caffeine
基本使用
1 |
|
缺点
用本地需要考虑的点
- 功能能满足,get,put,过期
- 不能OOM,内存管理
- 监控展示(肯定不能是黑盒,无提示性语句)
- 统计(热key,大key,命中率 ….)
caffeine的缺点
- 功能基本满足,但多个业务场景,多种过期时间,不满足
- 只有key个数上限(不设置默认是)无法设置使用内存上限
解决:
- 给不同kv设置不同的过期时间
:::info
其实是有的,只是隐藏得比较深
// 可变过期时间策略没有提供,如果有,那就put。如果不可变那什么都没有
cache.policy().expireVariably().ifPresent( policy -> { policy.put( xx,xx,xx,xx ) })
:::
- 可以给内存设置上限
源码
build()
BoundedLocalManualCache 和 NoBoundedLocalManualCache
1 | BoundedLocalManualCache(Caffeine<K, V> builder, CacheLoader<? super K, V> loader) { |
1 | build: |
put
底层其实就是一个data:ConcurrentHashMap
put -> data -> writeBuffer.offer(全局有界队列)
1 | // 方法作用:将键值对放入缓存,如果键已存在则覆盖旧值(除非onlyIfAbsent为true) |
data.put(keyRef,node)
writeBuffer.offer(task);
schedule
end
//写入writeBuffer
1 | void afterWrite(Runnable task) { |
maintenance
1 |
|
若:writeBuffer满了,offer return false。异步任务处理不过来,循环完成后,会主动同步调其maintance(这时候put就会被阻塞,其实是同步的,也是一种保护措施,因为写太多,会OOM,阻塞也会去减慢写的速度):就会去消费Buffer,节点过期,节点淘汰。如果非常爆炸性的put的画,性能就不是很好了
读多写少用的才是本地缓存
get
get -> data -> readBuffer.offer(每个线程一个队列,减少了竞争)
异步任务
会被包装成PerformCleanUpTask它其实是一个Runnable,然后丢到线程池去执行
1 |
|
内存管理,(淘汰策略:key上限),W-TinyLFU
像内存管理,我肯定是有内存的数据才能进行管理,而像这些数据我肯定是不能在put or get 的主线程去做的,有些内存组件其实就是这么去做的,所以性能才差
writeBuffer和readBuffer的作用:就是把统计操作和读写操作分离了(一定情况下),两者不会相互影响
