MVCC
全称就是 多版本并发控制,是MySQL用来解决读写冲突的一种手段,可以实现读写不阻塞。
存在于读已提交和可重复读的情况下,读未提交不需要加锁直接读最新数据,而串行化普通select都给你加锁
MVCC依赖什么实现的?
1.数据库的隐藏字段:
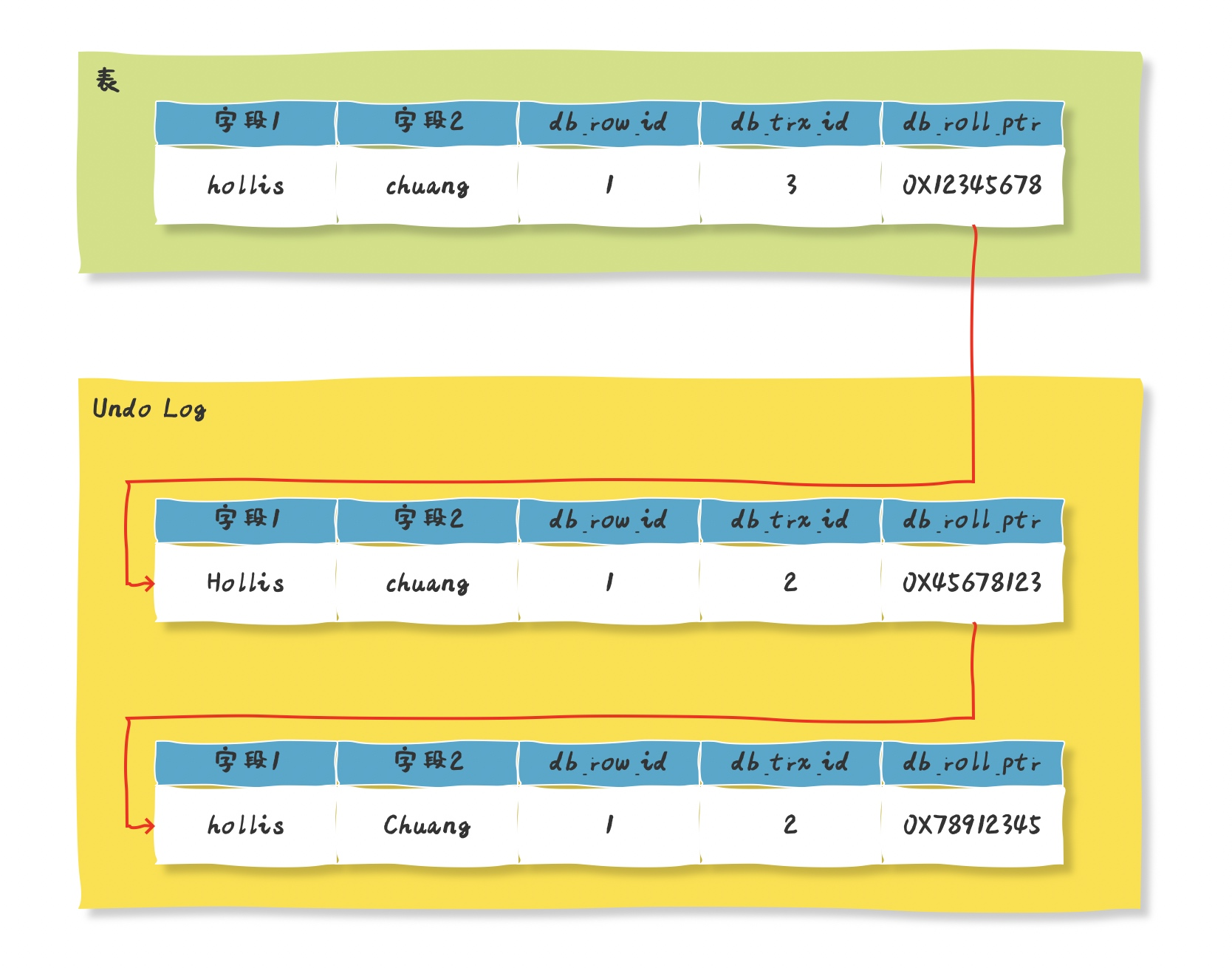
rollback_pointer 回滚指针
trx_id:最近修改该行数据的事务ID
2.undo log版本链:记录的是事务变更前的数据
3.readView:快照读情况下生成的一个读视图,生成的一个快照,用来解决数据的可见性问题,有以下
字段
trx_ids:生成readview时当前系统还获活跃的事务ID集合
low_limit_id:应该分配给下一个事务的ID
up_limit_id:没提交事务中的最小ID
creator_trx_id:创建该read view的事务ID
ps: trx_ids=[up_limit_id,low_limit_id)

MVCC是如何判断数据的可见性的?
1.首先先判断本条数据是否由本事务产生(trx_id=creator_trx_id),如果是,那么就一定是可见,毕
竟是自己产生的
2.再判断**本条数据**的事务ID是否小于没提交事务的最小ID,如果是,那就可见,因为说明这数据已经被
其它事务所提交了,本事务是可见的
3.再判断本条数据是否在活跃事务集合中,如果不在,那么说明该数据已经被其他事务所提交
如果本条数据不存在的话,那么就会根据rollback pointer和undo log去找上一个版本的数据,然后重复
以上判断
readview产生时机
1.可重复读的情况下,只在事务第一次快照读时产生readview,后面会复用这个快照如果事务启动时选择
了with consistent snapshot,事务启动时就建立快照
2.读已提交的情况下,每次快照读都产生新的readview
二级索引在索引覆盖时如何使用MVCC?
隐藏字段在聚簇索引上,所以二级索引不回表要怎么使用MVCC?二级索引中,用了一个额外的名
page_max_trx_id来表示修改过该页的最大事务ID,然后用readview里的up_limit_id即没提交的事务中的
最小ID去和它比对,发现比它大,那么说明该页的数据是可见的。如果不可见,就需要回表。
所以我们可以得出一个结论,即使用到了索引覆盖,也不一定不回表