3.从消息的角度来说,kafka用的是堆外内存,无GC,消息写入的是page cache 对于Linux来说,然后直接落盘
4.自动预热


怎么预热:从日志回放 用户的请求。
kafka会在预热的时候把队列里的消息加载到page cache里,但也怕启动的时候因为预热而变慢,这都是有参数配置的
5.分布式架构
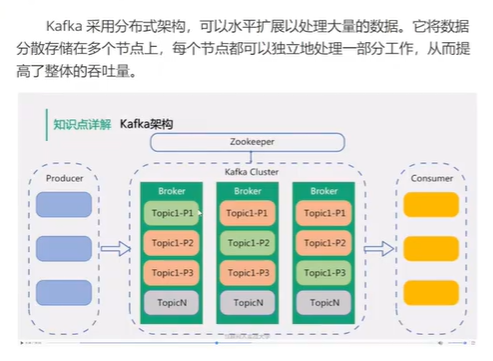
分布式做得好的话,性能不好就加机器呗,无非就是成本问题
6.应用层面的优化
消息压缩,kafka支持gzip 或者 Snappy格式对消息进行压缩,减少网络传输的压力
批次写入,即聚合发送
假设网络带宽为10MB/S,一次性传输10MB的消息比传输1KB的消息10000万次显然要快得多。
为啥要用Java写?
最开始,应该是考虑多平台,内存安全等因素。当然也可能有跟着hadoop随大流走Java的成分。 但是实际上kfk已经有c++版本了。可以获得更好吞吐。那个应该是叫redpanda. 不过,由于go极大刺激了java社区,java社区正在奋力追赶相关特性。分代zgc,虚拟线程,堆外内存API,SIMD等特性基本都追齐了。下一个jdk lts应该就可以全部发布了。 对于目前兴起的用c go等重写中间件的行为,我建议我们可以进入观望期。再看看java的发展与社区的进度。实际上大量的中间件社区已经全面抛弃java8了,升级是大势所趋。