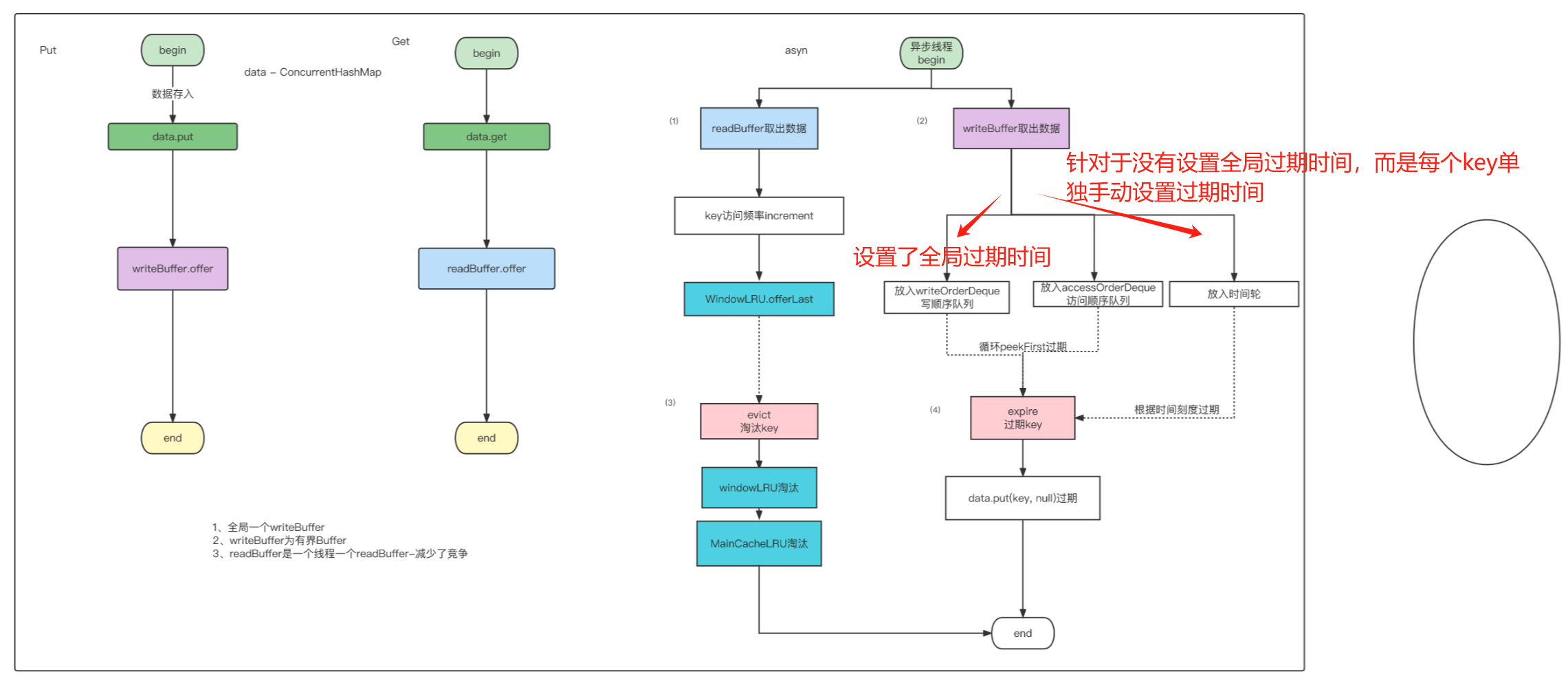
内存模型:
过期策略
- 全局统一key一个过期时间
1 | void expireAfterWriteEntries(long now) { |
- 每个key单独一个过期时间
使用的是时间轮算法,时间轮算法过期
1 | void expireVariableEntries(long now) { |
时间轮:本质其实就是 数组 + 链表
定时器tick从时间轮里取任务时,整体时间复杂度可以为O(1);
包括put也是
而像Linux的双层时间轮,在次基础上还优化了。采用了双层时间轮,支持高延迟,其设计思想类似于分针和秒针
【层1:秒轮(快速轮)】
slot0 slot1 slot2 … slot59【层2:分轮(慢速轮)】
slot0 slot1 … slot59Tick 推进时:
- 秒轮每走一格
- 秒轮走满一圈 → 分轮前进一步,并将该分轮槽内的任务下沉到秒轮对应槽

淘汰策略:W-TinyLFU
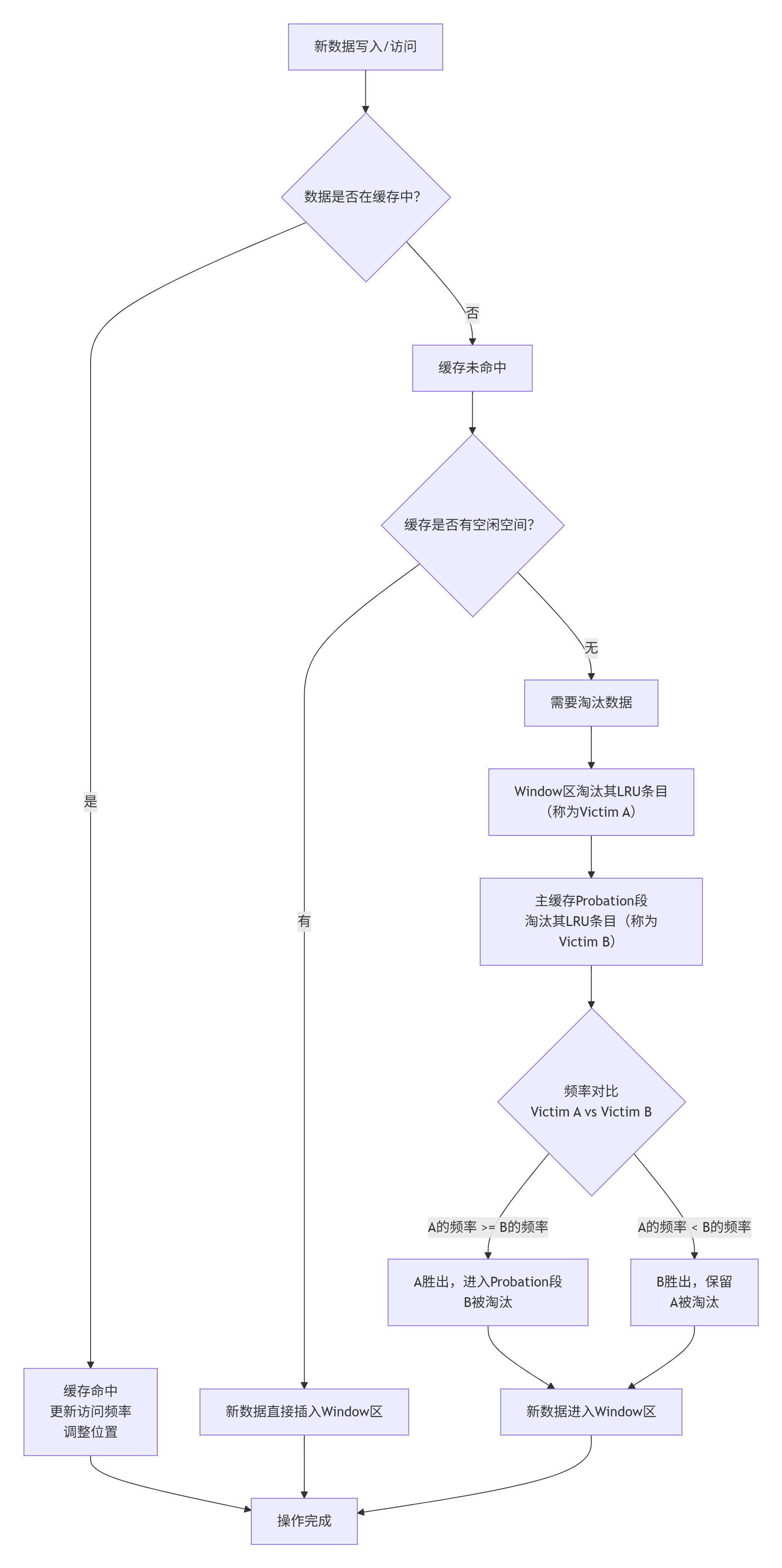
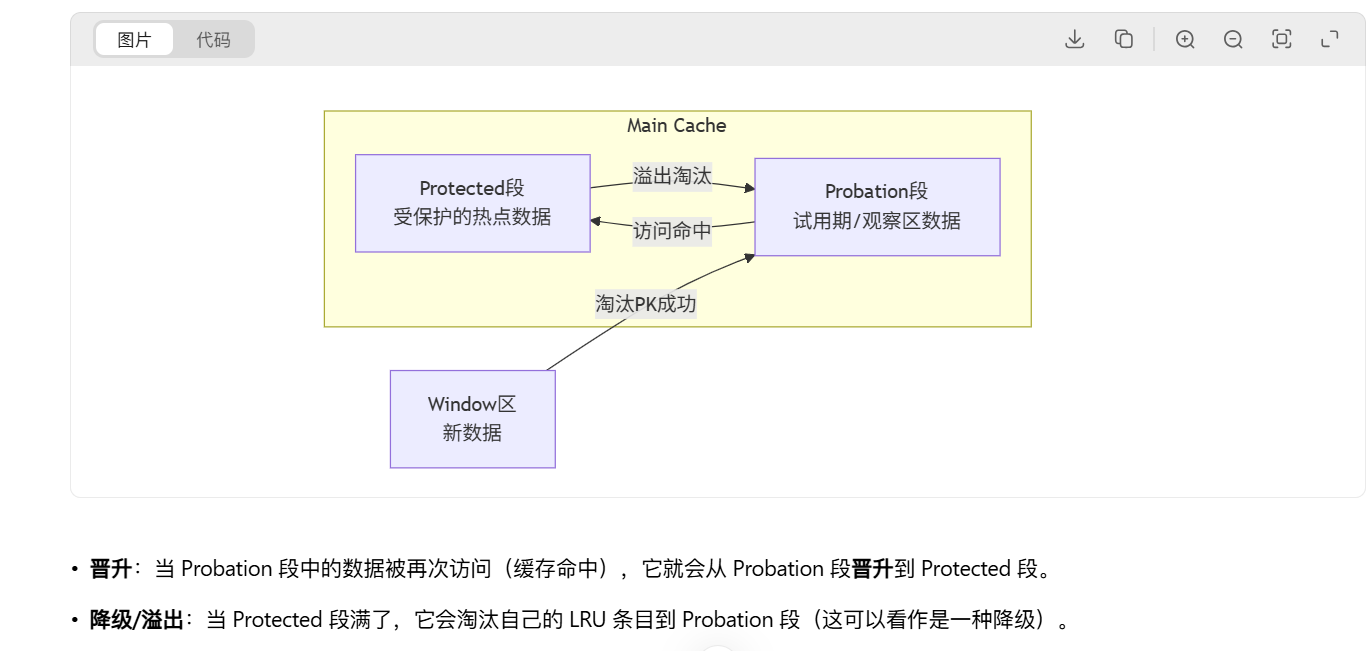
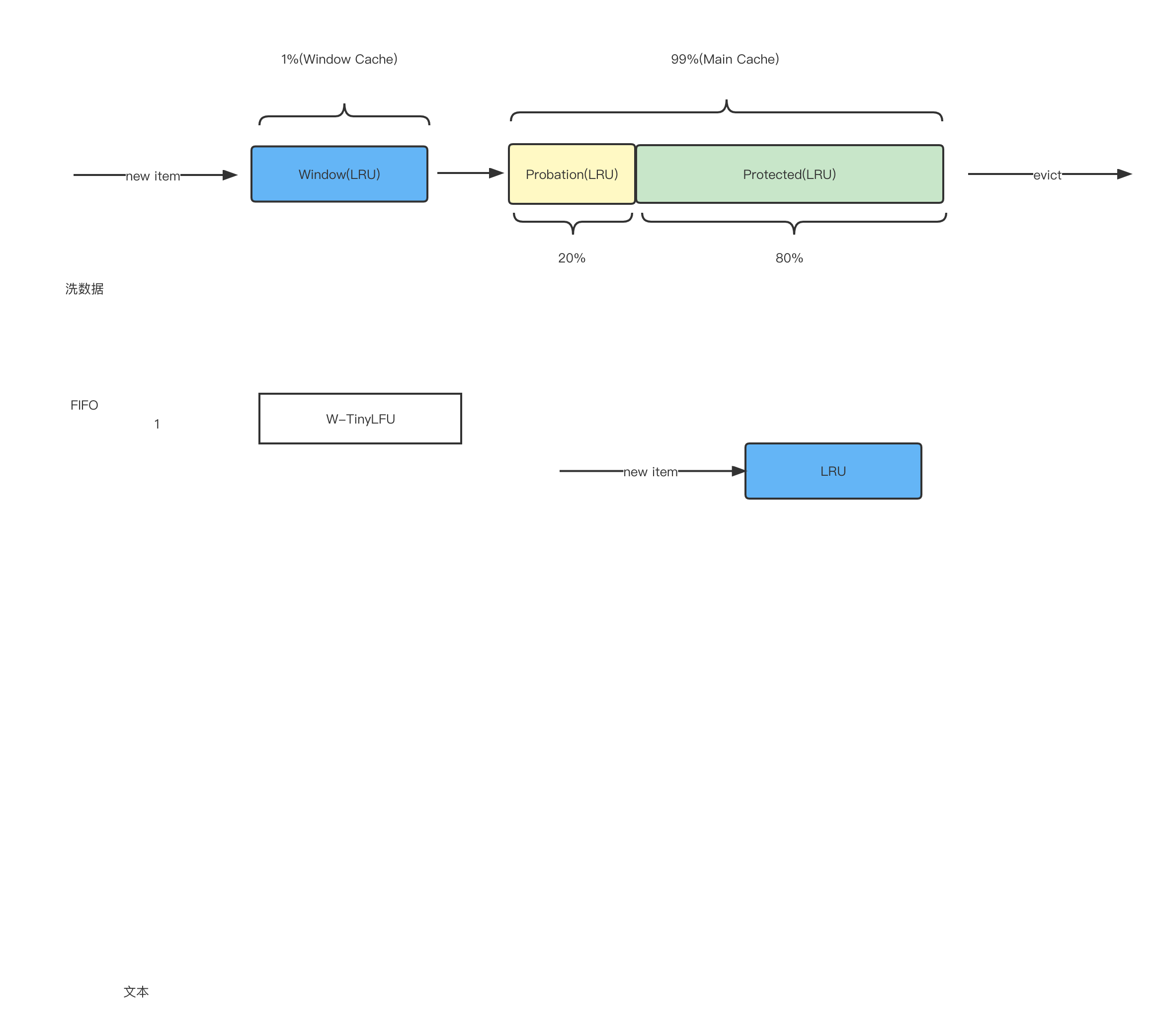
