ConcurrentHashMap
吊打Java面试官之ConcurrentHashMap(线程安全的哈希表)
jdk1.7
concurrentHashMap里存了一个segement数组,然后一个segement元素类似于一个HashTable。当put元素
时,然后根据Hash值定位到某个segement里,然后对segement加一个ReentrantLock就好了,这也保证了
不同segement之间可以并发操作。
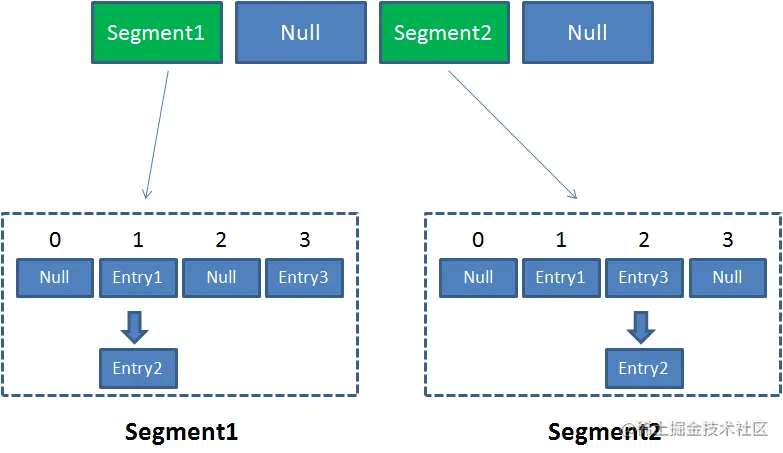
无参构造初始化后
- concurrencyLevel(最大并发级别,即决定segement数组的容量)默认为16,一旦初始化后不可扩容
2.初始化segement[i](HashEntry数组)为2,负载因子为0.75,扩容阀值是 2*0.75=1.5,即插入第二个值
后才会触发扩容,扩容一次 size*2
3.插入元素时才会初始segement[cur],其他的都还是null。如果这时候segement[i]扩容到了4,那么其他
segement也会参照segement[cur]进行初始化
4.segementshift 和 segementmask 用来定位元素在哪个segement位置

put流程
1.为输入的key做Hash运算,得到其Hash值
2.通过Hash值,定位到在segement数组的位置
3.获取ReentrantLock
4.再次Hash运算,得到在segement元素内部的位置
5.覆盖or插入HashEntry对象
6.释放ReentrantLock
get(无锁)
为输入的key做Hash运算,得到Hash值
根据Hash值定位到segement对象
再进行一次Hash
定位到segement数组里的具体位置
为什么get()不需要上锁,因为Node节点里的val和next都用到了volatile
jdk1.8
concurrentHashMap采用了Node数组来存元素,并基于CAS+synchronized来保证线程安全
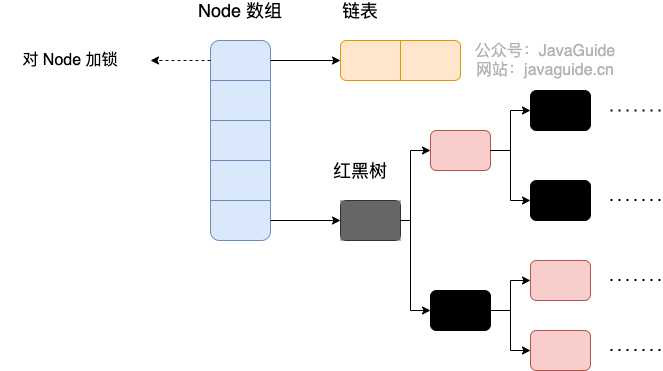
初始化
懒汉式初始化桶元素(new的时候,Node[]还是null,HashMap也是)
负载因子默认为0.75。它这里有个有趣的点,即使让构造时用户手动指定了负载因子,后续扩容还是会
按0.75来进行扩容(HashMap就不是,会按照用户设置好的负载因子进行扩容)
capacity表示你想往里存放的元素个数,但实际它在初始化时会将其变成2的幂,比如你cap=18,它会变
成32,这也是跟HashMap一样
get():无锁,因为Node[]和Node里的next和value都有volatile修饰,保证读取到的都是最新的值
initTable(): CAS保证只有一个线程初始化成功,涉及到volatile 修饰的sizeCtl。如果有线程初始化成功就会把
它设置为-1,下一个线程发现<0时,说明已经有线程进行初始化了。就会进行Thread.yield() 即让出CPU使
用权

put()
1.检查key和value不能为null
2.进入死循环
3.如果是第一次put,则初始化Table,并用cas保证线程安全,然后重新进入死循环
4.如果头节点为null,则通过CAS将当前值设置为头节点,成功就直接break,失败就重新进入死循环
5.如果头节点为ForwardingNode,说明此时当前桶在扩容,则当前线程需要去协助扩容,扩容完成后
重新进入循环
6.到了这里说明要往当前槽位的链表or红黑树里加元素了,此时使用synchronized对头结点进行上锁操作
a.再次判断头节点是否被移动
如果此时是链表,则走链表的更新逻辑
如果是红黑树,就走红黑树的更新逻辑
b.释放锁,判断是否需要树化,然后break
7.执行addCount方法,addCount(1L, binCount); 更新binCount( 当前桶(bucket)中节点个数 )
扩容
何时扩容?当前元素个数为 数组大小*0.75
整个扩容操作分为两个部分
1.构建一个nextTable,容量为原来的2倍,且这个构建是单线程的
2.把原来Table里的元素复制到新的Table里,这个主要是遍历复制的过程。然后遍历是指会从后往前遍历
原Table,然后通过tableAt(i)获取i位置的元素
a.若tableAt(i)等于null,则会将其标记为ForwardingNode,这是并发协作的基础
b.若tableAt(i)为Node节点(fh>=0),即为链表节点,会将其链表一分为2。然后将其放到
nextTable的i和i+n位置上(n为数组长度)

c.若为TreeBin即红黑树节点,则判断是否需要取消树化,将其放到nextTable的i和i+n位置
d.遍历所有元素完成复制,并将nextTable做为新的Table,把sizeCtl赋值为新容量的0.75,至此完
成扩容
ps:sizeCtl是什么?(CTL: Control )

size()
counterCells:每个槽位里的桶数量,会在高并发时被初始化出来,且高并发场景下size的部分逻辑就会
走counterCells


为什么HashMap的key和value可以是null?
containsKey(key):先根据key获取Node,再判断Node是否为null。可以解决key为null的歧义问题
单线程的情况下,不如出现二义性
为什么concurrentHashMap的key和value不可以是null?
在多线程的情况下,会有二义性。
二义性:
get(key)后发现value=null,存在两种情况,一种不存在,一种value为null。但此时你要
containsKey(key)时,有线程把key删了,让你误认为key是不存在,而不是只是value为null
如果想要解决它,其实是可以解决的。两个方法
1.get()方法加锁,保证没有人来删,但费性能
2.value直接不能为null,简单暴力,concurrentHashMap就是采用此方法
当你的value不为null时,key为null,完全是可以通过containsKeys来解决二义性的
那为什么concurrentHashMap还要把key设置为null呢??
ConcurrentHashMap作者 道林认为往Map里塞key为null,显然就是一件奇怪的事。这
也是他HashMap作者的分歧。因为道林他认为key中存在null是存在风险的,而且直接让key不为null可以
在代码层面少去很多判空逻辑
为什么jdk1.8concurrentHashMap要采用synchronized,而不是ReentrantLock
ReentrantLock是对象锁吧,占的空间是要比synchronized大的。