为什么mysql索引结构要采用b+树
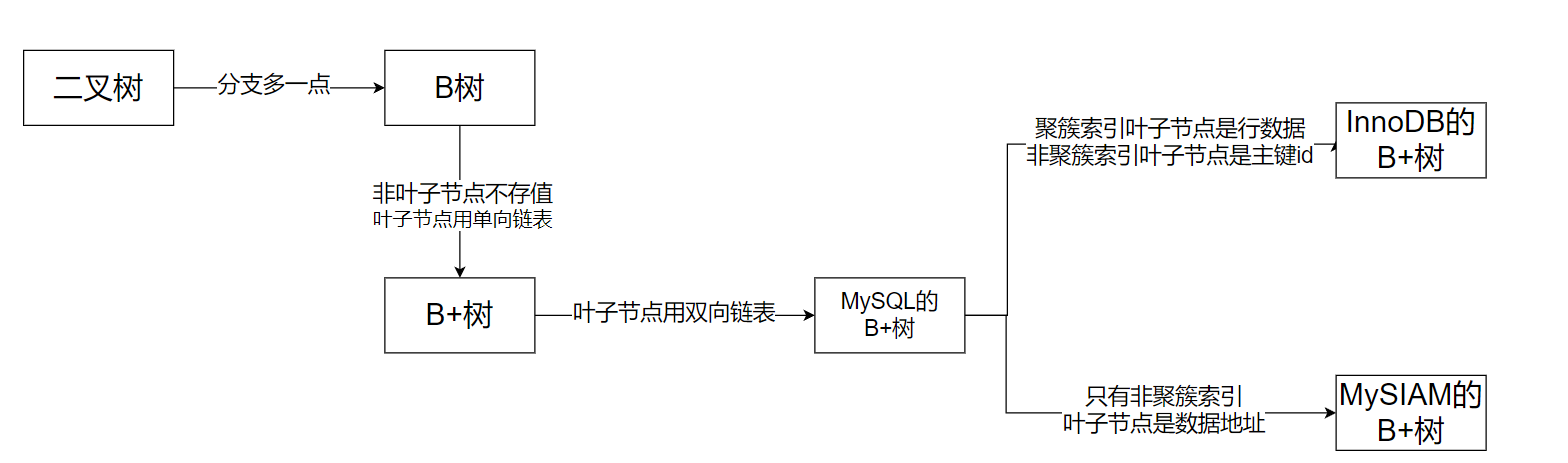
首先我们要明白采用它的目的,一定就是要时间复杂度尽可能地小,支持范围查询。前者无非就是树,跳表,Hash表。而hash索引不支持范围查询
为什么不用Hash?
不支持范围查询
为什么不用跳表?
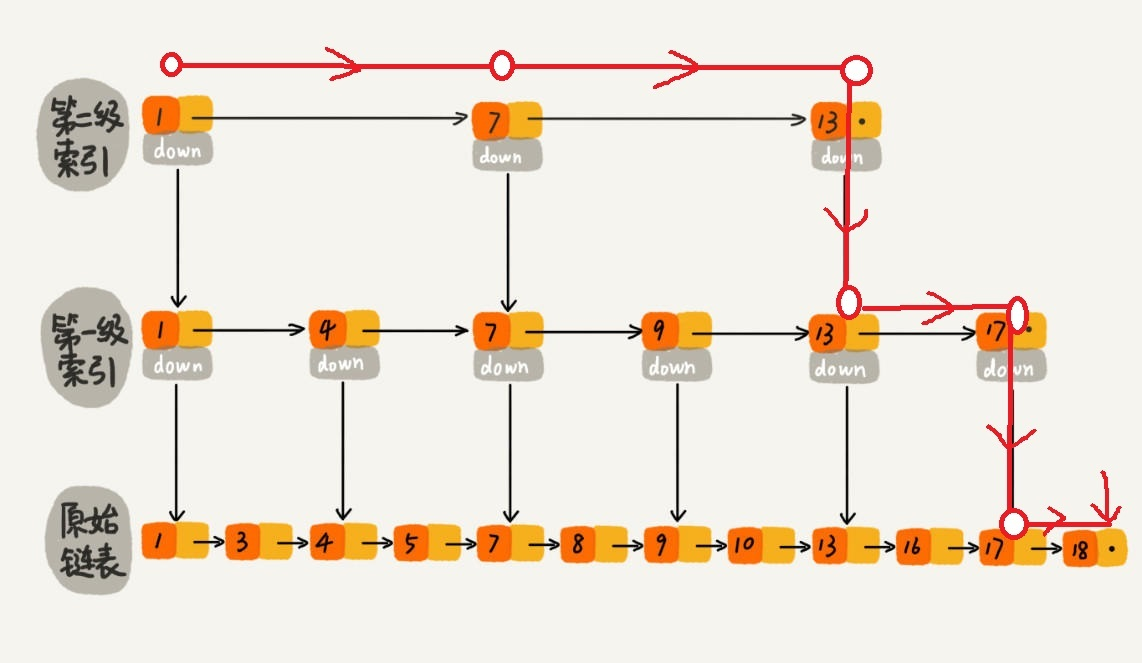
跳表是内存友好型,而b+树是磁盘友好型。b+树一般在磁盘里寻址三次足以,每次都会读取一个数据页,然
后在数据页进行二分查找
而跳表每次读取一个数据页节点都需要跳跃,而链表又是几万个节点,虽然是logn,但寻址次数明显是要比
