orderby
orderby是做排序的,它排序方式有两种,一种是索引排序,一种是filesorted(我们可以在extra中看到提示:using filedsorted),但具体哪种还得看优化器来抉择,而且确定性也不是很强。
在filedsort排序中,如果排序的内容比较少,就会直接内存的sort_buffer进行排序,否则就得使用临时文件了
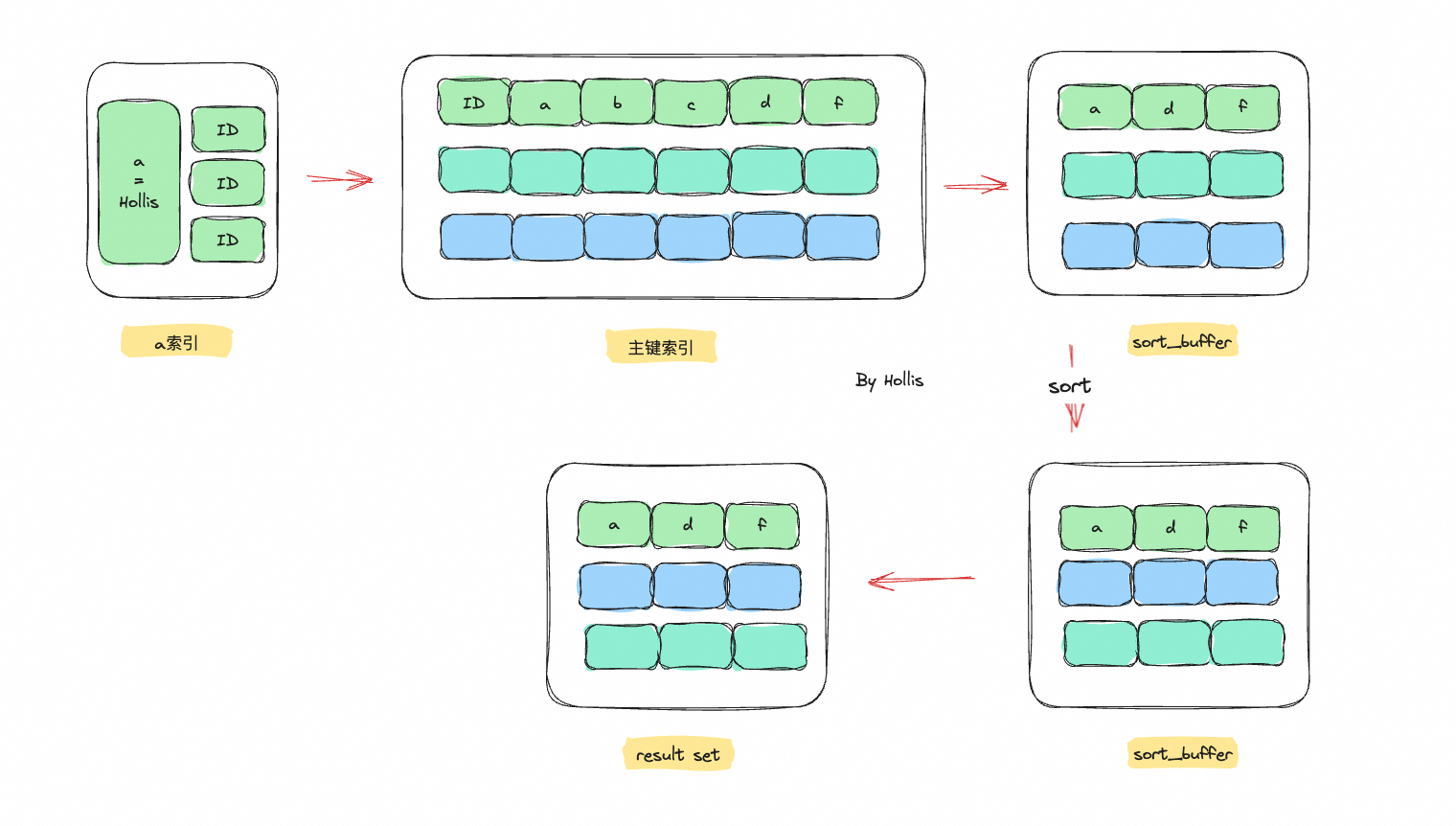
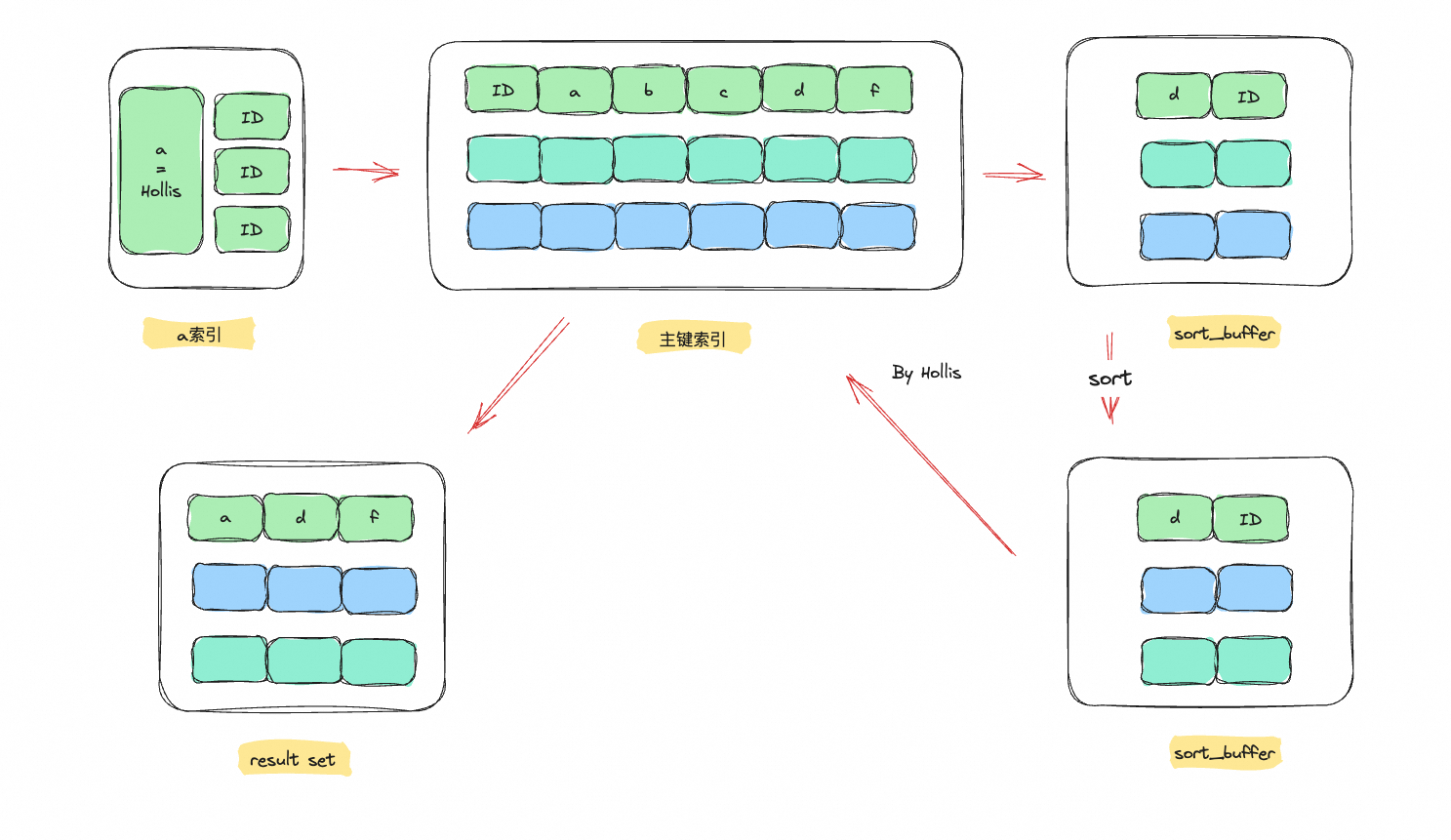
。且当在sort_buffer排序时,如果排序的字段并不是很长的话,就会使用全字段排序的方式直接在sort_buffer里排好序后返回结果集。但如果字段特别长,就会基于空间考虑,采用(隐藏ID)row_id进行排序,然后回表查询后返回结果集
ps:字段长度指的是 **参与排序的字段 + SELECT 返回的字段的总长度 **
索引排序
索引天然有序的,那么借助索引进行排序自然是最高效的。但这个过程中,是否真的用索引,完全取决于优化
器的选择。查询优化器会根据成本评估来进行选择是否通过索引进行排序
我平时开发比较好奇,就有去测到底哪一种情况最容易做索引排序
1.用到了索引覆盖且遵循最左匹配原则
2.查询条件中有limit,且limit的Size不高,像之前测的时候我80万数据的表,limit超过2w就不会走了
3.用到了索引跳跃机制
filesort排序
前面我们知道,filesort 如何排序的内容不多时,会直接在内存的sort_buffer里面排,多的话就基于临时文件
排序了。这种行为是由sort_buffer_size即sort_buffer的大小所决定的。排序的数据量小就在内存,大就在文
件。
filesort是如何进行排序的?
基于归并排序的算法,把排序的数据拆分成多个临时文件,然后进行一个merge返回给客户端
这里还有一个影响排序算法的重要参数,即max_length_for_size_data,是MySQL中用于控制 用于排序的行数的长度一个字段,默认为1024bit。如果单行的长度大于这个值,就会进行rowId 排序,否则就进行全字段排序
全字段排序
实例SQL
1 | select a,d,f from t2 where a = "Hollis" order by d; |
row Id 排序
如何选择排序算法
速度>内存>一次回表
如何优化using fileSorted
- 尽量使用索引进行排序
- 通过sort_buffer_size和max_length_for_size_data进行调优