思想大体就是我觉得就很像jvm的那种分代思想。像这个W-TinyLFU算法,它的话就是把内存总的分成了两端,一个main cache,一个是windows Cache,而main cache里又分为probation(LRU)(试用期) 和 protected(LRU)(受保护的)。(W-TinyLRU 通常包含 两个主要组件:windowCache和mainCache)
工作流程:
- 当前一个新的item进来时,会先进入我们的windowCache。这里的windowCache比较小,且内存管理就直接使用传统LRU了。
- 若有item从我们的windowCache淘汰出来的话,会尝试进入mainCache
- 能否进入看TinyCache对该item的计数是否 大于 主缓存中频率最低的候选淘汰对象 的 频率计数。可以就进入并,不可以就out
- mainCache整体采用的也是LRU(但是)
- 整体流程呈现一种 先接纳后淘汰的流程
MainCache里的状态流转
W-TinyLFU解决了LRU和LFU什么问题?
- LRU:突发流量污染问题
- LFU:老资历不腾空给 新数据

1 | //淘汰节点 |
W-TinyLFU 的精髓是 位计数法
如何一个高性能的本地缓存组件,caffeine在拼多多高并发业务场景下性能还是不行
改进缺点
- 给不同key设置不同的过期时间,API不够好
1 | public void put(K key, V value, Duration timeout) { |
2.