b+树多,因为b+树的二分查找主要是在数据页中(已经读到内存中了,InnoDB是读到bufferpool,myisam
是读到 page cache),而跳表的二分查找就是在链表中,即磁盘中,而且索引之间的物理距离可能比较长
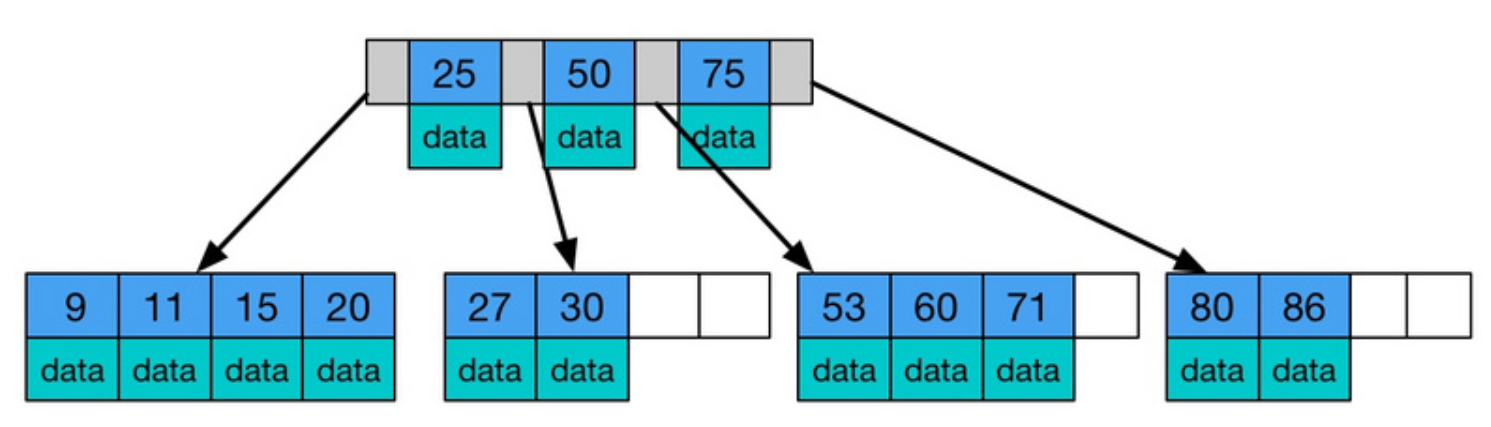
为什么不用b树?
b树的非叶子节点的v也会存数据,这导致一个页中存储的kv值会减少(因为一个页的大小是固定的),指针
就会表少,要同样保存大量数据,就得去增加树高,导致其性能降低。然后就是叶子节点之间是没有指针相连
的,对范围查询不是很友好,且叶子节点之间是无指针相连的,对范围查询不是很友好
为什么不用二叉树/红黑树?
二叉树层级过高,搜索效率偏低,百万数据约为20层