explain
对select,update,delete(后两个是告诉你他是怎么查找数据的)。对insert无效的
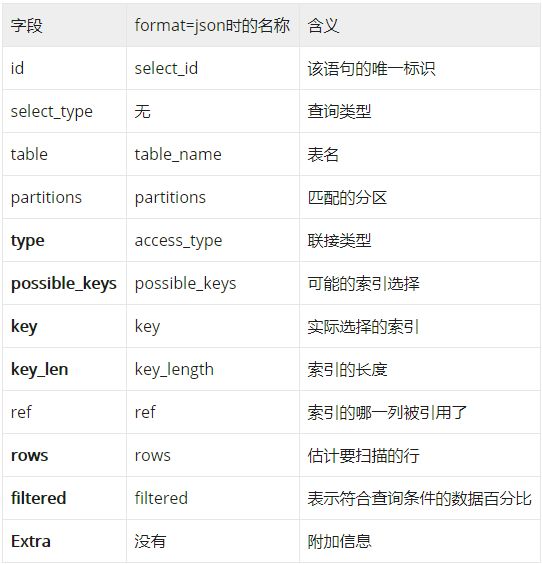
id:
表示单一SQL的执行顺序,该语句的唯一标识。如果explain的结果包括多个id值,则数字越大越先执行;而
对于相同id的行,则表示从上往下依次执行
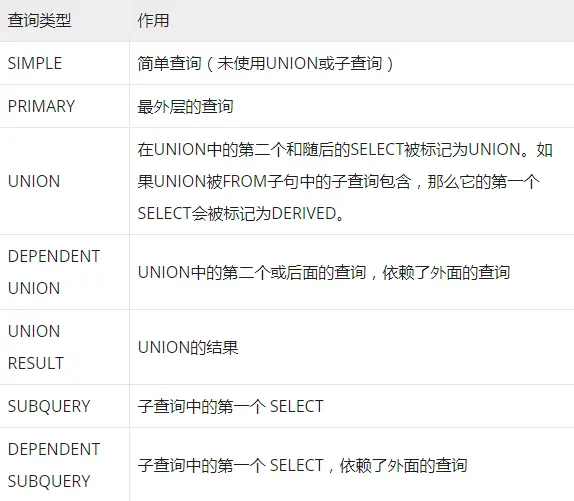
select_type
table
表示当前sql作用的表名
type
- system:系统表,少量数据,往往不需要进行磁盘IO
- const:使用常数索引,MySQL 只会在查询时使用常数值进行匹配。
explain select * from t2 where f='Hollis';- 使用唯一性索引做唯一查询
- eq_ref:唯一索引扫描,只会扫描索引树中的一个匹配行。
explain select * from t1 join t2 on t1.id = t2.id where t1.f1 = 's';- 当在连接操作中使用了唯一索引或主键索引,并且连接条件是基于这些索引的等值条件时,MySQL通常会选择 eq_ref 连接类型,以提高查询性能。
- ref:非唯一索引扫描, 只会扫描索引树中的一部分来查找匹配的行。
explain select * from t2 where a = 'Hollis';- 使用非唯一索引进行查询
- range:范围扫描, 只会扫描索引树中的一个范围来查找匹配的行。
explain select * from t2 where a > 'a' and a < 'c';- 使用索引进行性范围查询
- index:全索引扫描, 会遍历索引树来查找匹配的行
explain select c from t2 where b = 's';- 不符合最左前缀匹配的查询
- ALL:全表扫描, 将遍历全表来找到匹配的行。
explain select * from t2 where d = "ni";- 使用非索引字段查询
需要注意的是,这里的index表示的是做了索引树扫描,效率并不高。以上类型由快到慢:
system> const > eq_ref >**ref>range> index **>ALL
possible_keys
展示当前查询可以使用哪些索引,这一列的数据是在优化过程的早期创建的,因此有些索引可能对于后续优化过程是没用的。
key
表示MySQL实际选择的索引
key_len
索引使用的字节数。由于存储格式,当字段允许为NULL时,key_len比不允许为空时大1字节。
filtered
表示符合查询条件的数据占全部数据的百分比,最大100,越高则越好
rows
mysql估算会扫描的行数,越小越好
extra(额外信息)
Using filesort:当Query 中包含 ORDER BY 操作,而且无法利用索引完成排序操作的时候,MySQL Query Optimizer 不得不选择相应的排序算法来实现。数据较少时从内存排序,否则从磁盘排序。Using tempporary:在对MySQL查询结果进行排序时,使用了临时表,这样的查询效率是比外部排序更低的,常见于order by和group by。
Using index:使用了索引覆盖
Using where:使用了where进行过滤,即使用到了索引,如果没有索引,说明是去聚集索引全盘扫描,说明
没用到where进行过滤,只用where进行判断
Using index condition:使用了索引下推
Using MRR:使用了Multi-Range Read优化
Using join buffer:使用了连接缓存,比如说在查询的时候,多表join的次数非常多,那么将配置文件中的缓
冲区的join buffer调大一些
Distinct:查找distinct值,当找到第一个匹配的行后,就不再搜索了