redis的常用以及底层数据结构
四种基本:string hash list set
五种特殊:zset geo hyperloglog stream bitmaps
底层
sds
dict
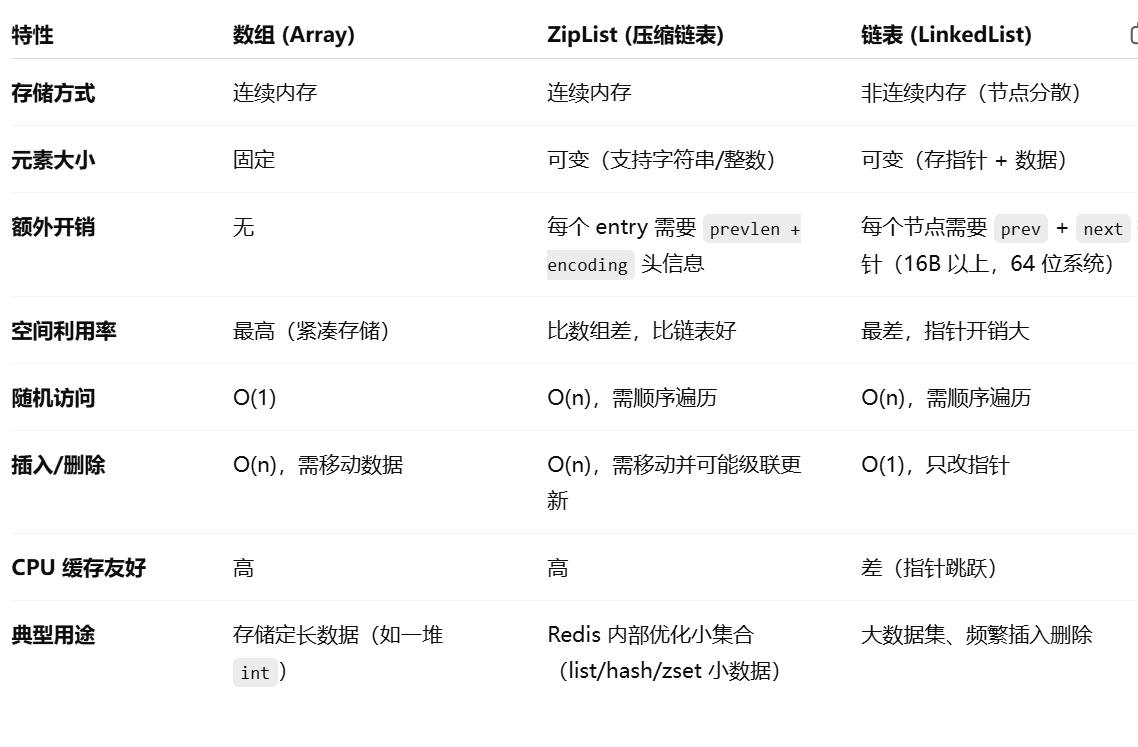
ziplist
quicklist
skiplist
SDS
c语言string的增强版
- 常数获取字符串长度
- 杜绝缓冲区溢出
- 内存预分配
- 二进制安全,可存/0
string存的最大:521m
intset
dict
ziplist
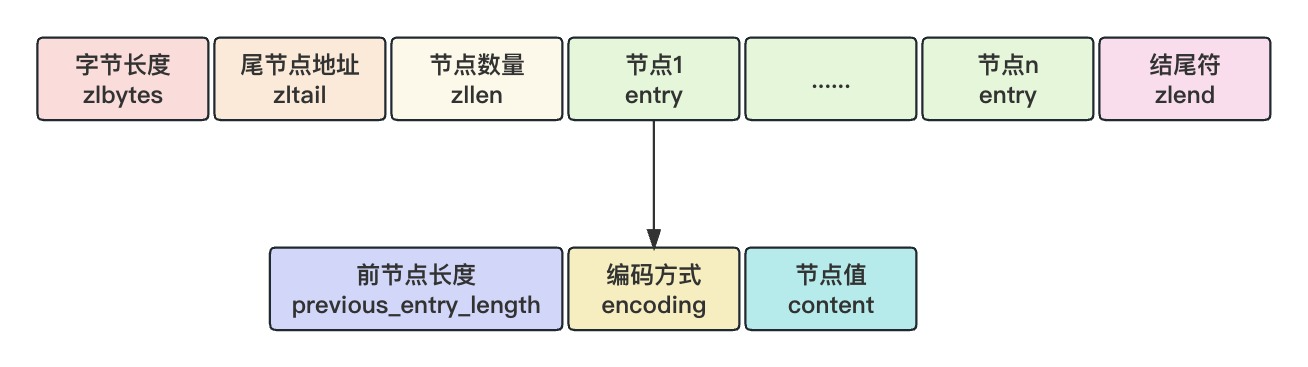
压缩链表。连续的内存空间,类似于数组
每个节点都存有前一个节点的长度,用于从后往前遍历,存有当前节点长度和类型,用于从前往后遍历。
这样更能节省内存
但会出现级联更新的问题
ziplist如何实现有序性的
插入时保证有序 O(N)
- 插入时二分查找判断插入节点的位置
- 移动数组
补充:在 Redis7.0 中,压缩列表数据结构已经废弃了,交由 listpack 数据结构来实现了
ListPack
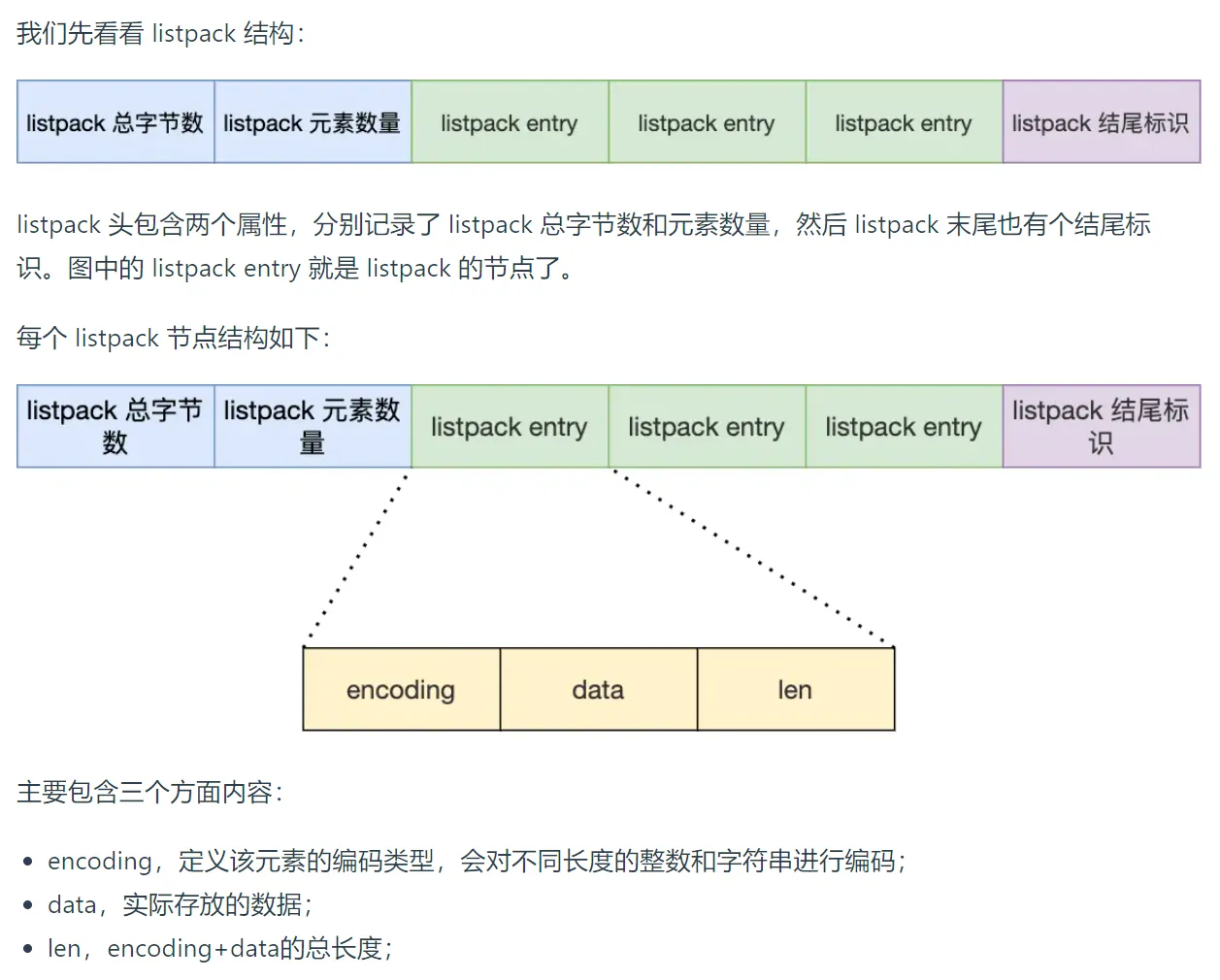
ListPack可看做是ziplist的升级,它每个元素没有存储前一个元素的长度,但同样支持反序遍历

skiplist
跳表,可实现log(n)查询,即多级索引的链表
思想就是空间换思想,用多级索引去减少检索的路径
为什么zset要基于skiplist实现
首先要明确zset是干什么的?无非就是有序,支持范围查询
那么像这样的数据结构,其实有很多种,数组,列表,多路搜索树Or二叉树
但数组和树结构这种,它增加元素肯定会引发那个数据结构的调整。这种对于追求性能的redis的来说,在内存操作时多余的( CPU 操作才是瓶颈,结构复杂就显得多余,浪费性能 )
而对于链表来说,它的查询性能是不行
那怎么优化,无非就是空间换时间,建二级索引,索引建得足够多,那就足够快
跳表就是这个思想
那这时候选择跳表就是一种根据场景权衡利弊出来的选择
- 空间占用小 ListNode<TreeNode
- 支持范围搜索
- 算法实现简单
zset是怎么实现的?
版本
- 3.0:ziplist + skipList
- 4.0:listpack+skiplist
从元素size角度
- 少时:用zipList(listPack)来紧凑存元素,节约空间
- 多时:把ziplist(listPack)里的元素按score 顺序插入 skiplist